A Hero’s Journey to Deep Learning Codebase Series – Part I
By Dan Malowany and Gal Hyams

We all aim to write a maintainable and modular codebase that supports the R&D process from research to production. Key to an efficient and successful deep learning project, this is not an easy feat. That is why we decided to write this blog series — to share our experience from numerous deep learning projects and demonstrate the way to achieve this goal using open source tools.
Our first post in this series is a tutorial on how to leverage the PyTorch ecosystem and Allegro Trains experiments manager to easily write a readable and maintainable computer vision code tailored for your needs. We focus on two packages from the PyTorch ecosystem, Torchvision and Ignite. Torchvision is a popular package consisting of popular datasets wrappers, model architectures, and common image transformations for computer vision. Ignite is a new library that enables simple and clean adding of metrics reports, early-stopping, model checkpointing and other features to your training loop. In this post, we write a codebase that trains and evaluates a Mask-RCNN model on the COCO dataset. We then register the training data (loss, accuracy, etc) to a Pytorch native Tensorboard and use Allegro Trains experiment & autoML manager to manage and track our training experiments. Through these steps, we achieve a seamless, organized, and productive model training flow.
Our Open-Source Resources
The essence of the Ignite framework is its Engine class that loops a given number of times over a dataset and executes a processing function. For example, a training engine loops over the training dataset and updates model parameters. In addition, an Engine has a configurable event system that facilitates interaction on each step of the run: (1) engine is started/completed; (2) epoch is started/completed; (3) iteration is started/completed. Thus, you can execute a custom code as an event handler.
Allegro Trains is an ‘automagical’ experiment & AutoML manager that tracks and controls the training process with code version control, performance metrics, and model provenance. Trains also flexibly performs queues management for workers and enables multiple users to collaborate and manage their experiments.
Let the Code Begin
Please note that in order to run this tutorial, the following open-source packages should be installed: PyTorch, TorchVision, Ignite, TensorBoard, NumPy and Allegro Trains. Visit the following pages for installation:
We start the code with Trains two lines of integration. Adding these two lines of code to any code will initiate Trains Task once you execute it. The project_name parameter will open a dedicated project (if it doesn’t exist) in Trains web app and will register your experiment under the name defined in the task_name parameter.
Every time you will execute your code, Trains will automatically log all your experiment’s info (git repo, commit id, used python packages, argparse parameters, etc) in the created task, which will let you track, reproduce and manage all your experiments (i.e, do science) on the default demo server, or on your own private Trains Server. In addition, registering your argparse parameters to Trains Task can later be used to perform automatic hyperparameter optimization with Trains Agent.
____________________________________________________________________________
from trains import Task
task = Task.init(project_name='Object Detection with Trains, Ignite and Tensorboard',
task_name='Object Detection with Ignite, TensorBoard and TRAINS')
____________________________________________________________________________
Another useful feature Trains has, is the ability to connect the configuration data to the model, so every model registered in the system will include the configuration data that has been used to train it. You can either connect a configuration file or just supply a configuration dictionary. For that purpose, we will also add the following two lines of code, just after the two lines of integration.
____________________________________________________________________________
# Connect the model configuration data to train as well:
configuration_data = {'num_classes': 91, 'lr': 0.005, 'momentum': 0.9, 'weight_decay': 0.0005, 'image_size': 512, 'mask_predictor_hidden_layer': 256}
configuration_data = task.connect_configuration(configuration_data)
____________________________________________________________________________
Data Wrangling
To train a Torchvision model, we set our dataset in a class with a __getitem__ method, which returns the next dataset instance as a tuple of PIL image and a meta-data dictionary. The meta-data dictionary includes the boxes, labels and masks of the ground truth that will be used to train the model on each image. The __getitem__ method ends by performing on the image and meta-data the transformation supplied to the class constructor __init__.
_______________________________________________________________________
class CocoMask(CocoDetection):
def __init__(self, root, annFile, transform=None, target_transform=None, transforms=None, use_mask=True):
super(CocoMask, self).__init__(root, annFile, transforms, target_transform, transform)
self.transforms = transforms
self.use_mask = use_mask
def __getitem__(self, index):
#find the next annotated image
while True:
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
index += 1
if len(ann_ids):
break
path = coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.root, path)).convert('RGB')
# From boxes [x, y, w, h] to [x1, y1, x2, y2]
new_target = {"image_id": torch.as_tensor(target[0]['image_id'], dtype=torch.int64),
"area": torch.as_tensor([obj['area'] for obj in target], dtype=torch.float32),
"iscrowd": torch.as_tensor([obj['iscrowd'] for obj in target], dtype=torch.int64),
"boxes": torch.as_tensor([obj['bbox'][:2] + list(map(add, obj['bbox'][:2], obj['bbox'][2:]))
for obj in target], dtype=torch.float32),
"labels": torch.as_tensor([obj['category_id'] for obj in target], dtype=torch.int64)}
if self.use_mask:
mask = []
for i in range(len(target)):
mask.append(coco.annToMask(target[i]))
if len(mask) > 1:
mask = np.stack(tuple(mask), axis=0)
new_target["masks"] = torch.as_tensor(mask, dtype=torch.uint8)
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
_______________________________________________________________________
Once the data is wrapped in a class with a __getitem__ method, you can construct train validation sets as PyTorch datasets and initiate the corresponding DataLoader. The DataLoader class basically provides an efficient iterator that loads and prepares the data using the CPU, while the GPU runs the deep-learning model. This class provides user control over common deep learning data loading attributes such as batch-size, shuffle, and so on. Note that in addition to the loader, the following function returns ‘label enumeration’ as well. It is a dictionary, connecting the label names to their numerical ids which will be used at a later stage.
_______________________________________________________________________
def get_data_loaders(train_ann_file, test_ann_file, batch_size, test_size, image_size, use_mask):
#create PyTorch dataset objects, for the train and validation data.
dataset = CocoMask(root=Path.joinpath(Path(train_ann_file).parent.parent,
train_ann_file.split('_')[1].split('.')[0]),
annFile=train_ann_file,
transforms=get_transform(train=True, image_size=image_size),
use_mask=use_mask)
dataset_val= CocoMask(root=Path.joinpath(Path(test_ann_file).parent.parent,
test_ann_file.split('_')[1].split('.')[0]),
annFile=test_ann_file,
transforms=get_transform(train=False, image_size=image_size),
use_mask=use_mask)
labels_enumeration = dataset.coco.cats
indices_test = torch.randperm(len(dataset_val)).tolist()
dataset_val = torch.utils.data.Subset(dataset_val, indices_test[:test_size])
# set train and validation data-loaders
train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=6,
collate_fn=utils.collate_fn, pin_memory=True)
val_loader = DataLoader(dataset_val, batch_size=batch_size, shuffle=False, num_workers=6,
collate_fn=utils.collate_fn, pin_memory=True)
return train_loader, val_loader, labels_enumeration
_______________________________________________________________________
Create Torch-Ignite Engines
After finishing the dataset preparation, we train the MaskRCNN model in the following ‘run’ method. First, set the model for the task (as a GPU model — if this option is available on the machine). In the case that you are continuing from a previous training scheme, load the pre-trained model weights. Then the DataLoader, as defined in the previous code snippet, are set.
As TensorBoard is native to Pytorch now, you can easily import and set TensorBoard SummaryWriter to log all your reports. In addition, all your TensorBoard reports will be automatically registered in Trains Server so you will be able to monitor and control in real-time all your experiments. Just set the Tensorboard Summary Writer and add reports of scalars and images in the relevant engine events handlers.
Lastly, create Ignite trainer and evaluator engines and run the trainer engine.
_______________________________________________________________________
def run(task_args):
num_classes = configuration_data.get('num_classes')
# Set the training device to GPU if available - if not set to CPU
device = torch.cuda.current_device() if torch.cuda.is_available() else torch.device('cpu')
torch.backends.cudnn.benchmark = True if torch.cuda.is_available() else False # optimization for fixed input size
model = get_model_instance_segmentation(num_classes, configuration_data.get('mask_predictor_hidden_layer'))
# if there is more than one GPU, parallelize the model
if torch.cuda.device_count() > 1:
print("{} GPUs were detected - we will use all of them".format(torch.cuda.device_count()))
model = torch.nn.DataParallel(model)
# copy the model to each device
model.to(device)
# Define train and test datasets
iou_types = get_iou_types(model)
use_mask = True if "segm" in iou_types else False
train_loader, val_loader, labels_enum = get_data_loaders(task_args.train_dataset_ann_file,
task_args.val_dataset_ann_file,
task_args.batch_size,
task_args.test_size,
configuration_data.get('image_size'),
use_mask)
# we leave it as a software exercise to the reader to set val_dataset as a generator instead of loading all of the data to the memory at once. Hint: look at the CocoEvaluator Class and see how it consumes its data.
val_dataset = list(chain.from_iterable(zip(*batch) for batch in iter(val_loader)))
coco_api_val_dataset = convert_to_coco_api(val_dataset)
if task_args.input_checkpoint:
print('Loading model checkpoint from '.format(task_args.input_checkpoint))
input_checkpoint = torch.load(task_args.input_checkpoint, map_location=torch.device(device))
model.load_state_dict(input_checkpoint['model'])
writer = SummaryWriter(log_dir=task_args.log_dir)
trainer = create_trainer(model, device)
evaluator = create_evaluator(model, device)
# Here we will later define the engines events handlers
trainer.run(train_loader, max_epochs=task_args.epochs)
_______________________________________________________________________
Let’s dive for a moment to how Ignite’s training Engine looks like from the inside. Each engine has an update function, which updates the model based on the given data batch. It forward passes the data to compute losses, then updates the model weights by backprop and lastly, returns the input data, ground truth and loss dictionary.
_______________________________________________________________________
def create_trainer(model, device):
def update_model(engine, batch):
images, targets = copy.deepcopy(batch)
images_model, targets_model = prepare_batch(batch, device=device)
loss_dict = model(images_model, targets_model)
losses = sum(loss for loss in loss_dict.values())
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = utils.reduce_dict(loss_dict)
losses_reduced = sum(loss for loss in loss_dict_reduced.values())
loss_value = losses_reduced.item()
# update the model weights
engine.state.optimizer.zero_grad()
# if the loss is infinite, the use have to know about it
if not math.isfinite(loss_value):
print("Loss is {}, resetting loss and skipping training iteration".format(loss_value))
print('Loss values were: ', loss_dict_reduced)
print('Input labels were: ', [target['labels'] for target in targets])
print('Input boxes were: ', [target['boxes'] for target in targets])
loss_dict_reduced = {k: torch.tensor(0) for k, v in loss_dict_reduced.items()}
else:
losses.backward()
engine.state.optimizer.step()
if engine.state.warmup_scheduler is not None:
engine.state.warmup_scheduler.step()
return images, targets, loss_dict_reduced
return Engine(update_model)
_______________________________________________________________________
Define Ignite Handlers
Once the engine has been defined, you can release the power of Ignite’s event handlers. Each engine has Ignite handler attached to that can perform a given function once the event occur. The definition of the function is done by adding a decorator to the function stating the relevant engine and event, in our case the engines are trainer and evaluator.
Note that the handlers have to be familiar with their engine. Setting the events as nested functions of the function in which the engines are defined, is just one straightforward implementation of that requirement. Included below are handlers we found interesting. You can find more in the code.
The first handler to discuss is on-training-started. In this handler, executed at the beginning of the training process, the model optimizer and learning rate are set.
_______________________________________________________________________
@trainer.on(Events.STARTED)
def on_training_started(engine):
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
engine.state.optimizer = torch.optim.SGD(params,
lr=configuration_data.get('lr'),
momentum=configuration_data.get('momentum'),
weight_decay=configuration_data.get('weight_decay'))
engine.state.scheduler = torch.optim.lr_scheduler.StepLR(engine.state.optimizer, step_size=3, gamma=0.1)
if task_args.input_checkpoint and task_args.load_optimizer:
engine.state.optimizer.load_state_dict(input_checkpoint['optimizer'])
engine.state.scheduler.load_state_dict(input_checkpoint['lr_scheduler'])
_______________________________________________________________________
The on-epoch-completed handler registers the epoch average precision scalar to TensorBoard, which makes it available to view on the Trains-Server webapp. Then, it saves the model checkpoint, which Trains auto-magically connect as the Trains-task output model.
_______________________________________________________________________
@trainer.on(Events.EPOCH_COMPLETED)
def on_epoch_completed(engine):
engine.state.scheduler.step()
evaluator.run(val_loader)
for res_type in evaluator.state.coco_evaluator.iou_types:
average_precision_05 = evaluator.state.coco_evaluator.coco_eval[res_type].stats[1]
writer.add_scalar("validation-{}/average precision @0.5".format(res_type), average_precision_05,
engine.state.iteration)
checkpoint_path = os.path.join(task_args.output_dir, 'model_epoch_{}.pth'.format(engine.state.epoch))
print('Saving model checkpoint')
checkpoint = {
'model': model.state_dict(),
'optimizer': engine.state.optimizer.state_dict(),
'lr_scheduler': engine.state.scheduler.state_dict(),
'epoch': engine.state.epoch,
'args': args,
'labels_enumeration': labels_enum}
utils.save_on_master(checkpoint, checkpoint_path)
print('Model checkpoint from epoch {} was saved at {}'.format(engine.state.epoch, checkpoint_path))
evaluator.state = checkpoint = None
_______________________________________________________________________
The following handle is an example of evaluation-time one. It calculates and registers debug-images to TensorBoard, which can be viewed on the Trains-Server – similarly to TensorBoard scalars. This lets the user closely monitor the progressing model performance.
_______________________________________________________________________
@evaluator.on(Events.ITERATION_COMPLETED)
def on_eval_iteration_completed(engine):
images, targets, results = engine.state.output
if engine.state.iteration % task_args.log_interval == 0:
print("Evaluation: Iteration: {}".format(engine.state.iteration))
if engine.state.iteration % task_args.debug_images_interval == 0:
for n, debug_image in enumerate(draw_debug_images(images, targets, results)):
writer.add_image("evaluation/image_{}_{}".format(engine.state.iteration, n),
debug_image, trainer.state.iteration, dataformats='HWC')
if 'masks' in targets[n]:
writer.add_image("evaluation/image_{}_{}_mask".format(engine.state.iteration, n),
draw_mask(targets[n]), trainer.state.iteration, dataformats='HW')
images = targets = results = engine.state.output = None
_______________________________________________________________________
Sit Back, Relax & Monitor Your Experiment
Now that our code base is ready, we can execute the train script, and monitor its progress in Trains webapp. As the statistics and the debug images are logged in Trains, you can view them on your own private Trains Server (or on Trains Demo Server). By viewing the statistics and debug images, you track the training process and make sure that it’s all running as planned. For example, viewing reported debug images can let you know if there is a problem with your ground truth and/or the data augmentations created faulty results.
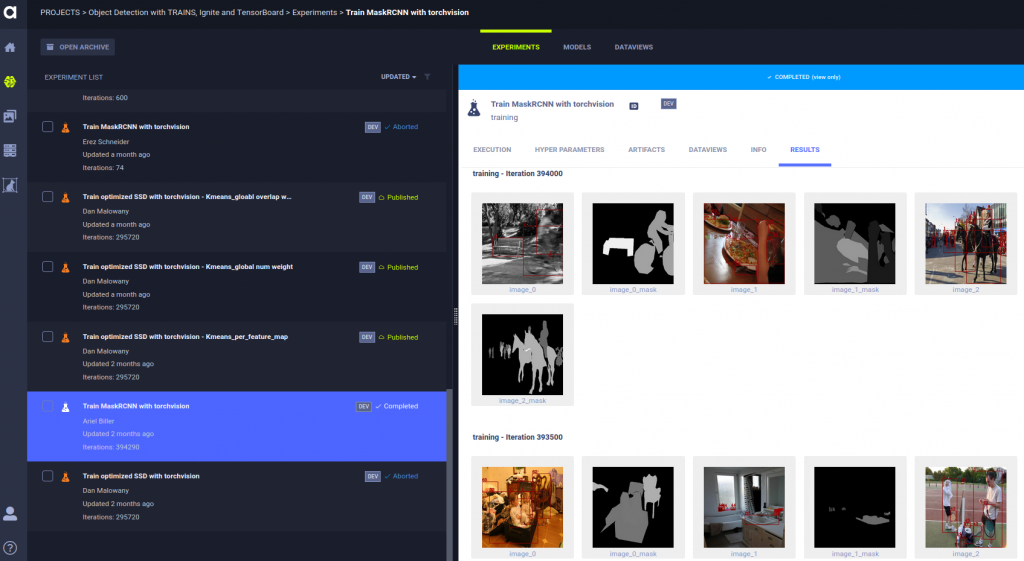
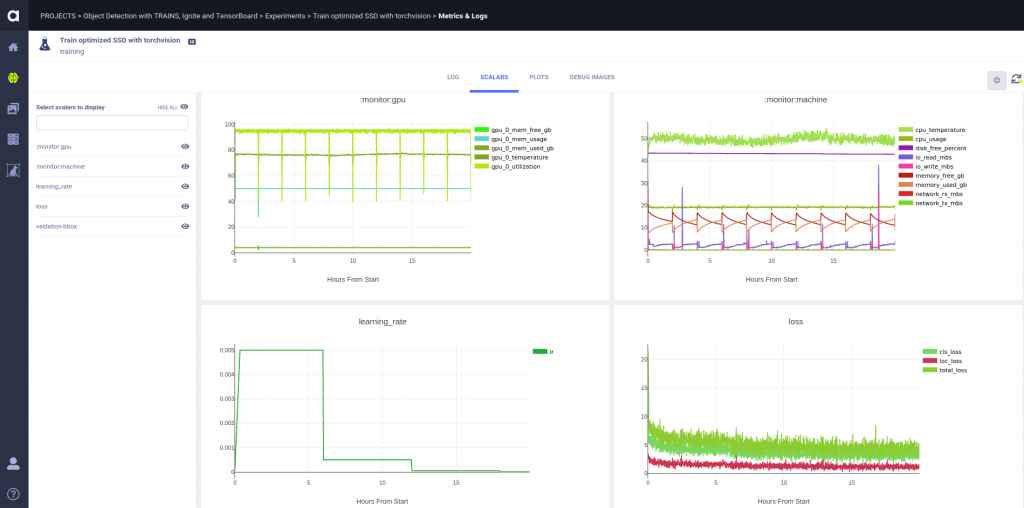
In the above snapshot, you can view list of experiments, which are part of the same project. Clicking on a specific experiments enables us to monitor the predicted masks and bounding boxes in a training cycle. In the snapshot below, you can see the training statistics of the same experiment – in this case, the bounding box and masks’ average precision.
Summary
We hope you’ve enjoyed this tutorial and now have a better handle on how to write readable, maintainable and reproducible deep learning code. Using Ignite and Trains can enable a more simple and productive machine and deep learning workflow. The full code is available here.
Our code base is inspired by PyTorch’s mnist with tensorboardX and Torchvision object detection finetune tutorials.
In our next post in this series, we will show how the modular structure of the codebase we shown here, enables an easy replacement of MaskRCNN with an SSD model. We will explain the differences between a one-shot and a two-shot object detection model and how to set an SSD model on top of TorchVision feature extractor. We will then execute the train & evaluation scripts we just wrote together with you – this time with a single shot detector. Stay tuned!