By Victor Sonck, MLOps Evangelist at ClearML
In this blog post, we’ll be taking a closer look at Hyper-Datasets, which are essentially a supercharged version of Clear-ML Data.
=> Prefer to watch the video? Click below:
Hyper-Datasets vs ClearML Data (and Other Data Versioning Tools)
Hyper-Datasets is a data management system that’s designed for unstructured data such as text, audio, or visual data. It is part of the ClearML paid offering, which means it includes quite a few upgrades over the open source clearml-data.
The main conceptual difference between the two is that Hyper-Datasets decouples the metadata from the raw data files. This allows you to manipulate the metadata in all kinds of ways, while abstracting away the logistics of having to deal with large amounts of data.
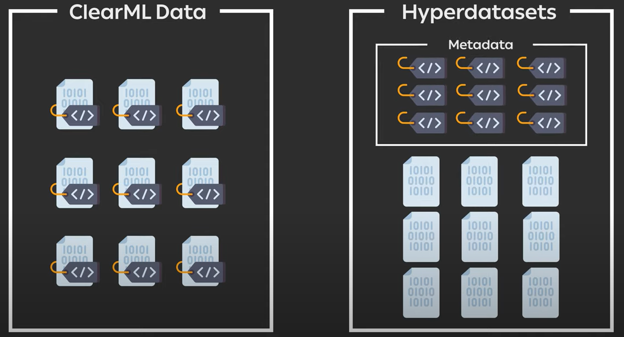
Manipulating the metadata is done through queries and parameters, both of which can then be tracked using ClearML Experiment.
This means it’s easy to not only trace back which data was used at the time of training, but also clone the experiment and rerun it using different data manipulations without changing a single line of code.
Combine this with the clearml-agent and autoscalers and you can start to see the potential. The data manipulations themselves become part of the experiment, which we call a dataview. A machine learning engineer can create the model training code and then a data engineer or QA engineer can experiment with different dataset configurations without any coding. In essence, the data access is completely abstracted.
By contrast, in ClearML Data, just like many other data versioning tools, the data and the metadata are entangled. Take this example where the label of the image is defined by which folder it is in, a common dataset structure:
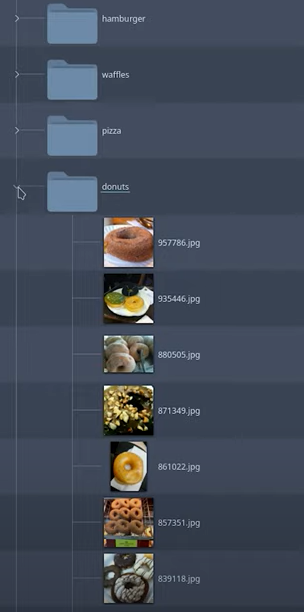
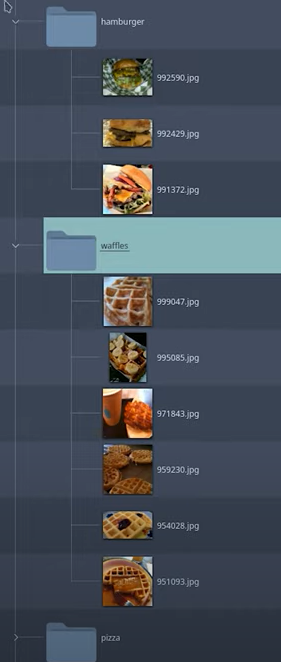 But what if I want to train only on donuts? Or what if I have a large class imbalance? I still have to download the whole dataset even though I might only be using a small part of it. Then I have to change my code to only grab the donut images or to rebalance my classes by over- or under- sampling them. If later I want to add waffles to the mix, I have to change my code again.
But what if I want to train only on donuts? Or what if I have a large class imbalance? I still have to download the whole dataset even though I might only be using a small part of it. Then I have to change my code to only grab the donut images or to rebalance my classes by over- or under- sampling them. If later I want to add waffles to the mix, I have to change my code again.
Data Exploration
Let’s take a look at an example that will show you how to use Hyper-Datasets to debug an underperforming model. But first, we start where any good data science projects starts: data exploration.
When you open Hyper-Datasets to explore a dataset, you can find the version history of that dataset here (screenshot below, outlined in red). Datasets can have multiple versions, which in turn can have multiple child versions. Each of the child versions will inherit the content of their parents.
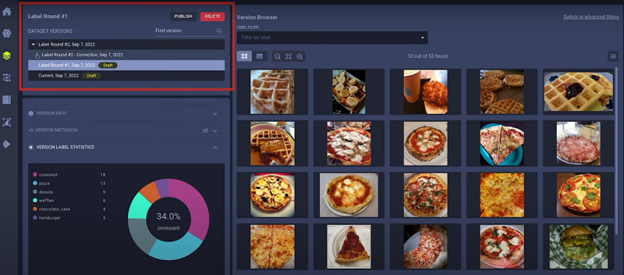
By default, a dataset version will be in draft mode, meaning it can still be modified. You can press the publish button (located in the upper right of the section outlined in red above) to essentially lock it to make sure it will not change anymore. If you want to make changes to a published dataset version, make a new version that’s based on it instead.
You’ll find automatically generated label statistics in the lower left section of the screenshot above that give you a quick overview of the label distribution in your dataset as well as some version metadata and other version information.
To the right of the screenshot, you can actually see the contents of the dataset itself. In this case, we’re storing images, but it could also be video, audio, text, or even a reference to a file that’s stored somewhere else, such as in an S3 bucket.
When you click on one of the samples, you can see the image itself as well as any bounding boxes, keypoints, or masks the image may have been annotated with:

On the right outlined in red in the screenshot above, you can see a list of all the annotations in the image, including classification labels for the image itself.
After going back to the main screen, you can also view your samples as a table instead of a preview grid, which can be handy for audio or text, for example:
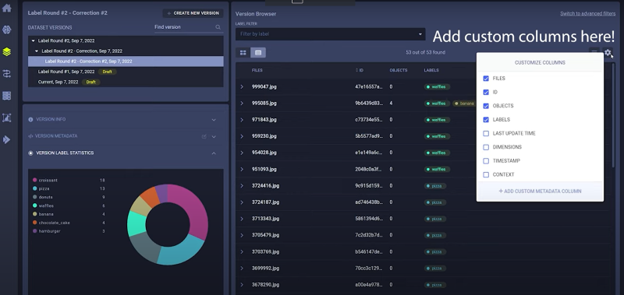
Querying & Dataviews
Above the table, you can try out the querying functionality by switching to advanced filters. As an example, you could create a query that only includes donuts with a certainty of at least 75 percent. You can query on basically any metadata or annotation, so go nuts!
The goal of these queries is not simply to serve as a neat filter for data exploration, we want to use these queries as part of our machine learning experiments!
Enter the dataviews introduced earlier in this blog post. Dataviews can use sophisticated queries to connect specific data from one or more datasets to an experiment in the Experiment Manager. Essentially it creates and manages local views of remote Datasets.
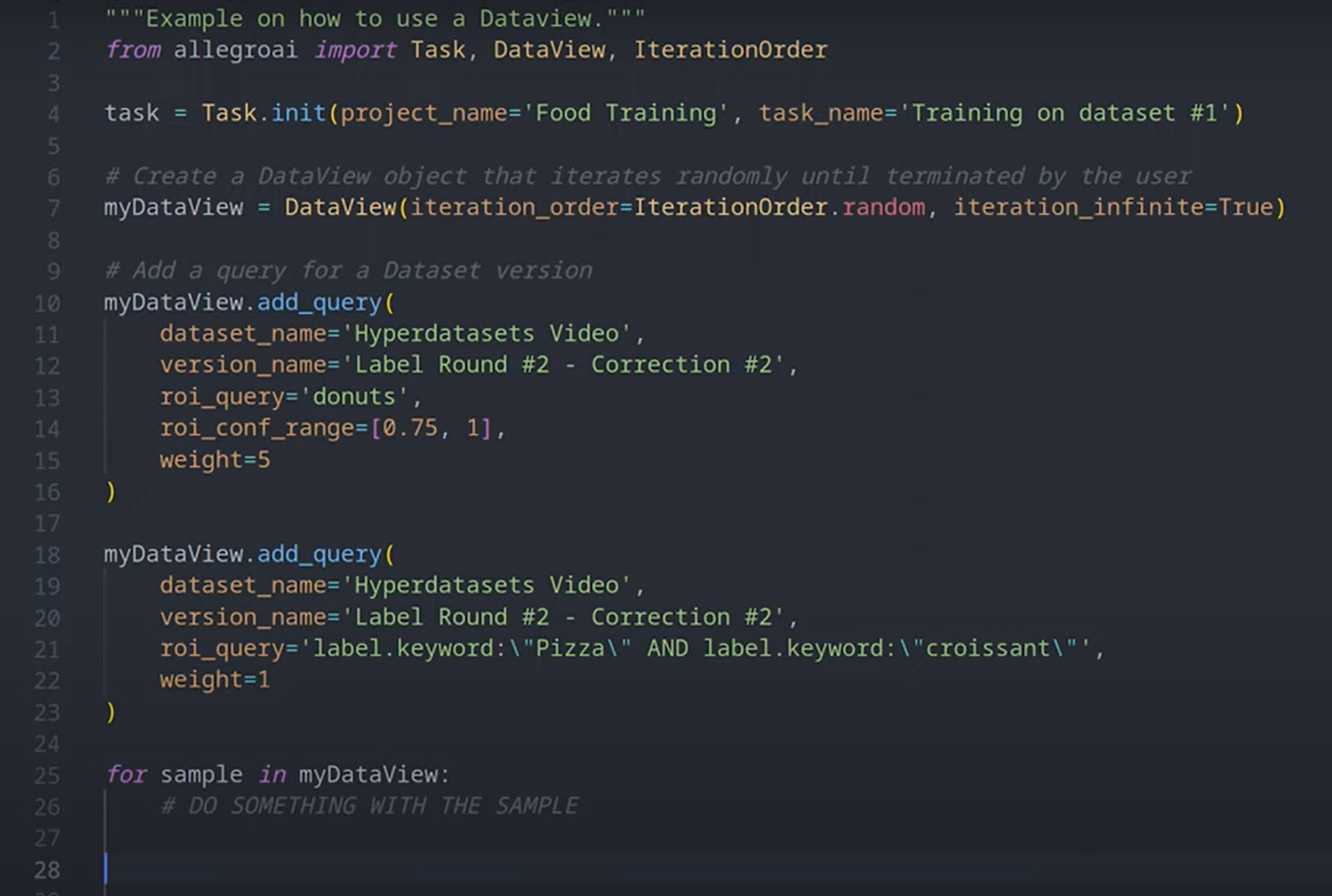
As an example, imagine you have created an experiment that tries to train a model based on a specific subset of data using Hyper-Datasets. To get the data you need to train on, you can easily create a dataview from code like so. Then you can add all sorts of constraints, like class filters, metadata filters, and class weights which will over- or under-sample the data as required:
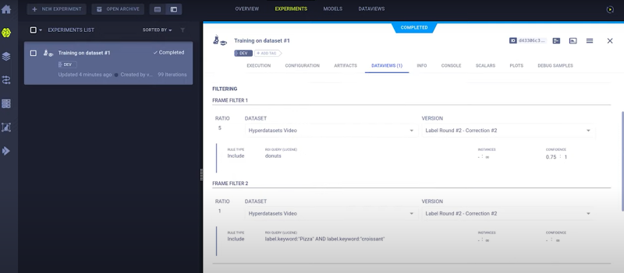
After running the task, we can see it in the Experiment Manager. The model is reporting scalars and training as we would expect. When using Hyper-Datasets, there is also a dataviews tab with all of the possibilities at your disposal. You can see which input datasets and versions that you used and can see the querying system that is used to subset them:
This will already give you a nice, clean way to train your models on a very specific subset of the data, but there is more!
If you want to remap labels, or enumerate them to integers on the fly, ClearML will keep track of all the transformations that are done and make sure they are reproducible. There is, of course, even more – so if you’re interested, check out our documentation on Hyper-Datasets.
Cloning a Dataview
ClearML veterans already know what’s coming next: Cloning. Imagine the scenario that the Machine Learning engineer has created the model training code that we saw before: an integrated dataview as the data source.
Now, a QA engineer or data analyst has spotted that the data distribution is not very balanced and that’s throwing the model off.
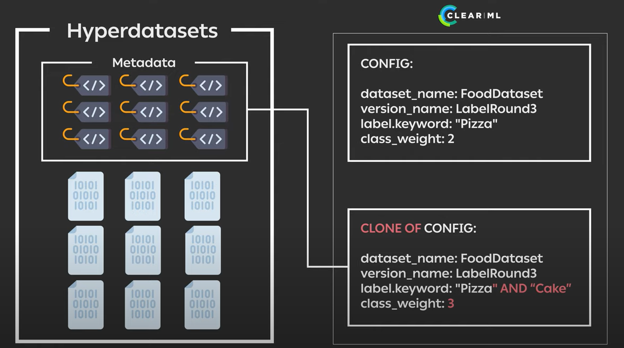
Without changing any of the underlying code, someone can clone the existing experiment. This allows them to change any of the queries or parameters in the dataview itself. In this example, we’ll change the class weight to something else, modifying the data distribution in the process:
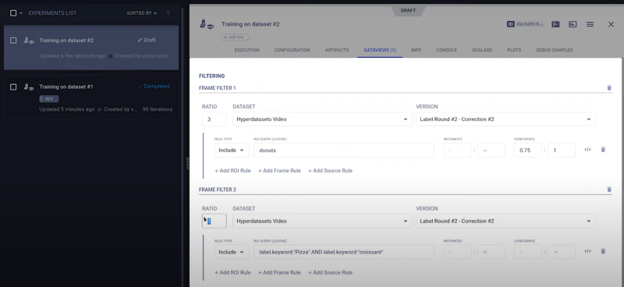
You can then enqueue this experiment for a remote ClearML agent to start working on. The exact same model will be retraining on a different data distribution running on a remote machine in just a few clicks, no code change required.
After the remote machine has executed the experiment on the new dataview, we can easily compare the two experiments to further help us with our analysis:
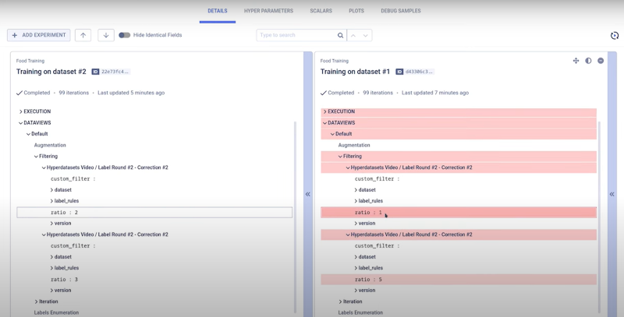
This is a very fast and efficient way to iterate and get rid of so much unnecessary work.
Conclusion
If you’ve been following along with our getting started videos over on our YouTube channel, you should already start to see the potential this approach can have. For example, we could now run hyperparameter optimization on the data itself, because all of the filters and settings previously shown are just parameters on a task. The whole process could be running in parallel on a cloud autoscaler, for example. Imagine finding the best training data confidence threshold for each class, just to optimize the model performance.
If you’re interested in using Hyper-Datasets for your team, please contact us, and we’ll get you going in no time. In the meantime, you can enjoy the power of the open source components at app.clear.ml and don’t forget to join our Slack channel, if you need any help.