Large Language Models (LLMs) have now evolved to include capabilities that simplify and/or augment a wide range of jobs.
As enterprises consider wide-scale adoption of LLMs for use cases across their workforce or within applications, it’s important to note that while foundation models provide logic and the ability to understand commands, they lack the core knowledge of the business. That’s where fine-tuning becomes a critical step.
This blog explains how to attain the highest-performing LLM for your use case through the process of fine-tuning an available open source model with your own organizational data.
Creating the Dataset
Let’s consider a company that wants to build a knowledge base to assist customer support with answering queries faster and more accurately. A dataset can be created from existing support tickets or chats that can be parsed and entered into a vector database.
Q: Does clearml-task need requirements.txt file? A: clearml-task automatically finds the requirements.txt file in remote repositories. If a local script requires certain packages, or the remote repository doesn't have a requirements.txt file, manually specify the required Python packages using --packages "<package_name>", for example --packages "keras" "tensorflow>2.2" Q: How can you use clearml-session to debug an experiment? A: You can debug previously executed experiments registered in the ClearML system on a remote interactive session. Input into clearml-session the ID of a Task to debug, then clearml-session clones the experiment's git repository and replicates the environment on a remote machine. Then the code can be interactively executed and debugged on JupyterLab / VS Code. Note: The Task must be connected to a git repository, since currently single script debugging is not supported. In the ClearML web UI, find the experiment (Task) that needs debugging. Click on the ID button next to the Task name, and copy the unique ID. Enter the following command: clearml-session --debugging-session <experiment_id_here> Click on the JupyterLab / VS Code link, or connect directly to the SSH session. In JupyterLab / VS Code, access the experiment's repository in the environment/task_repository folder.
The dataset needs to be clean, and ingestion can be a challenging step. However, with tools such as ClearGPT, pre-built wizards make the process simple and replicable for future updates. ClearGPT is ClearML’s low-code, secure, end-to-end LLM platform for the enterprise, featuring data ingress, training, quality control, and deployment.
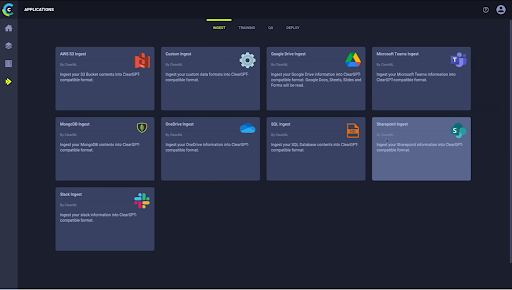
Choose your data ingestion wizard (or build your own)
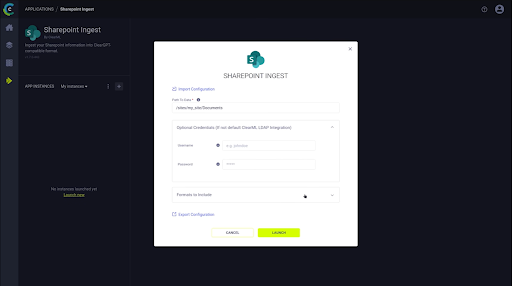
Enter the necessary file path and parameters
Fine-tuning the Model
For the majority of business use cases, accuracy is non-negotiable. Using generic models that spit out directionally correct yet non-specific responses is not ideal. Models such as GPT-4 are well-suited for consumers requiring recommendations or answers gleaned from a wide breadth of data. While they may satisfy a company’s initial curiosity about LLMs or even serve as a viable POC, as-is, these models will fail to deliver the right answers to deep, domain-specific knowledge requests.
Not only will these models deliver inaccurate results, they are also big and cumbersome. When trying to extract the best response, the sheer size of their knowledge database can easily result in latency (and concomitant high token costs).

Contrary to common belief, enriching answers with Embeddings and VectorDBs (RAB), does not solve the problem. Good references are provided when the retrieval process succeeds (i.e. querying the vectorDB for answers / documents), but the main caveat is the lack of control in the vectorDB results. There is no mechanism to “select” or “score” the different entries in the vectorDB. Stay tuned for a future blog post on how to add control and combine VectorDBs.
If common sense dictates that a model trained on data for a specific use case will perform better, there is no need to build the biggest, smartest model out there. At ClearML, we advocate building the best model you can for each specific use case. Running multiple “smaller” (a relative term, as these still have a few billion parameters at minimum and often tens of billions) models across your organization can be an efficient and effective choice.
Within ClearGPT, it’s easy to apply your dataset to a foundation model for training.
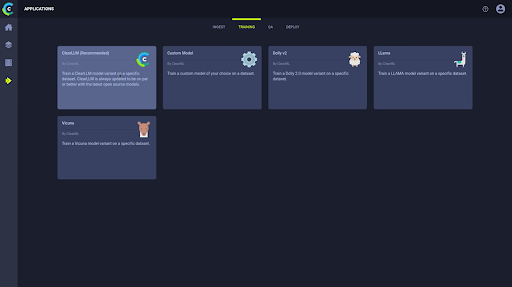
Choose your foundation model
Choose your foundation model
QA-ing the Model
One major difference between a LLM and a ‘standard’ ML model is the need for active QA. Most of the time, the data engineers building and training LLMs are not subject matter experts. Involving stakeholders from the business to test and provide feedback about the model accuracy (reinforcement learning by human feedback) is extremely important due to the generative nature of LLMs. This data should also be latest fed back into the model fine-tuning process. ClearGPT is designed for the most demanding enterprise environments to revolutionize your business performance, helping your organization run smarter and faster.
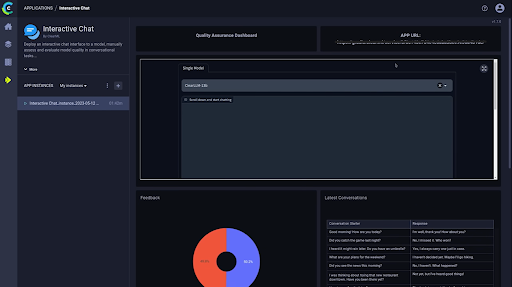
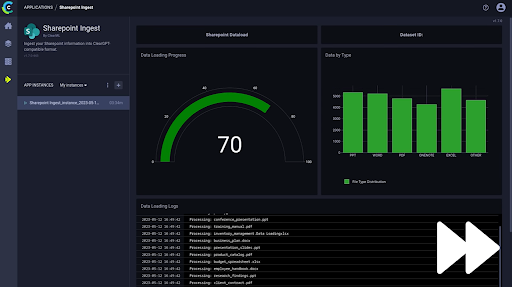
QA example: a Gradio app that captures SME feedback
Deploying the Model
Congratulations, you have successfully created a working LLM for your business! You can embed the model within an application or deploy it as an API. Just remember to limit model access to the appropriate group of business users. ClearGPT facilitates this through SSO, authentication, and permissions settings. ClearML’s role-based access control ties individual users to datasets and models, ensuring they (and the model they are using) can only access the data available to them.
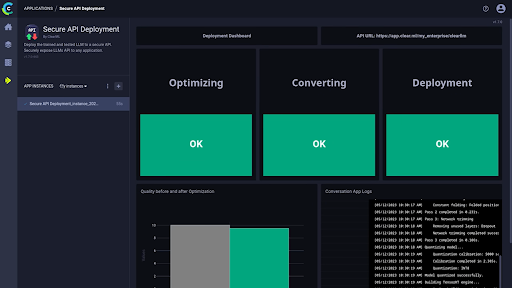
Deploy your model!
Smaller, Surgical LLMs are Better for Specialized Use Cases
LLM foundation models hold tremendous promise, enabling the application of AI to solve real-world problems. However, they are not an off-the-shelf solution for enterprises with use cases requiring domain-specific knowledge. While other methods such as prompt engineering can be applied on top of models to manage inputs and outputs, fine-tuning models on your own data is the more scalable and sustainable solution, providing your team with full control over performance with greater accuracy.
To speak with ClearML about implementing Generative AI at your organization, please visit https://clear.ml/cleargpt-enterprise.