Compute
Minimize Overhead, Simplify Maintenance, and Maximize Compute Infrastructure Utilization
One Platform, Endless Use Cases
Join 1,300+ forward-thinking enterprises using ClearML






Open up controlled access to compute resources by abstracting workflow requirements from machines, whether Kubernetes, bare metal, cloud, or a mix

Minimize Overhead and Reduce Cost
Simplify Your AI/ML Infrastructure Stack
Automated Credential Management
Guarantee Availability and Maximize Performance
Fully Utilize Resources / Democratize Access
Simplify Hybrid Models and Maximize Savings
Who We Help
DevOps

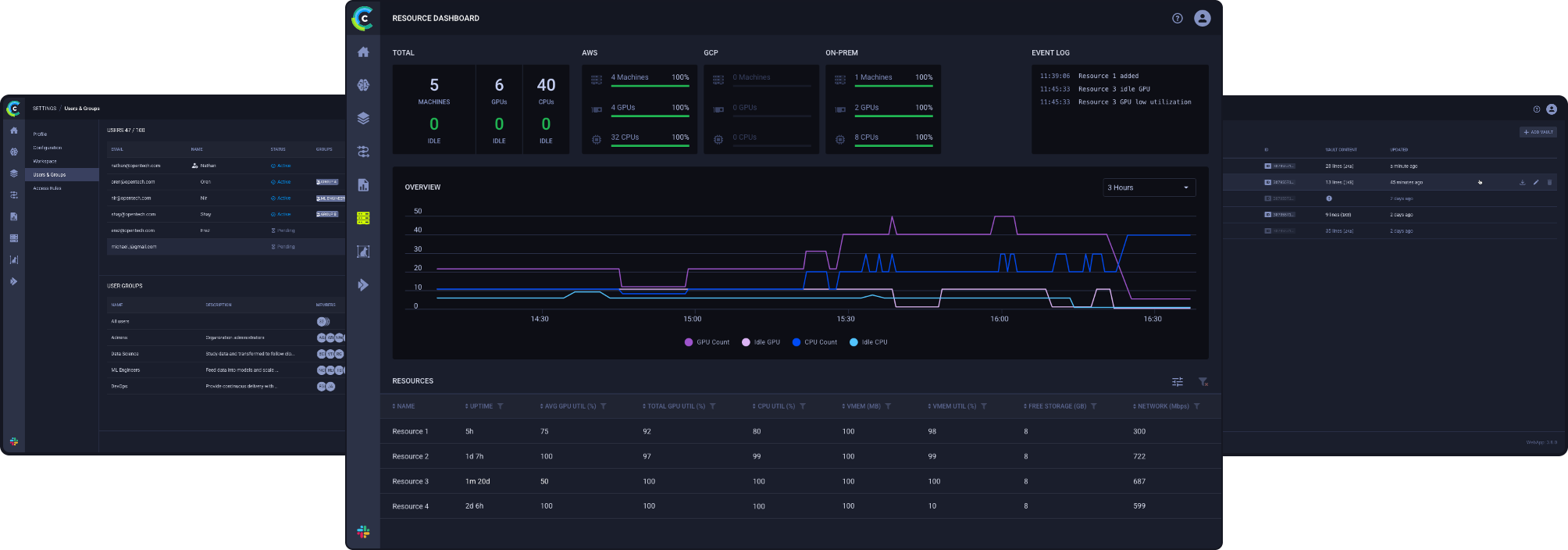
Optimize Compute Utilization with ClearML’s Advanced Functionality
ClearML offers advanced functionality for managing and scheduling GPU compute resources, regardless of whether they are on-premise, in the cloud, or hybrid. Customers can utilize GPUs for maximal usage with minimal costs, resulting in optimized access to their organization’s AI compute – expediting time to market, time to revenue, and time to value.
ClearML offers open source fractional GPU functionality, enabling users to improve their GPU utilization for free, so that DevOps professionals and AI Infrastructure leaders can take advantage of NVIDIA’s time-slicing technology to safely partition their GTX™, RTX™, and datacenter-grade GPUs into smaller fractional GPUs to support multiple AI and HPC workloads, to increase compute utilization without the risk of failure.
We also provide advanced user management for superior regulation, management, and granular control of compute resources allocation, as well as the ability to view all live model endpoints and monitor their data outflows and compute usage.
Integrations
Layer ClearML on top of your existing infrastructure or integrate it with your preferred scheduling tool:

See the ClearML Difference in Action
Explore ClearML's End-to-End Platform for Continuous ML
Easily develop, integrate, ship, and improve AI/ML models at any scale with only 2 lines of code. ClearML delivers a unified, open source platform for continuous AI. Use all of our modules for a complete end-to-end ecosystem, or swap out any module with tools you already have for a custom experience. ClearML is available as a unified platform or a modular offering: