One Platform, Endless Use Cases
Join 1,300+ forward-thinking enterprises using ClearML






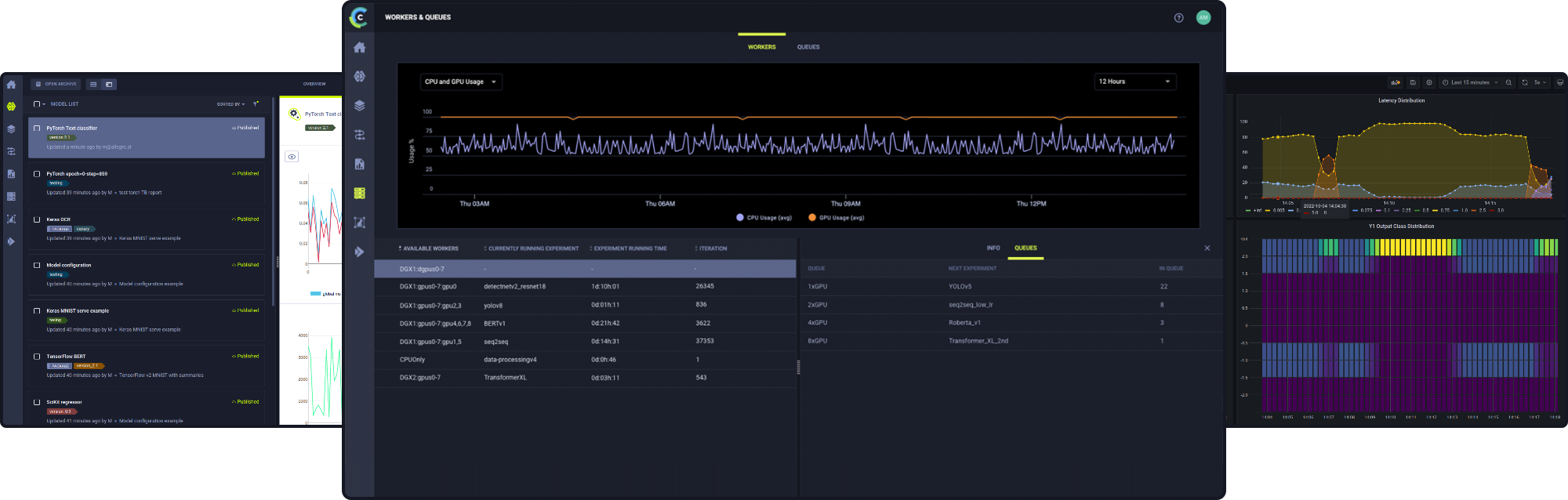
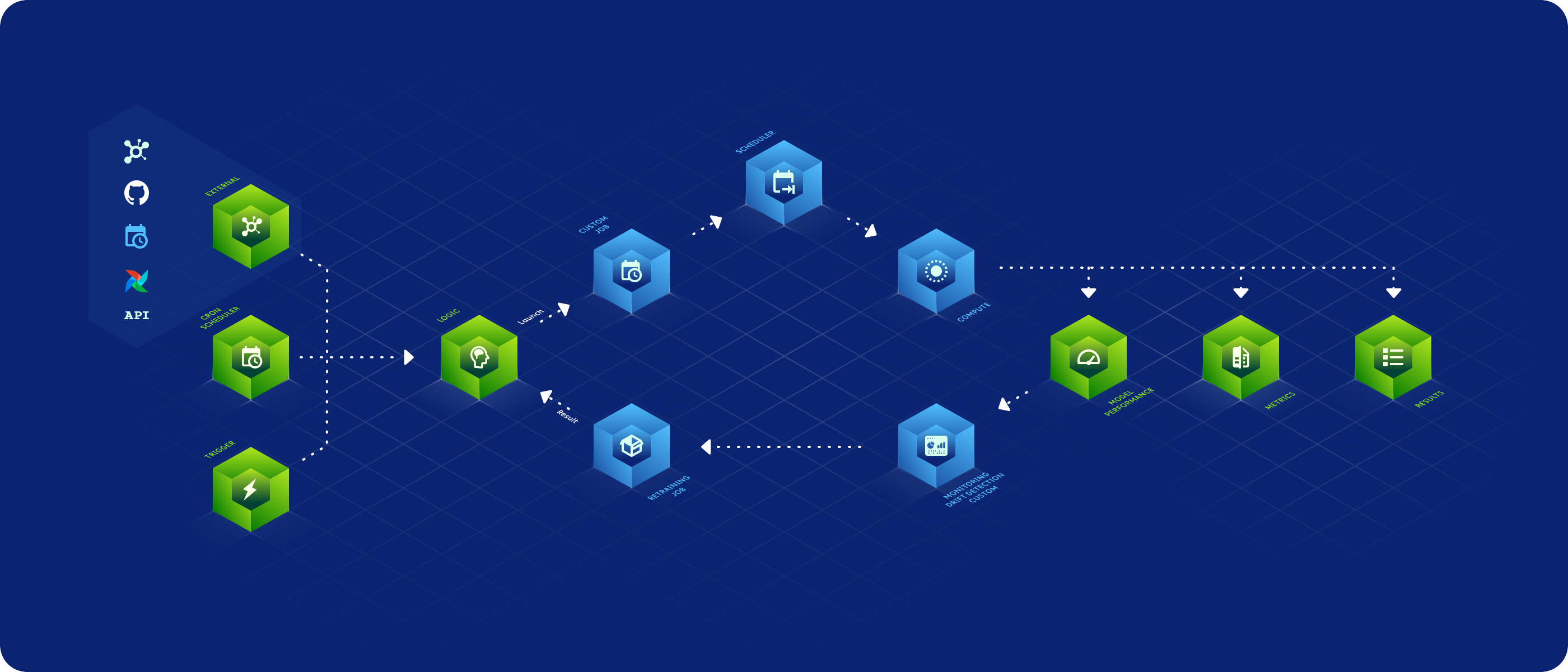
Single-Click Batch Model Deployment On Your Infrastructure
Launch and schedule batch deployment from the UI or integrate into your CI/CD GitOps workflow
Supports on-prem and cloud compute on dynamically autoscaled resources with custom metric monitoring capabilities.
Expose Any Model Via REST API With A Single CLI Command
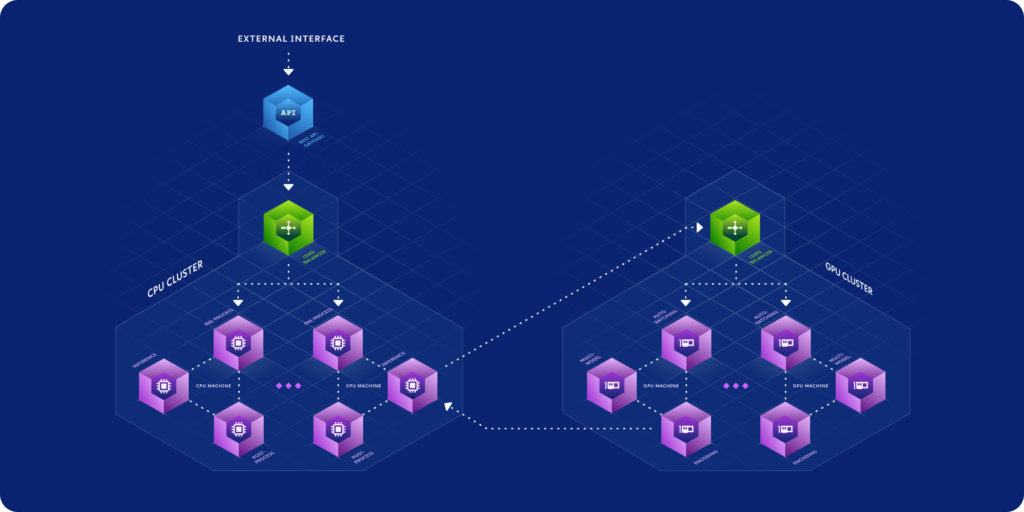
Real-Time Blue/Green Model Deployment Including Canary Support With Enterprise-Grade Scaling
ClearML provides optimized GPU/CPU online model serving with custom preprocessing code on top of Kubernetes clusters or custom container-based solutions
Easy to Deploy
Deploy models from the convenience of your CLI.
Scalable
Horizontally scalable to millions of requests with hundreds of machines/pods serving models.
Enterprise-
ready Security
JWT request authentication with role-based access control
Plug and Play
Connect to your existing dashboards, create customized metrics, get OOTB drift detection and alerts as well as OOTB distribution anomaly detection.
One Platform, Many Stakeholders
ML Engineers
DevOps

Control Your AI/ML Development Lifecycles
Integrations
ClearML works with all your favorite tools and libraries:









See the ClearML Difference in Action
Explore ClearML's End-to-End Platform for Continuous ML
Easily develop, integrate, ship, and improve AI/ML models at any scale with only 2 lines of code. ClearML delivers a unified, open source platform for continuous AI. Use all of our modules for a complete end-to-end ecosystem, or swap out any module with tools you already have for a custom experience. ClearML is available as a unified platform or a modular offering: