TL;DR
- A detailed overview and breakdown of the MLOps landscape including ClearML and other market players.
- As in data ingestion, ClearML is largely agnostic about how data gets in or its format and is focused more on what can be done with this data once it becomes available.
- ClearML places a lot of focus and capabilities within pipelines/queue management and data versioning/storage.
(Yet Another) Product Comparison Chart
One of the most leading questions we often receive is, “How does ClearML Compare to..”. I am sure this is the same for any Open Source product. People always want to find the best. The sad truth is, of course, there usually is no “right answer”. What one person needs, another may not. I am sure that, whichever language you speak natively, there is some saying. In English it would be “one mans rubbish, is another mans gold”. Obviously, not the best title for a blog talking about comparison of friendly rivals. The short version of the matrix is this
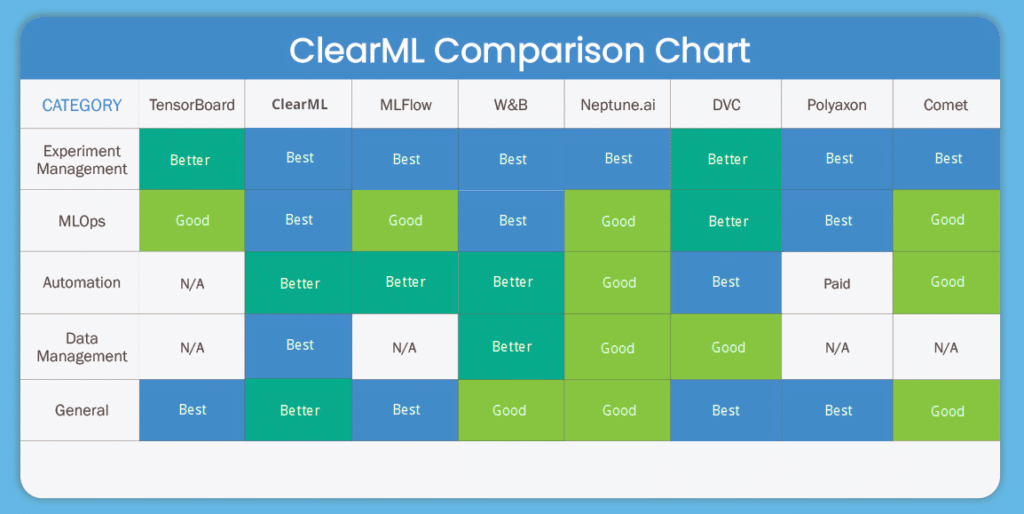
However. You will notice that there are certain fields missing that others may use when comparing themselves with us. That’s to be expected, mostly because we focus on different areas. The classic example would be data ingestion. We are largely agnostic about how your data get’s in (or indeed, what format it is). Companies like SuperWise are deeply concerned about this. Compared to them, we would seem to be missing a lot of features. We like to think though, that the fun starts after your data is ingested, not before. This is why we get along so well.
Of course, we do have friends in the same category as us. Companies who compete with us, in the best possible way, and those are the ones listeed in the comparison chart. I suspect some explanation as to why we came to those categories above though, would be useful. Prepare yourselves though, this may get long. See you after the chart
| Category | Feature | TensorBoard | ClearML | MLFlow | W&B | Neptune.ai | DVC | Polyaxon | Comet |
|---|---|---|---|---|---|---|---|---|---|
| Experiment Management | Experiments comparison | M | H | H | H | H | M | H | H |
| Experiment parameters logging | M | H | H | H | H | H | H | H | |
| Environment logging | L | H | L | L | L | L | L | L | |
| Integration simplicity | M | H | M | M | M | M | M | H | |
| Artifacts support | M | H | M | M | H | H | H | M | |
| Search capabilities | L | H | M | H | H | L | H | H | |
| MLOps | Containers support | L | H | L | H | L | H | L | |
| Cloud provider agnostic | L | H | H | M | H | H | H | L | |
| Cloud machine monitoring | L | H | L | H | M | L | |||
| Machines status monitoring | L | H | L | H | M | L | H | ||
| Queues management | L | H | L | L | L | H | H | L | |
| Data caching | L | H | L | L | L | L | L | L | |
| Model Serving | L | L | L | L | L | L | L | H | |
| Environment Reproduction | L | H | L | L | L | M | L | L | |
| Automation | Pipeline automation | NA | H | M | M | L | H | Paid | L |
| Hyper parameters optimization | NA | H | M | M | L | L | H | H | |
| Cloud machines automation (spin up/down) | NA | M | L | L | L | L | H | L | |
| Alerts (Slack) automation | NA | M | L | H | M | L | H | L | |
| Remove | CI/CD automation | H | L | L | L | H | |||
| Data driven events automation | NA | M | L | L | L | L | L | L | |
| Data Management | Data visualization | NA | H | NA | M | L | L | NA | NA |
| Data versioning | NA | H | NA | M | M | H | NA | NA | |
| Data annotation | NA | M | NA | L | L | L | NA | NA | |
| Data conforming | NA | H | NA | L | L | L | NA | NA | |
| Data querying | NA | H | NA | M | L | L | NA | NA | |
| Cloud storage support | NA | H | NA | H | H | H | NA | NA | |
| General | Open source | H | H | H | L | L | H | H | L |
| User management | M | L | H | H | L | Paid | M | ||
| Full API | M | H | H | H | H | H | H | ||
| Support R | L | L | H | L | H | H | L | H | |
| Reports | L | L | L | H | H | L | L | H |
Details, details, it’s all in the details.
*Phew* Okay. so. That’s a lot to take in. Hopefully you can see from the above comparison matrix, that we put a lot of our focus on around Pipelines/Queue Management and Data versioning/storage. Polyaxon by contrast, puts more focus into automation of machines. Earlier I did mention, and it’s worth repeating, that this is due to different focus from different companies. It’s not to say that one is worse than the others, merely to show where focuses align, or differ.
In conclusion, I think (or hope rather) that this is a fair overview of the landscape which is MLOps. It’s a growing and evolving field, and I dare say that in time, most MLOps tools will expand beyond this comparison. I know that we here at ClearML, are looking towards deployment as the next area of improvements. For us here, it’s always onwards, always upwards and always learning. I assume the same is true for most in the MLOps family.