Hyper-Datasets
Hyper-Datasets are available under the ClearML Enterprise plan
ClearML's Hyper-Datasets are an MLOps-oriented abstraction of your data, which facilitates traceable, reproducible model development through parameterized data access and metadata version control.
Hyper-Datasets is a data management system specifically tailored for handling unstructured data, like text, audio, or visual data. You can create, manage, and version your datasets. Datasets can be set up to inherit from other datasets, so data lineages can be created, and users can track when and how their data changes. In the ClearML Enterprise's WebApp, you can view a dataset's version history, as well as its contents, including annotations, metadata, masks, and other information.
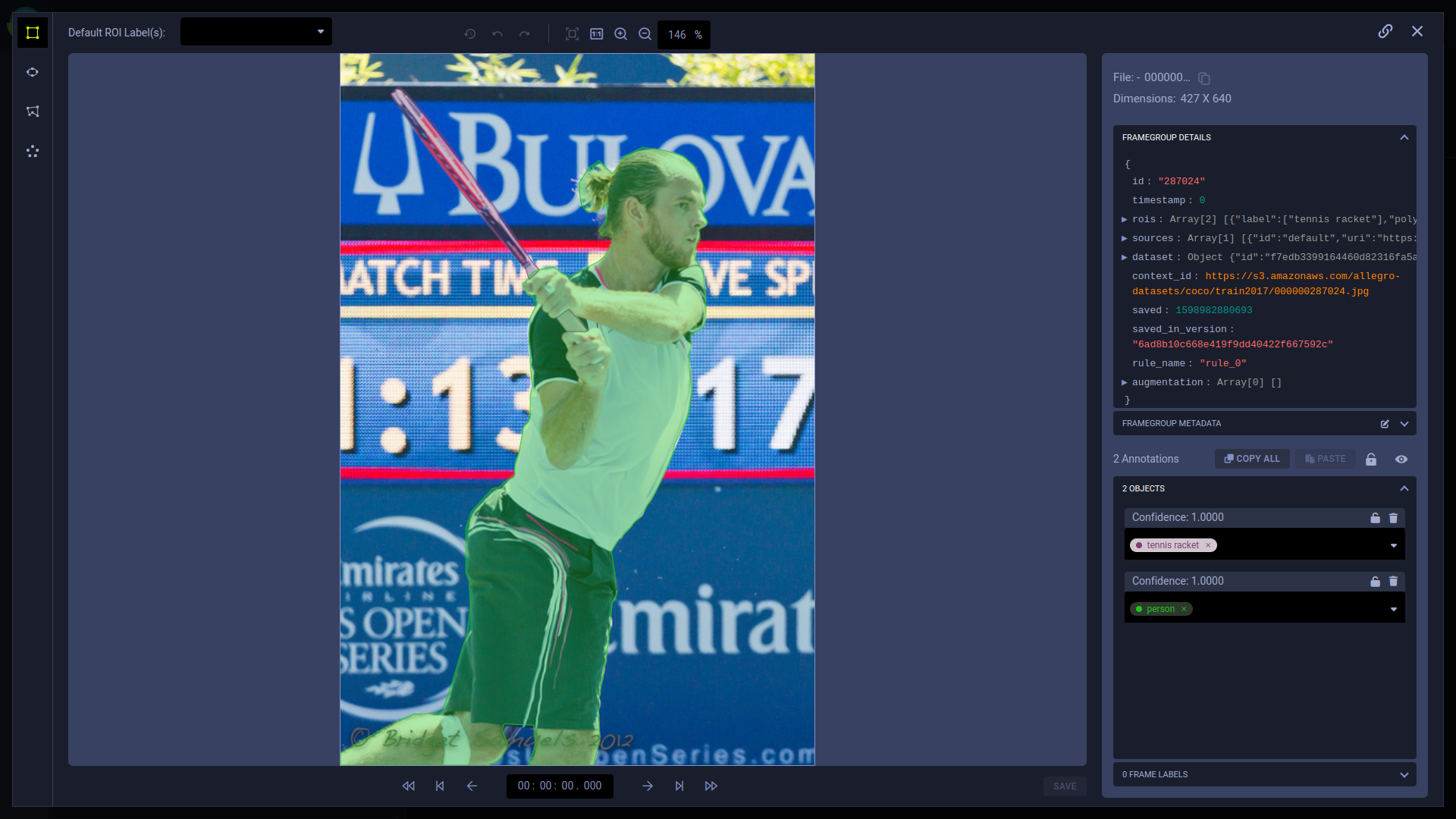
The basic premise of Hyper-Datasets is that a user-formed query is a full representation of the dataset used by the ML/DL process. Hyper-Datasets decouple metadata from raw data files, allowing you to manipulate metadata through sophisticated queries and parameters that can be tracked through the experiment manager. You can clone experiments using different data manipulations--or DataViews--without changing any of the hard coded values, making these manipulations part of the experiment.
ClearML Enterprise's Hyper-Datasets supports rapid prototyping, creating new opportunities such as:
- Hyperparameter optimization of the data itself
- QA/QC pipelining
- CD/CT (continuous training) during deployment
- Enabling complex applications like collaborative (federated) learning.
For more information, see Hyper-Datasets.