Now you can create and manage your control plane on-prem or on-cloud, regardless of where your data and compute are.
We recently announced extensive new orchestration,scheduling, and compute management capabilities for optimizing control of enterprise AI & ML. Machine learning and DevOps practitioners can now fully utilize GPUs for maximal usage with minimal costs. Now, with GPU fractioning/MIG offering, multiple workloads can share the compute power of a single GPU based on priorities, time slicing ratios, or upper hard limits. Global ML teams using these capabilities report they can better control compute costs and GPU utilization while expediting time to market, time to revenue, and time to value. Read the news release.
ClearML’s newest capabilities bridge the gap between machine learning teams and AI infrastructure by abstracting infrastructure complexities and simplifying access to AI compute. Customers can now take advantage of the industry’s most advanced orchestration, scheduling, and compute available to manage and maximize GPU utilization and allocate resources effectively. These enhancements include:
Optimal Utility
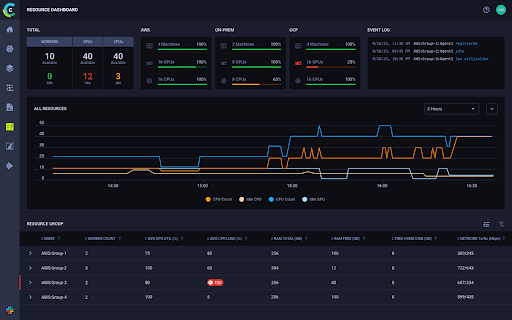
To enable customers to better visualize, manage, and control resource utilization more effectively, ClearML has rolled out a new Enterprise Cost Management Center that intuitively shows DevOps and ML Engineers everything that is happening in their GPU cluster and offers teams a better way to manage job scheduling and maximize fractional GPU allocation and usage as well as project quotas.
For example, companies will be able to better understand their GPU usage on NVIDIA DGX™ or DGX™ Cloud machines to maximize utilization of resources and manage costs. In addition, customers can now manage the provisioning, splitting, scheduling, pooling, and usage of GPU resources.
GPU management is critical for companies from a resource allocation and budgeting point of view. By pooling or splitting GPUs to run multiple models on a single GPU, companies can more efficiently serve end users and control costs. Our enhanced GPU-handling capabilities, bundled with a robust enterprise cost management center, provide customers with improved AI and ML orchestration, compute, and scheduling management as part of the ClearML MLOps platform – which, right out of the box, replaces the need for a stand-alone orchestration solution while simultaneously encouraging ML and data science team members to self-serve. Engineers now have built-in capabilities to monitor, control, and provision compute resources more easily than ever.
ClearML is certified as an NVIDIA AI Enterprise Partner with the ability to run NVIDIA AI Enterprise, an end-to-end platform for building accelerated production AI. The ClearML platform is fully compatible and optimized for NVIDIA DGX™ systems and NVIDIA-Certified Systems™ from leading server manufacturers. This compatibility enhances workflow efficiency and GPU power optimization, aiding companies in maximizing their ML investments.
Extensive Flexibility
ClearML ensures that DevOps and ML Engineers do not need to be engaged for every user requiring a machine when using ClearML’s permissions settings, credentials management, and automatic provisioning. The event history for every cluster is automatically logged for easy auditing and overall governance.
Also, ClearML’s policy management provides DevOps Engineers with easy tools for managing quotas and GPU over-subscription, in addition to job scheduling and prioritization.
Massive Scalability
In addition to helping companies manage their on-premise compute usage, it should be noted that ClearML’s Autoscaler capabilities already enable companies to manage cloud and hybrid setups more efficiently, using automatically provisioned cloud machines only when and as needed. For cost management, teams can set budgets for resource usage, with limits set by types, nodes, and idle timeout. Even provisioned GPUs can be automatically spun down if the machine has been idle for a predetermined amount of time, saving energy and costs. Extra budget-conscious teams also have additional options to ensure that cloud machines use spot instances or are not zone limited, with automatic re-spinning when spots are lost, seamlessly continuing running jobs without any external intervention.
For cloud or cloud hybrid setups, ClearML’s Autoscaler and Spillover features allow enterprises to closely manage budgets and costs. When jobs scheduled exceed the existing on-premise GPU resources available, Spillover enables secure usage of cloud compute. The Autoscaler function (which can be used with or without Spillover) automatically provisions machines in the cloud to run the jobs and spins them down once idle, preventing wastage costs. For additional cost control and availability options, teams can set whether the jobs run on regular or spot instances and are not zone limited.
ClearML provides seamless, end-to-end MLOps and LLMOps, with full orchestration, scheduling, and compute management integrated into the entire AI/ML lifecycle. In this way, ClearML supports and serves entire AI, ML, and Data Science teams, unlike other solutions that only serve DevOps with no secure built-in ML/DL tracking and monitoring capabilities for other team members.
In addition, ClearML can be installed on top of Slurm, a widely used free and open-source HPC solution, as well as Kubernetes and bare metal, for managing scheduling and compute. ClearML is also completely hardware-agnostic and cloud-agnostic, maximizing the freedom of companies in choosing and using their vendors and optimizing costs by allowing hybrid on-prem / cloud combinations.
AI Infrastructure for DevOps
DevOps teams can also ensure GPU resources are fully utilized by allocating GPU fractions, managing oversubscription, consolidating, and more closely managing scheduling and priority. With ClearML, teams have full control over job prioritization as well as job order within queues or quotas through the policy manager. By creating automations to more efficiently manage jobs, the DevOps team gains significant time and energy savings.
With orchestration and scheduling powering ClearML’s core AI/ML platform, accessing compute resources is simplified for both users and admins. Built with enterprise-grade security in mind, the ClearML platform features role-based access control. When coupled with project-level user credentials, ClearML automatically provisions pre-configured machines for users that need them for data pre-processing, model training or model serving. Model deployment autoscaling is automatic for natively integrated inference servers, with support for both CPU & GPU dedicated nodes. If you do not have an AI/ML platform, or are re-evaluating your toolkit, have a look at the landscape of AI/ML solutions assembled by the AI Infrastructure Alliance.
ClearML also provides transparency and full provenance for model governance. Every event for every cluster is automatically logged for easy auditing. ClearML is fully open source and extensible, and can be installed on the cloud, VM, bare metal, Slurm or Kubernetes. ClearML supports Vanilla Kubernetes, OpenShift, and RancherOS. The platform is also hardware-agnostic and cloud-agnostic, allowing enterprises the freedom to choose their own infrastructure vendors and optimize for hybrid on-prem / cloud combinations.

If your company needs to better manage its GPU compute resources to save time, optimize utilization, and power your AI/ML initiatives, request a ClearML demo today: