And get a full fledged MLOps stack with it for free

Deploying models is becoming easier every day, especially thanks to excellent tutorials like Transformers-Deploy. It talks about how to convert and optimize a Huggingface model and deploy it on the Nvidia Triton inference engine. Nvidia Triton is an exceptionally fast and solid tool and should be very high on the list when searching for ways to deploy a model. Our developers know this, of course, so ClearML Serving uses Nvidia Triton on the backend if a model needs GPU acceleration. If you haven’t read that blogpost yet, do it now first, we will be referencing it quite a bit in this blogpost.
Note: benchmarking a served model is both super interesting and very hard to do. It is highly dependent on how it is set up and how much time you spend fine-tuning each option’s performance, so from the start, the numbers in this blog post (and any other benchmarking blogpost) are to be taken with a grain of salt. Ideally, you can use the methodology as your own starting point though.
The code for setting up this example with ClearML Serving can be found here. Give it a spin and let us know what you think!
What ‘Vanilla’ Triton Is Missing And ClearML Serving Adds
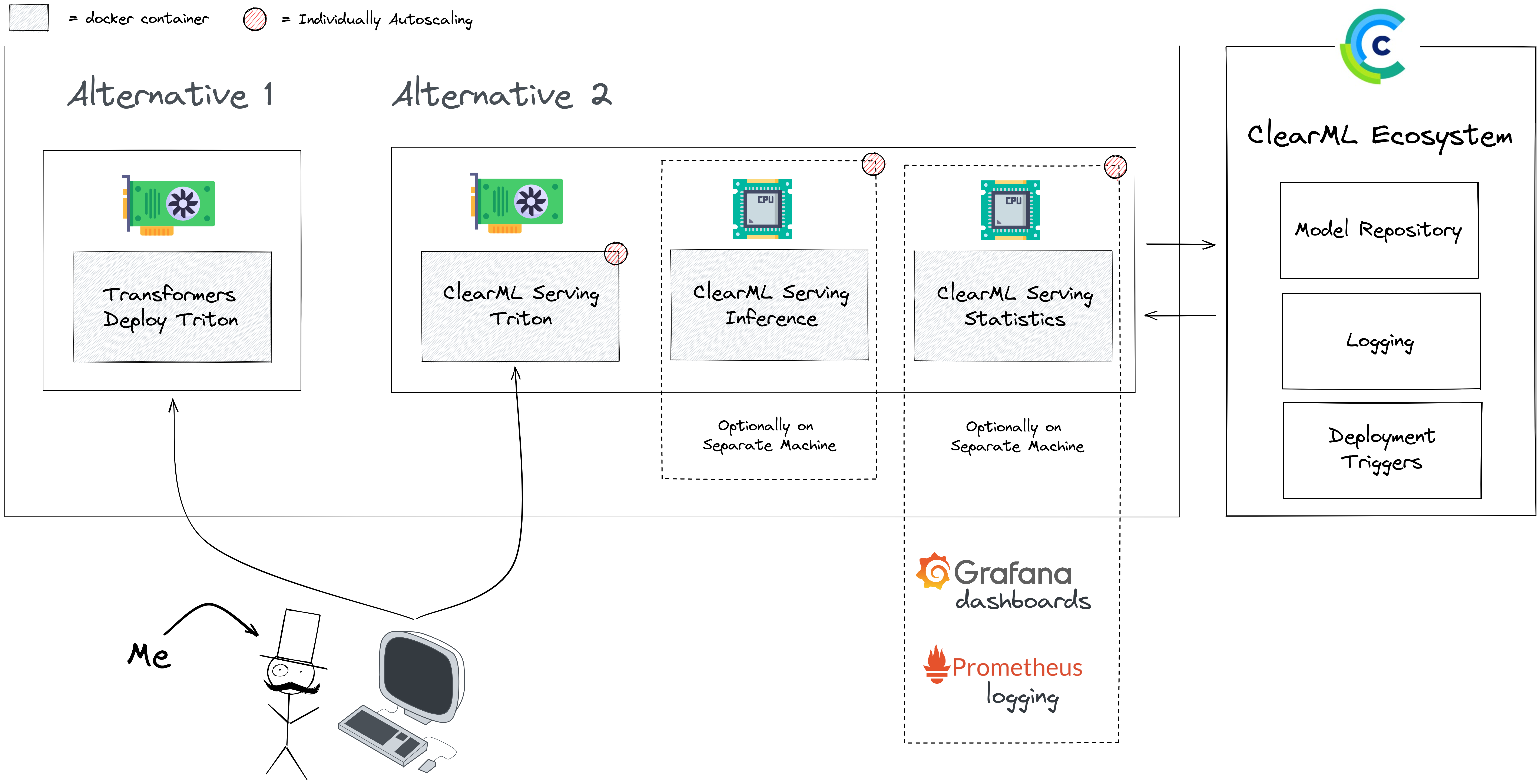
Apart from performance, there are some quality-of-life features that Triton is lacking which ClearML Serving is trying to address. ClearML is an open-source and free MLOps toolbox and ClearML Serving is the newest tool in there 🔨.
Triton is completely standalone and isn’t integrated in any workflow out of the box, which means you have to spend quite a bit of time making sure it works nicely with your existing stack. This is excellent as it allows Triton to focus and excel at what it does, but you still need quite a few extra features in a real production environment.
Model repository
For one, it should be connected to your model repository, so you can easily deploy new versions of your models and automate the process if required. While you’re at it, it would be nice to be able canary deploy the new model, splitting the traffic gradually from the old model to the new model. This can all be done of course, but it requires precious engineering time and deep knowledge on how Triton works.
Custom statistics
Custom statistics is another field where the out of the box Triton experience is rather limited. Ideally, one could easily define custom user metrics of not only latency and throughput but also analyze the incoming and outgoing data distributions to later detect drift. It’s possible to do this in Triton, but you have to define them in C with the only documentation being (and I quote):
Further documentation can be found in the TRITONSERVER_MetricFamily* and TRITONSERVER_Metric* API annotations in tritonserver.h
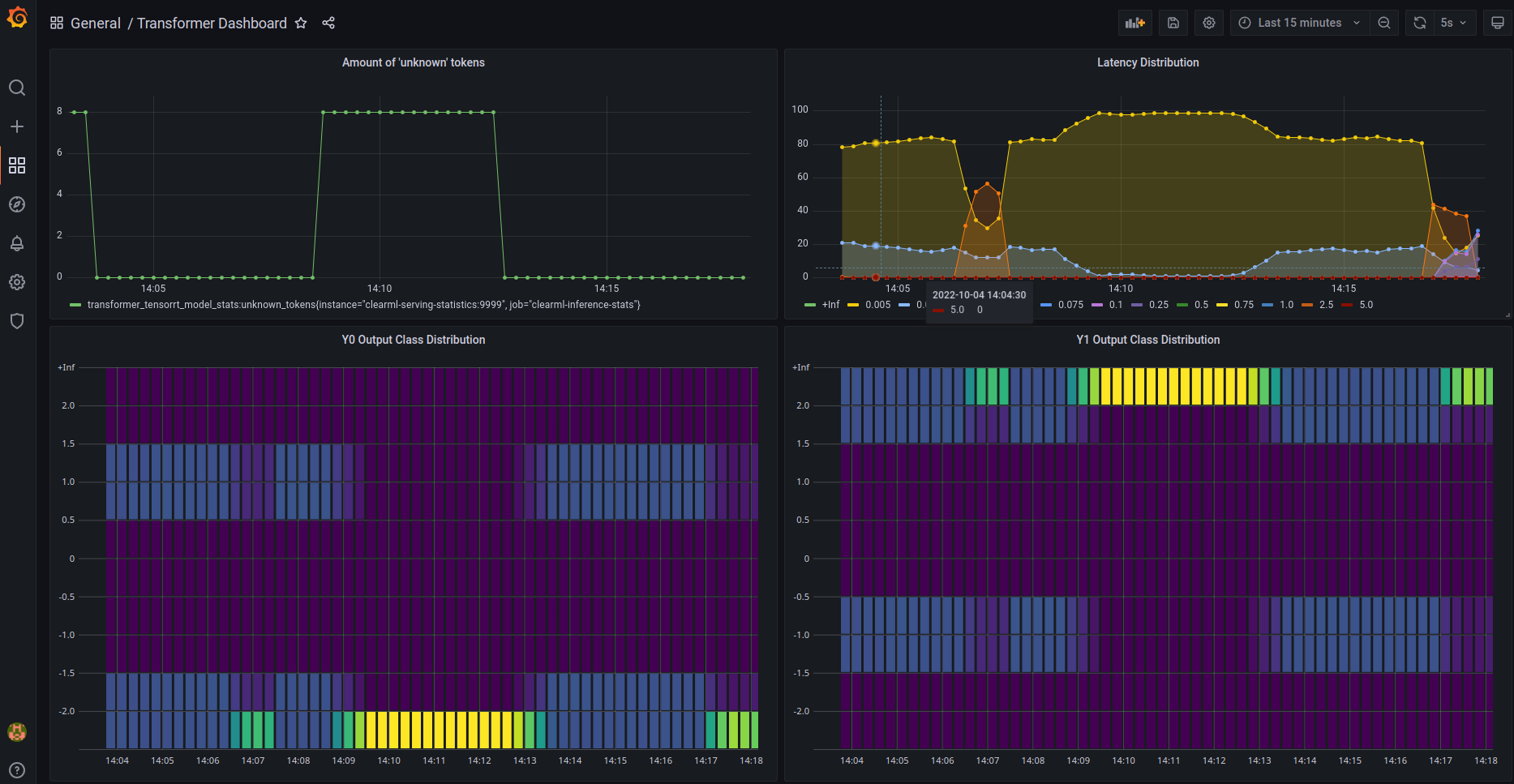
Using these custom statistics you can set up a monitoring dashboard that ingests your own custom metrics. Then you can add automated alerts to these metrics to make sure you don’t miss it if when things start to go south. We’ll go more in depth on custom metrics in a later blogpost.
End-To-End traceability
Finally, a result of Triton not being integrated out of the box is limited traceability. You want to make sure that when the monitoring picks up an issue or bug, its easy to “click through” from the deployed model, through which pipeline was used to train it, to each of the steps of that pipeline all the way back to even which dataset version ID was used to train the model on.
To be clear (pun intended), it is not necessarily the responsability of Triton to add all this functionality. They make an excellent, highly focussed, highly performant model serving engine. It is up to you to decide how much extra bells and whistles you want to add. ClearML Serving adds seamless model updates, integration with the completely open-source ClearML platform, custom metrics and monitoring without losing performance. We put the engineering time into it, so you don’t have to!
Benchmarking setup
Latency vs Throughput
Latency is the amount of time that passes from the moment you send a payload to the API, to the time you get a result back. This is usually the metric people pay a lot of attention to and it is very much the flashiest. Lower number, better number.

But that’s not always how it works in the real world. There are some issues with using only single request latency as a metric:
- Latency is heavily influenced by the current load on the server. You might get sub-1ms latency in isolation, but it rapidly grows to 100+ms when the server is being pelted by 100s of other requests.
- Latency tells you nothing about scaling and hardware utilization. You want to know how much of your CPU and GPU are being utilized for handling the load, so you can scale up to use more hardware if it is still available.
- Latency can be bad when using methods that actually raise throughput. Cool features such as dynamic batching can make the whole process more efficient at the cost of individual latency. Dynamic batching pools together individual incoming requests into an impromptu batch, which utilizes more of the GPUs potential. The cost is that the first request of each batch will have to wait a little bit for others to come in, raising latency.
Throughput on the other hand calculates the total amount of requests a server can process per second (RPS). We will focus on this number more in this blogpost, because it is a key concern for most machine learning models that are deployed at scale. It more closesly represents the reality, when compared to single request latency. To be clear: latency is still a very important metric to test, just not in isolation. We’ll be reporting both of them.
The cloud machines of choice
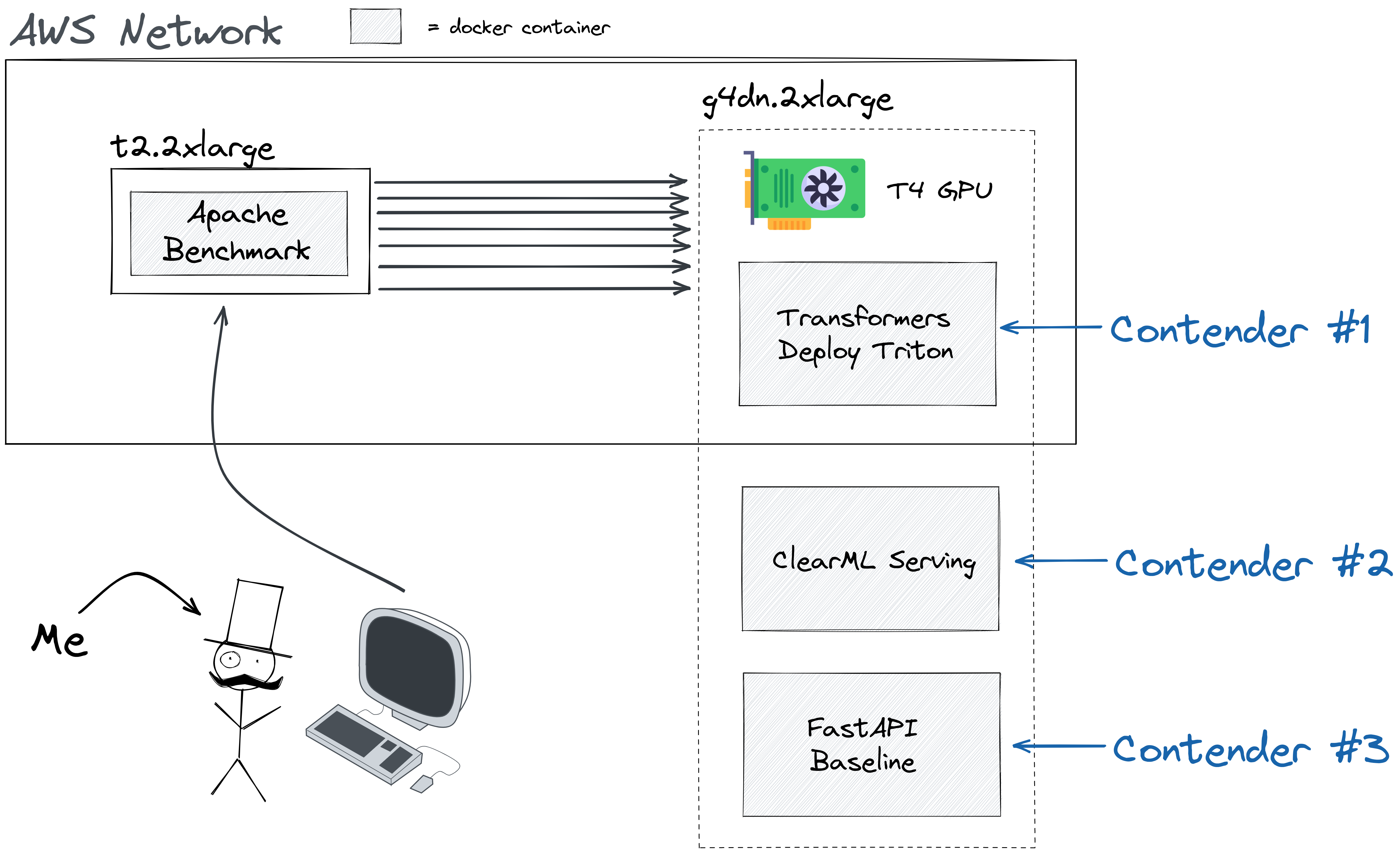
To run our setup we opted for the AWS g4dn.2xlarge machine which consists of 8 vCPUs, 32 Gb of memory and, crucially, 1 NVIDIA T4 GPU. This GPU is pretty damn cool, it only consumes 70W which makes it comparatively cheap to use as a cloud GPU. On the other hand, it is optimized for deep learning inference. It does not have an obscene amount of VRAM like the A100, but it is meant to compete in inference performance per dollar, in which it shines.
On the other hand, we used a separate t2.2xlarge machine to run the benchmark from. Generating requests does not take much CPU power, but running a deep learning inference server together with lots of workers to handle the HTTP overhead does. So in order not to have the actual testing interfere with the results, we isolated it. Of course, now we just traded off possible CPU interference with possible network interference and that’s true! But the internal AWS network is really fast and stable so in terms of fluctuations its really not bad at all. The numbers themselves might be a little lower due to added network latency, but the relative performance between the contenders should stay the same and at the very least it will reflect a more realistic usecase.
The local machine of choice
Because I was already benchmarking, I thought of running the same suite of tests on my personal gaming rig as well. The most interesting thing about this specific machine is that it has quite a high quality CPU compared to the GPU, which you will not find in most cloud machines. As you’ll see later, that detail had an impressive impact on the performance of the ClearML Serving stack. The exact specs of the machine are:
| CPU | AMD Ryzen 9 3900X 12-Core Processor |
|---|---|
| GPU | NVIDIA GeForce RTX 2070 SUPER |
| RAM | Dual channel 32GB 2133 DDR4 |
| OS | Manjaro Linux |
ONNX instead of TensorRT
Conventional wisdom states that TensorRT will be faster than ONNX, even if the latter is optimized. However, this is assuming everything “just works”. For one, in the original blogpost, the authors show that the optimized ONNX binary is actually a hair faster than TensorRT!
Which is also why the record breaking sub 1ms inference latency they achieved was actually from the ONNX model deployed on Triton.
We did get the TensorRT model to work on Triton, but it did not want to play nicely with dynamic batching. We’re looking into it and hoping to get you some extra benchmarks of TensorRT in the future. That said, this blogpost is mainly about the delta between ClearML Serving and Triton, which should carry forward to TensorRT Triton as well, as both use the same backend in the end.
A note on Python Locust, and why we tested with apache benchmark
Locust is a popular python load testing framework. But it is written in python, so it is slow, no way around it. It is easy to use, though, and produces a nice visual. That said, to make sure we show you how much throughput you can maximally expect, we ended up using the Apache benchmark tool. It is written in C and produces very fast and stable results when compared to locust (which gave us very unstable metrics, even deployed distributed with FastHTTPClient).
The Contenders: what are your options when deploying?
FastAPI
The easiest way to get a model up and running is to just “wrap it in a flask api”. The whole concept has become a bit of a joke these days, because there is really no good reason why you would do this these days. Not from a performance perspective, but not even from an ease of use perspective! You’ll get no seamless model updates, poor speed, no integration, you have to write everything you want yourself. Maybe it’s ok for a hobby project where you don’t need all of this and just want an API with 50 lines of python code. But even then it’s a stretch.
That said, we can use it as a baseline. This is the code for our small, impromptu model API server:
If there are any fastAPI lovers reading this, we love fastAPI! It’s just not designed to handle deep learning model serving. Apart from that it is very easy to set up and requires an exceptionally low amount of lines of code, thanks to the excellent Huggingface library. But still, don’t do this at home.
Triton Ensemble
Following the instructions on the accompanying github repository of the original transformers deploy blogpost, we essentially have to execute only 2 docker commands.
Triton is without a doubt the fastest model serving engine on the market today. And we got I running in just 1 command! But what now? We need to monitor our newly deployed model. We will need to update it in the future without having downtime. Maybe we will want to do A/B testing even! Triton offers pure performance, plain and simple, but it is missing some essential quality of life features that ClearML tries to address.
Following these steps will also actually set up 3 different endpoints. 1 for the model itself, 1 for the tokenizer and then a 3rd endpoint which runs these 2 one after another in an ensemble. You’ll read more about that later.
ClearML Serving
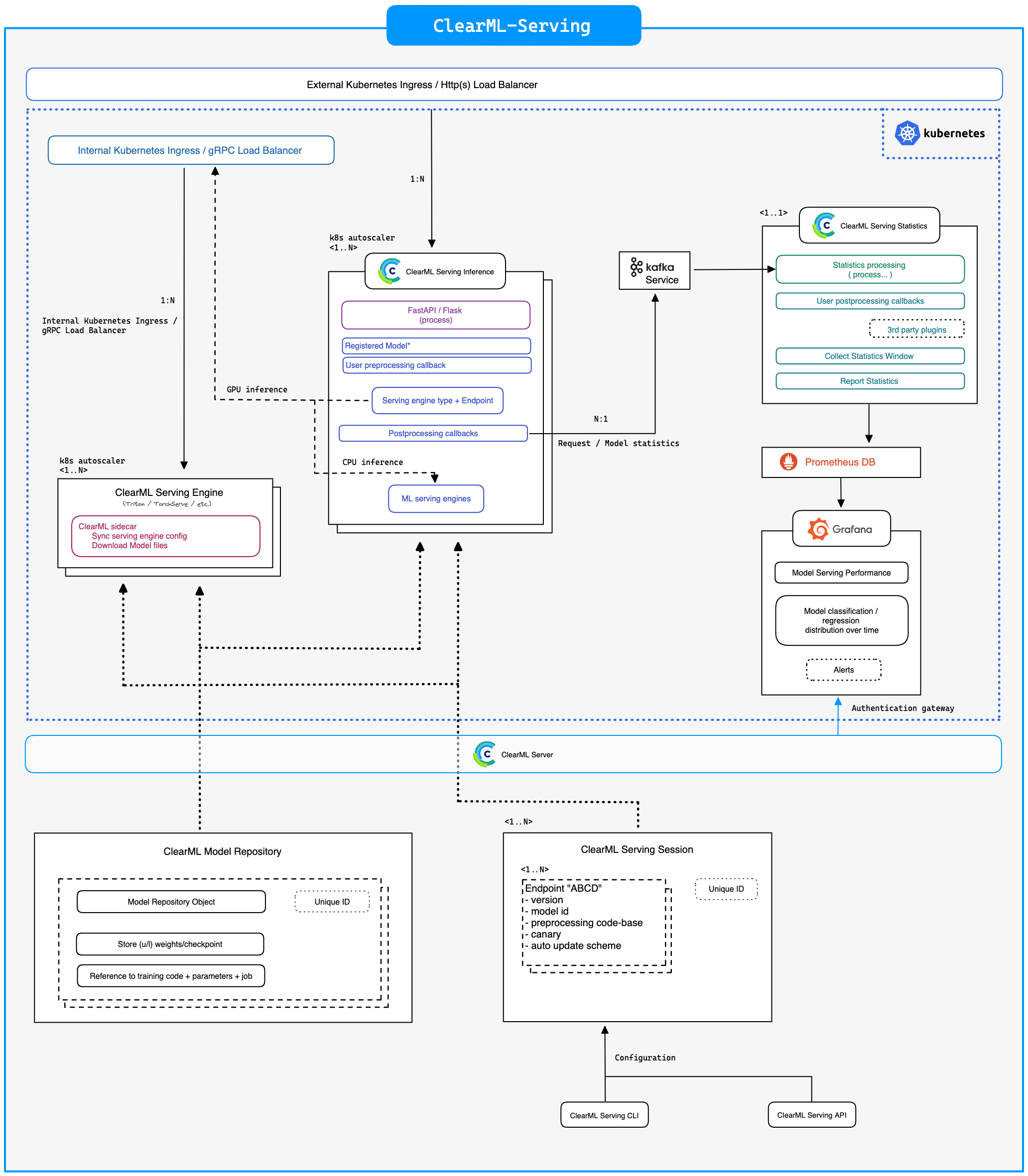
ClearML Serving serves as a middleman in between you and Nvidia Triton (or Intel OneAPI in case you want to use CPU for inference). This allows us to extract custom logs on the incoming and outgoing data. Naturally this will add a certain amount of overhead, but if you want more functionality, you’ll always introduce more overhead for it, how far you want to go is your own call!
That said: we’ll see later that starting from a certain scale, this overhead is no longer visible and the benefit of scaling will start to take over. This makes it so the resulting total throughput ends up being a lot higher.
For those who are thinking: “Wait, aren’t you essentially ‘wrapping it in a flaskapi’ by putting FastAPI in the middle?”. We are not running our model in python code, nor are we expecting FastAPI to handle things like dynamic batching. Like we said before, FastAPI is awesome, you just have to take the best of both worlds here. Combine the C-level performance, dynamic batching and GPU allocation of Triton, with the lightweight, easy-to-use and highly scalable FastAPI. A flask API is not a bad idea as a rule, it highly depends on what you are using it for. In this case it is routing traffic, autoscaling and allowing custom user python code execution, pretty much exactly what it was designed to do.
ClearML serving is, of course, designed around the open source ClearML ecosystem. For example, you get the benefit of all the logging throughout the system being centralized in the ClearML webUI. It also means that it’s very easy to deploy any model that is already inside the system. The benefit of this is that you start building up your model repository organically while using the experiment manager. That said, you don’t have to do it this way if you don’t want to. We can also simply upload a model that we already made, such as in this case.
Now that we have the model, all we have to do is deploy it, which we can do with a single command! You can find all the input and output information in the config.pbtxt that comes with the triton models.
Setting up the contenders
Model Details
We’re using “philschmid/MiniLM-L6-H384-uncased-sst2” as our testing model, the exact same model that was used in the original Transformer-Deploy blogpost. The sequence length of our test input is 16 tokens, while the model goes up to 128. This means it produces the absolute fastest numbers you can expect, so bear that in mind when trying this yourself.
Autoscaling Tokenization
You can also see in the snippet above that we have added a custom preprocessing.py file as the preprocessing for the ClearML Serving endpoint. This file has a very similar job as the custom python endpoint in the original blogpost: it tokenizes the request. The main difference here is that the tokenization is done in the middle, before it reaches Triton, which makes it able to autoscale independently from the Triton engine! It’s super easy to add a custom preprocessing step, as an example here is the one we used for the benchmark:
In Triton, this process is done by creating a custom python “model” which then runs the tokenizer. The main drawback of this method is the lack of autoscaling, Triton was not designed to handle this kind of setup well. It works and it is fast, but it makes a lot more sense to extract the CPU-bound preprocessing away from Triton and scale it independantly. This is where FastAPI and servers like gunicorn shine: handling lots of smaller requests and to scale accordingly.


Dynamic Batching
Triton supports dynamic batching, which is a really cool and intuitive way to raise throughput at the possible cost of individual latency.
It works by holding the first incoming request for a configurable amount of time. While waiting it is listening for other incoming requests, if they come in within the waiting threshold, these additional requests are added to the first to form a batch. The batch is processed earlier if it fills to a maximum size within the time limit. Usually a batch is way more efficient to process on a GPU, so it makes sense to try and optimize the hardware utilization in this way.
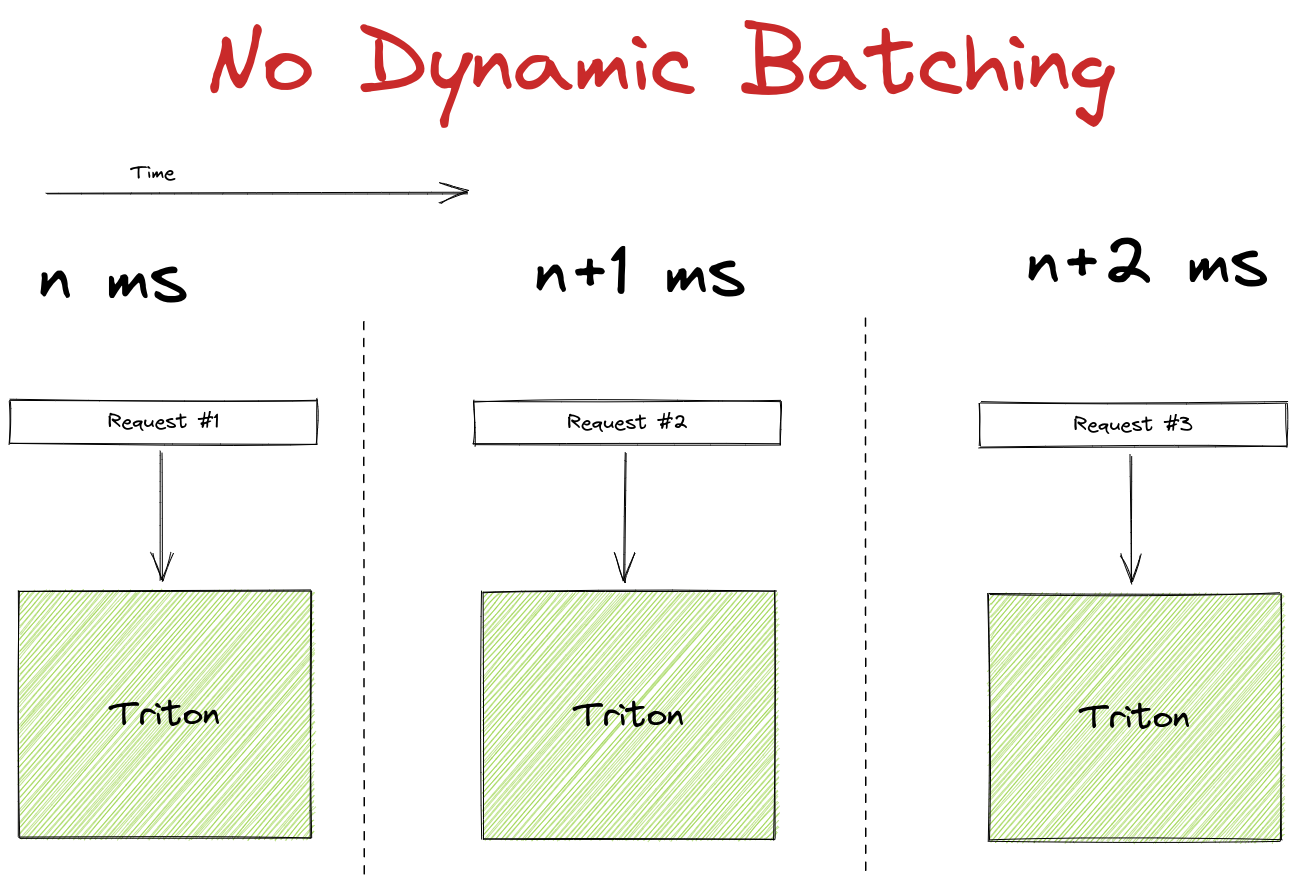

Be aware though, that dynamic batching is mainly targeted towards high-load systems and its easy to see why. If your system only periodically gets a request in, a high percentage of the requests will end up waiting for additional traffic that never comes. They will be sent through the GPU all alone and end up with way more latency than the system is capable of, without any tangible benefit.
The Results!
Using Apache Benchmark we can now run the following command in a terminal on the smaller AWS VM:
We ended up using -c 128 because it basically ends up saturating the GPU at that kind of load and we didn’t see any more apreciable gains past that point.
First off, we want to know how our contenders perform without enabling Triton dynamic batching. As expected the FastAPI wrapper around the huggingface interface lags behind, although it does hold up surprisingly well against the others. As you’ll see though, this is only for batch size 1, but it’s still quite impressive for a server that essentially amounts to 21 lines of code.
Next, we see that ClearML comes second with a result that depends on how many workers are used, but never quite reaching Triton in terms of speed. And this makes sense because in the end, we are adding additional functionality on top of Triton itself, which will introduce extra latency. It isn’t much, because we put a lot of effort in to optimize everything, but it stands to reason we can never fully match the performance of Triton in this case.

| Latency mean | Latency per process | RPS | Triton Dynamic Batching | Variant | |
|---|---|---|---|---|---|
| ClearML 8 Workers + Dynamic Batching | 35.794 | 0.28 | 3575.97 | Yes | ClearML gunicorn |
| ONNX Triton ensemble + Dynamic Batching | 51.015 | 0.399 | 2509.09 | Yes | Triton Ensemble |
| ClearML 2 Workers + Dynamic Batching | 72.425 | 0.566 | 1767.34 | Yes | ClearML gunicorn |
| ONNX Triton ensemble | 112.551 | 0.879 | 1137.26 | No | Triton Ensemble |
| ClearML 2 Workers | 113.958 | 0.89 | 1123.22 | No | ClearML gunicorn |
| ClearML 8 Workers | 114.224 | 0.892 | 1120.61 | No | ClearML gunicorn |
| ClearML 1 Worker + Dynamic Batching | 136.58 | 1.067 | 937.18 | Yes | ClearML gunicorn |
| ClearML 1 Worker | 138.541 | 1.082 | 923.91 | No | ClearML gunicorn |
| FastAPI Baseline | 158.177 | 1.236 | 809.22 | No | Plain FastAPI |
The story changes quite drastically when enabling dynamic batching on the Triton engine though. Bear in mind we enabled dynamic batching both on our underlying Triton instance as well as for the one from Transformers-Deploy.
We see that when using 1 ClearML Worker, we essentially get the more or less the same performance as without dynamic batching. This, too, makes sense as the 1 worker quickly ends up being the bottleneck in this scenario. But things start to change quickly when ramping up the amount of workers. When using 8 ClearML workers, the total throughput is significantly higher than even the Triton Ensemble!
This effect is even more pronounced in my own machine. It seems that the higher quality, speed and core count of the CPU has a drastic effect on performance in the case of ClearML Serving. Not surprising, because the ClearML workers rely heavily on CPU-based scaling to be able to properly feed the GPU. Comparing the 8 worker ClearML result with dynamic batching to the Triton ensemble with dynamic batching, you get the performance increase from the title. If you compare that to Triton out of the box, without dynamic batching, it would be a whopping 608% increase.
| Latency mean | Latency per process | RPS | Triton Dynamic Batching | Variant | |
|---|---|---|---|---|---|
| ClearML 8 Workers + Dynamic Batching | 9.647 | 0.075 | 13269 | Yes | ClearML gunicorn |
| ONNX Triton ensemble + Dynamic Batching | 28.341 | 0.221 | 4516 | Yes | Triton Ensemble |
| ClearML 2 Workers + Dynamic Batching | 29.12 | 0.227 | 4396 | Yes | ClearML gunicorn |
| ClearML 1 Worker + Dynamic Batching | 58.126 | 0.454 | 2202 | Yes | ClearML gunicorn |
| ONNX Triton ensemble | 68.364 | 0.534 | 1872 | No | Triton Ensemble |
| ClearML 2 Workers | 69.513 | 0.543 | 1841 | No | ClearML gunicorn |
| ClearML 8 Workers | 69.477 | 0.543 | 1842 | No | ClearML gunicorn |
| ClearML 1 Worker | 72.014 | 0.563 | 1777 | No | ClearML gunicorn |
| FastAPI Baseline | 99.089 | 0.774 | 1292 | No | Plain FastAPI |
Wait, but we said before that we cannot hope to even match the Triton performance, let alone surpass it by this much. Well, that was true before the dynamic batching. But after enabling it, the single instance of the python “model” that is running the tokenization, is starting to become a bottleneck.
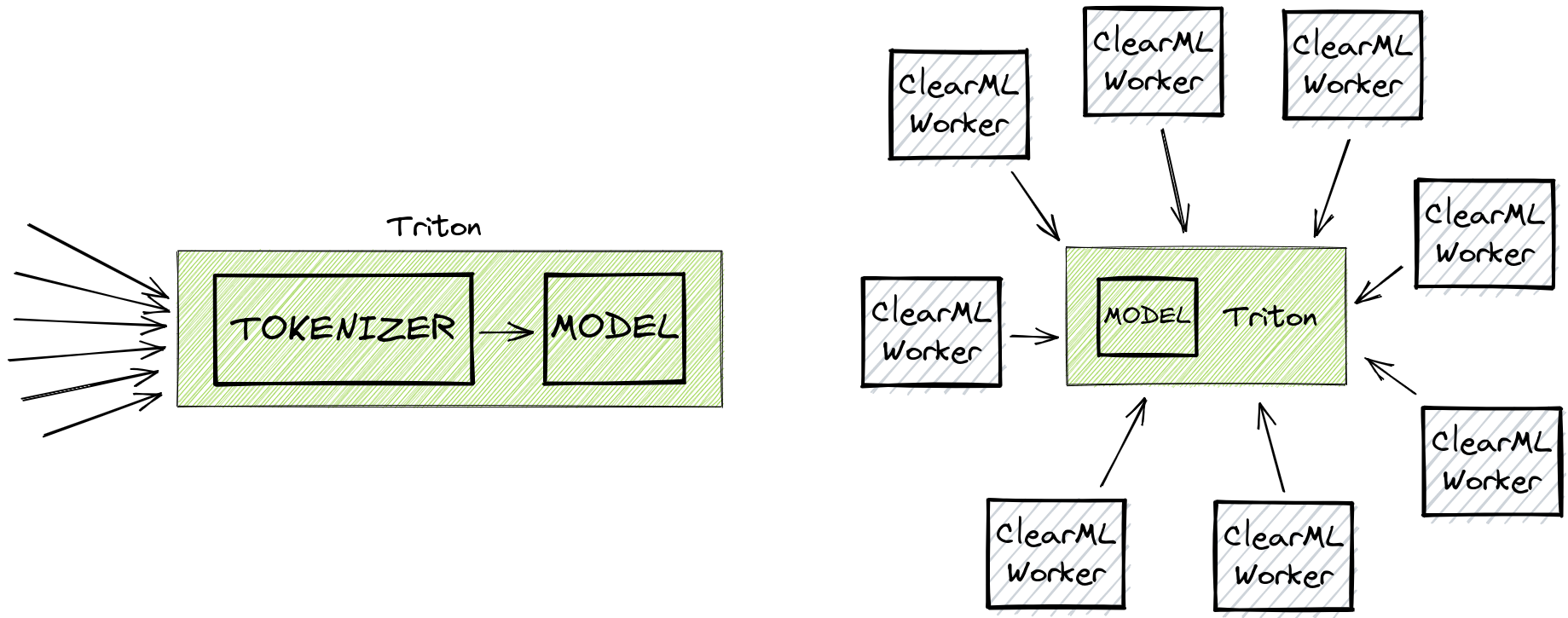
Essentially, what this means is that at a certain scale, ClearML Serving starts outscaling its overhead, essentially giving you all its extra features for free!
Conclusion
To deploy at scale, there are quite a few things more to take into account than purely single request latency. The authors of the Transformer-Deploy blogpost and repository have done an excellent job in providing a framework in which to optimize Huggingface models for production. In this blogpost, we took it one step further and showed just how much performance you can expect from these models in a more realistic production scenario.
We’ve shown that you don’t necessarily need to lose performance to get quality of life features like seamless model updates, monitoring and end-to-end workflow integration. As long as your models are deployed at scale, that is.
Again, the code to recreate this example yourself can be found here
If you’re interested in checking this out for yourself, go to our ClearML serving github and give it a spin! If you need any help, feel free to join our Slack channel and our community will be glad to help you out!