To ensure a frictionless AI/ML development lifecycle, ClearML recently announced extensive new capabilities for managing, scheduling, and optimizing GPU compute resources. This capability benefits customers regardless of whether their setup is on-premise, in the cloud, or hybrid.
Under ClearML’s Orchestration menu, a new Enterprise Cost Management Center enables customers to better visualize and oversee what is happening in their clusters. The ability to view resource utilization in real time offers teams a better way to manage GPU allocation, queues, job scheduling, and usage, as well as project quotas. With this greater visibility, DevOps can make faster, better decisions that maximize their GPU resource utilization.
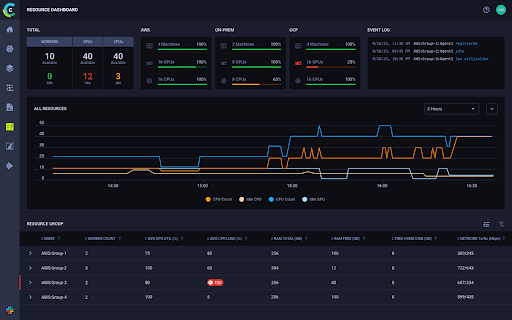
DevOps teams can also ensure GPU resources are fully utilized by allocating GPU fractions, managing oversubscription, consolidating, and more closely managing scheduling and priority. With ClearML, teams have full control over job prioritization as well as job order within queues or quotas through the policy manager. By creating automations to more efficiently manage jobs, the DevOps team gains significant time and energy savings.
For cloud or cloud hybrid setups, ClearML’s Autoscaler and Spillover features allow enterprises to closely manage budgets and costs. When jobs scheduled exceed the existing on-premise GPU resources available, Spillover enables secure usage of cloud compute. The Autoscaler function (which can be used with or without Spillover) automatically provisions machines in the cloud to run the jobs and spins them down once idle, preventing wastage costs. For additional cost control and availability options, teams can set whether the jobs run on regular or spot instances and are not zone limited.
With orchestration and scheduling powering ClearML’s core AI/ML platform, accessing compute resources is simplified for both users and admins. Built with enterprise-grade security in mind, the ClearML platform features role-based access control. When coupled with project-level user credentials, ClearML automatically provisions pre-configured machines for users that need them for data pre-processing, model training or model serving. Model deployment autoscaling is automatic for natively integrated inference servers, with support for both CPU & GPU dedicated nodes. If you do not have an AI/ML platform, or are re-evaluating your toolkit, have a look at the landscape of AI/ML solutions assembled by the AI Infrastructure Alliance.
ClearML also provides transparency and full provenance for model governance. Every event for every cluster is automatically logged for easy auditing. ClearML is fully open source and extensible, and can be installed on the cloud, VM, bare metal, Slurm or Kubernetes. The platform is also hardware-agnostic and cloud-agnostic, allowing enterprises the freedom to choose their own infrastructure vendors and optimize for hybrid on-prem / cloud combinations.

If your company needs to better manage its GPU compute resources to save time, optimize utilization, and power your AI/ML initiatives, request a ClearML demo today.