Allegro Trains will take you out of the village!
Republished here with the author’s permission – original post on Medium.
Authored by Henok Yemam.
The recent global pandemic caused by the COVID-19 virus has threatened the sanctity of our humanity and the well-being of our societies at large. Similar to times of war, the pandemic has also given us the opportunity to appreciate the things we take for granted such as health workers, food suppliers, drivers, grocery store clerks and many others who are in the frontlines keeping us safe at this difficult time, Salute! While they are out fighting the good fight on our behalf, how about you and I get some work done?
Unfortunately, the pandemic has also brought us domain deficient insights from data scientists which are becoming pervasive. Therefore, I want to avoid similar pitfalls which is why I start with the following disclaimer. The purpose of this blog is to demonstrate how you can use Allegro Trains for managing your machine/deep learning project to increase your productivity and improve workflow.
First Stop: Exploring the Dataset
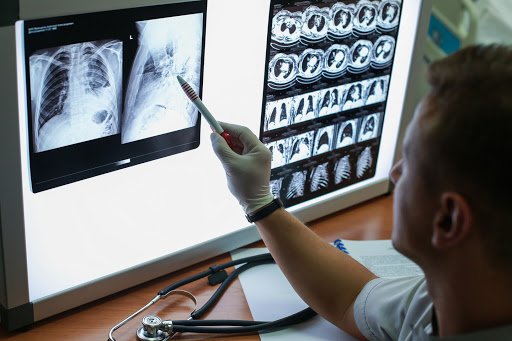
I have two reasons why I chose this COVID-19 chest xray dataset (figure 1 & 2). First, it’s fairly small and ties to current events so you will be able to follow me with ease. Second, the dataset contains numerical and categorical features on top of X-ray/CT scans of lung inflicted patients so that we can apply both traditional machine learning solutions as well as neural networks. Any insights or observations from this blog shouldn’t be used to make any decision with the exception of the stated objective. With that in mind, thanks for joining me on my second ride of Allegro Trains.

Second Stop: Assembling the little parts
Heterogeneous datasets like the one above have become common as the sophistication of data engineering pipelines, storage and computing power skyrocket. With that comes the potential to uncover insights using data pipelines, a plethora of algorithms and data processing techniques. It also presents us with a unique problem of managing exciting experimentations under one umbrella. This could mean bringing a team of data scientists to massage and experiment data, machine learning and data engineers to deliver deployable models which are portable, scalable and operational. It takes a whole village to build a model!
The common steps taken before deploying a machine learning model include ingesting data, creating a group github repository for versioning, data wrangling and experimentation done locally or on the cloud, collaboration by installing dependencies to reproduce your colleagues result, figuring out the best model which is no easy task of its own, packaging the model and so on and so forth. If you are starting to pick up the emerging pattern which is the need for a high-level machine learning infrastructure or hub, then you may be onto something. Allow me to present to you the ML/DL project management system that takes care of your version control needs, automated code and experiment tracking, model quality control and performance logging of your experiments even at the machine level. Buckle up, Allegro Trains will take you out of the village!

Step Three: Focusing on the research problem
But first, let’s get back to the important question at hand. We may be able to figure out the best attribute that can predict survival rate in a patient inflicted with COVID-19. Is it age? Sex? Diagnosis modality? The speciality of the health worker who made the diagnosis? We also have the X-ray/CT scans which show the progress of the disease. In real life, we would need health professionals to give us the necessary domain-knowledge to figure out the best possible route but for now, the best we could do is data wrangling and visual exploration, resizing and encoding the images, and featuring engineering to get the data ready for modeling. I chose to experiment with Scikit’s random forest and Xgboost ensemble learning methods to determine the most relevant features for survival rate. Note that accuracy is not a good performance metric here because the data is not balanced and doesn’t contain the scans of healthy individuals. Therefore, we could use the ROC curve instead to determine the best model. If we were to be more stringent with our metric optimization, minimizing false negatives or maximizing our recall would be our priority. I also experimented with multiple architectures and transfer learning models to predict prognosis from the X-ray/CT scans of the patients based on convolutional neural networks. As you can imagine, each architecture came with its own hyperparameters to tune and performance to track. If you are starting to feel slightly overwhelmed by the number of potential experiments, worry not! We will leverage Trains so we focus on the most important task at hand which is answering our research question.
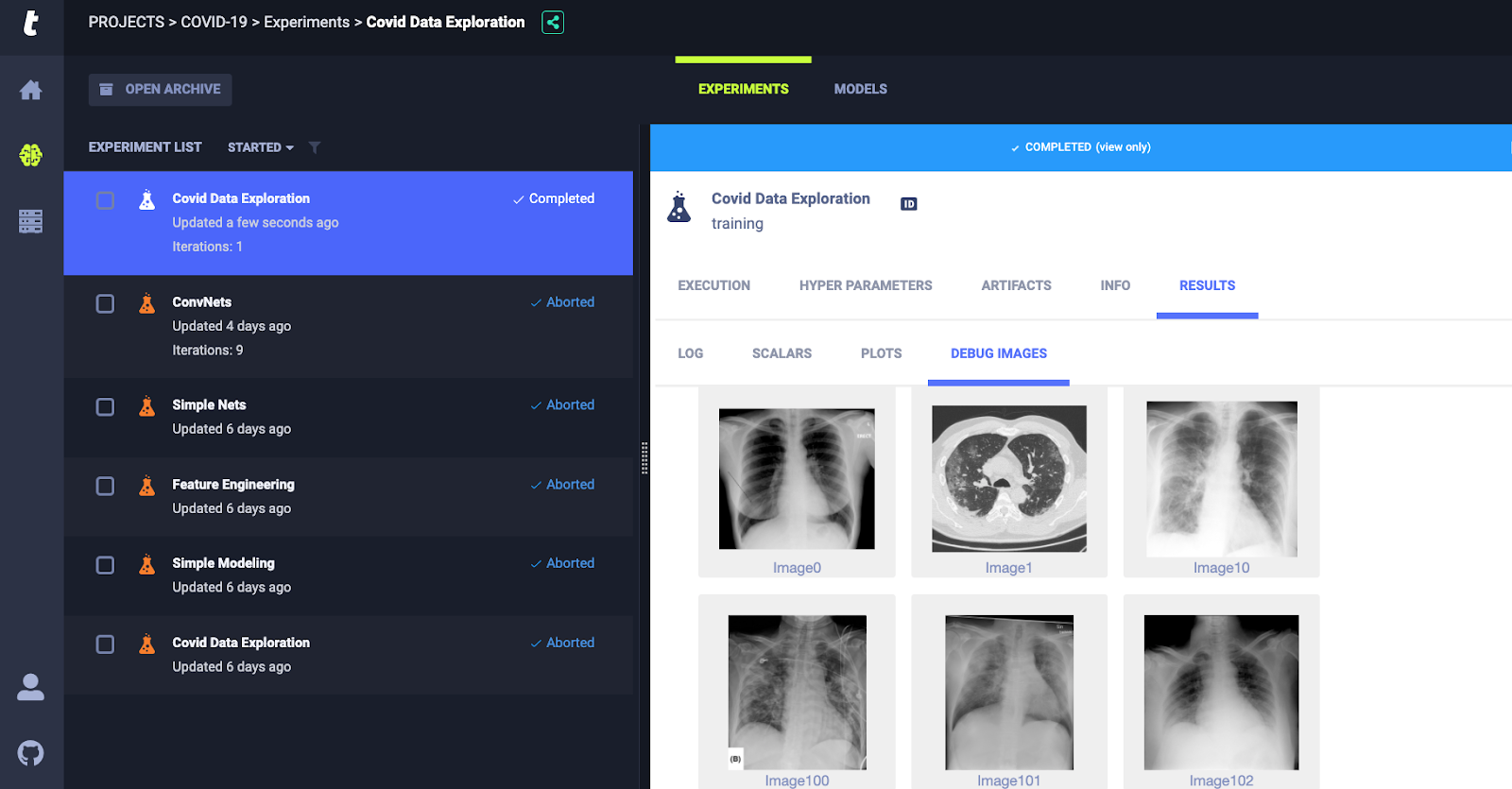
I started my project by setting up my own server locally so that Allegro Trains could track our experiments as shown in figure 1. Trains took care of the environment replication and logging automatically while tracking the performance metrics of our fledgling models and also the machine resource allocation of each model such as GPU, CPU, IO speed etc. This is important because we don’t want to pick the best model based on just a single metric. There is also the option of using Allegro AI’s web-based demo server which lets you track your ML projects for 24h but I wouldn’t recommend it because you simply can’t finish an ML project in a single day. I used Keras as my choice of deep learning framework but Trains comes with builtin support for Pytorch and of course Tensorflow as well. Trains is also tracking the packages so we can collaborate and replicate each other’s work.
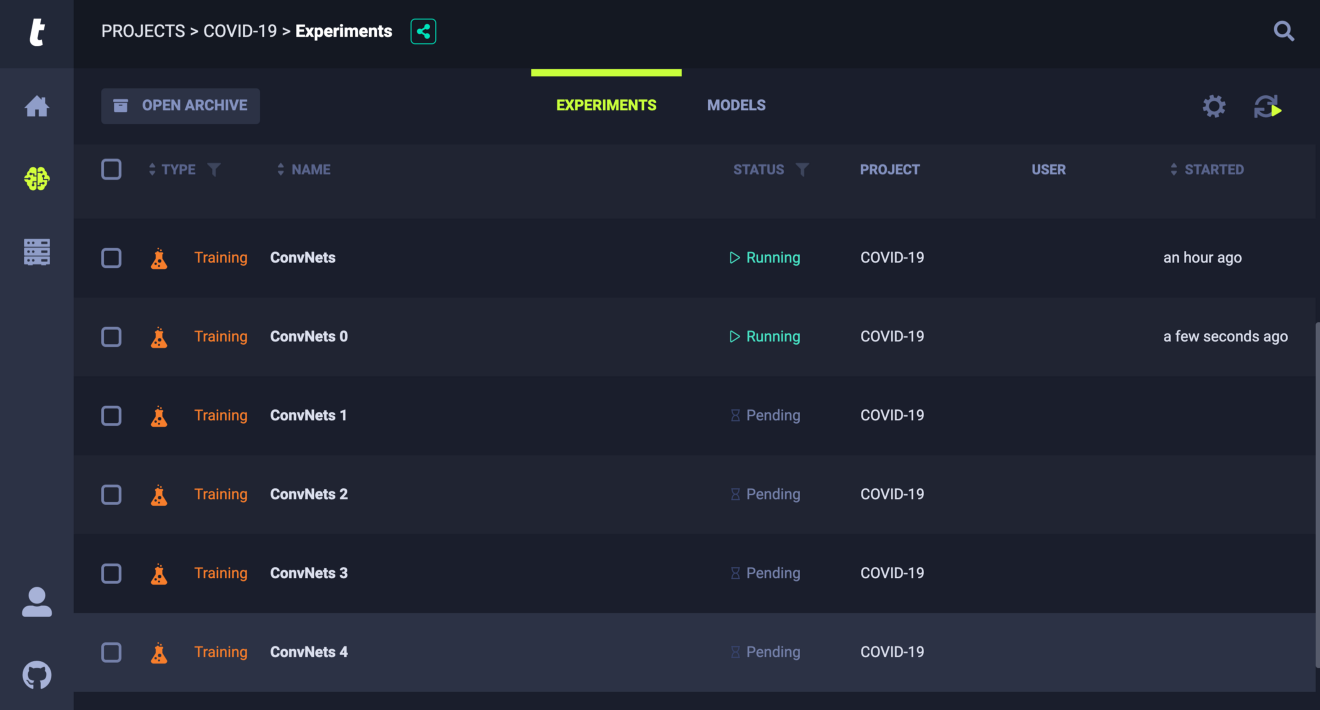
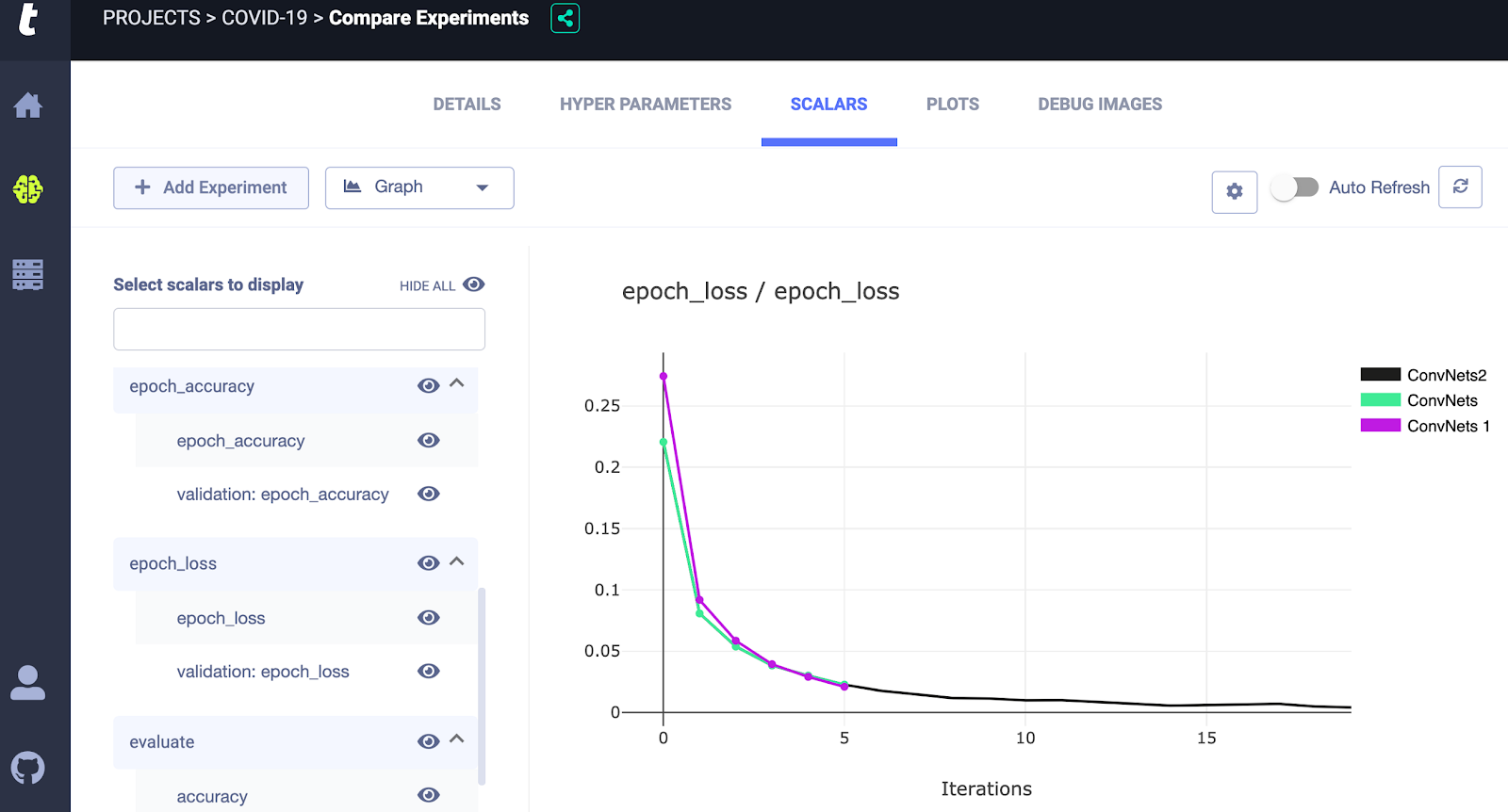
Part 4: Summarizing the findings
Look above for the results of the AutoML experimentations I performed using Allegro Trains. Creating individual notebooks for each of these experiments or versioning each output would have led to project cluttering and confusion. But here, I am able to simply compare the performance of the convolutional neural networks based on several metrics including epoch vs loss optimization and GPU usage. This type of abstraction of project management system simply leads to more data-driven decision making. I was able to accurately determine 85% of the surviving members of the patients and it turns out age was the most important factor. The resource allocation for neural networks was way more than the grid search for the tree-based algorithms. Also, random forest performed better than Xgboost which was to be expected due to the small dataset.
It’s a pleasure giving you a high-level overview of how you can tackle complex datasets with ease by automating your experiments under the same hub. I bet your iteration speed, workflow and experimentation would drastically improve with Trains as your project management hub. Make sure to check out my part 1 mini-series on how Trains fared relative to GitHub.
As for me, I have arrived at my stop. It has been a pleasure giving you a brief taste of Trains and AutoML. It’s my hope that I will hear the wondrous journey you take Allegro Trains for your deep learning project needs, feel free to add me on LinkedIn or give me a shoutout on Twitter. Take care!