If you’ve been following our news, you know we just announced free fractional GPU capabilities for open source users, enabling multi-tenancy for NVIDIA GPUs and allowing users to optimize their GPU utilization to support multiple AI workloads as part of our open source and free tier offering. With this latest open source release, you can now optimize your organization’s compute utilization by partitioning GPUs, run more efficient HPC and AI workloads, and get better ROI from your current AI infrastructure and GPU investments.
Global enterprise AI projects are being slowed and stalled by legacy AI infrastructures that cannot adequately support the modern GPU-accelerated computing and performance-intensive AI and HPC workloads required for deep learning and Generative AI business use cases. ClearML is committed to creating novel solutions at the intersection of compute, infrastructure, and AI that help our open source community and global customers seamlessly scale AI and ML projects while optimizing GPU utilization at any scale and overcome complex challenges.ClearML’s latest open source release marks a significant stride towards democratizing computational resource optimization and utilization, setting a new standard for AI development’s efficiency, cost, and accessibility.
Moses Guttmann, ClearML’s CEO and co-founder, announced our latest leap forward at the NVIDIA GTC conference today, unveiling this open source solution that unlocks fractional GPU usage across the widest selection of NVIDIA GPUs available on the market.
“This groundbreaking move by ClearML is all about making high-end computing power more efficient and universally accessible for everyone. It’s a testament to our dedication to fueling innovation within our community, enabling the creation of superior AI technologies swiftly and at any scale,” Guttmann said. “Our aim is to empower all organizations, including organizations and researchers with limited resources, to harness ClearML’s open source fractional GPU offering to its full potential. We’re eager to see everyone maximize their existing computational power investments and resources, pushing the boundaries of what they can achieve with what they already own for a fraction of the cost.”
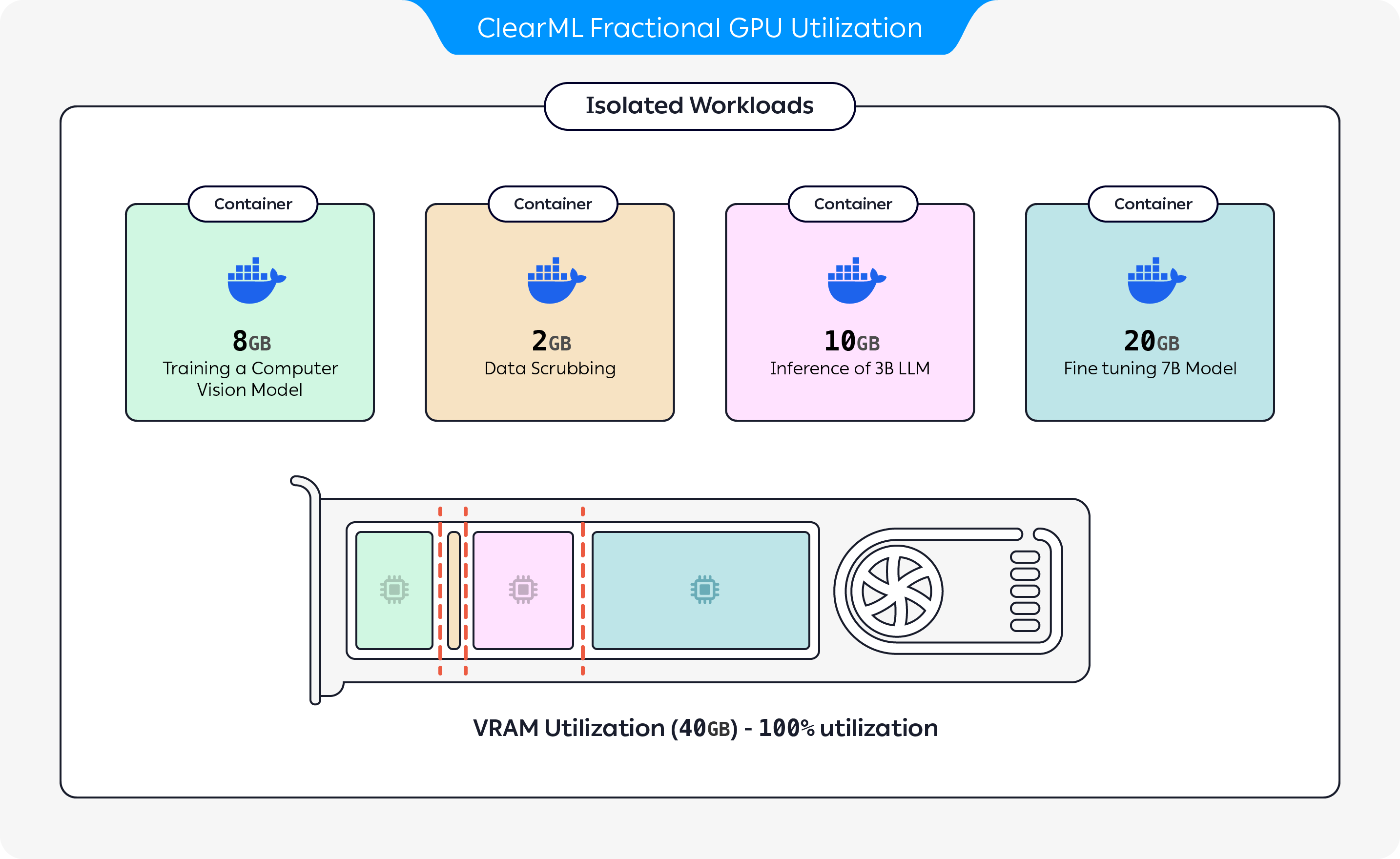
Machine learning and AI Infrastructure leaders can take advantage of NVIDIA’s time-slicing technology to safely partition both non-MIG NVIDIA cards GTX™, RTX™, and datacenter-grade, as well as MIG-enabled GPUs into smaller fractional GPUs to support multiple AI (Artificial Intelligence) and HPC (High-Performance Computing) workloads without the risk of failure. That means utilizing NVIDIA’s advanced GPU technology to divide the processing power and resources of a single GPU into several smaller, independent units. This process allows different tasks or applications, particularly those requiring AI or HPC capabilities, to run concurrently on the same physical GPU hardware. Here’s a breakdown of what this entails:
NVIDIA’s Time-Slicing Technology: This is a sophisticated mechanism that enables the GPU to allocate its resources across different tasks in a time-shared manner. Time-slicing ensures that each task gets a fair share of the GPU’s computational power, memory, and other resources within a specified time frame, which can improve overall utilization and efficiency.
Partitioning into Fractional GPUs: The process divides a single, powerful GPU into multiple virtual or fractional GPUs. Each fractional GPU operates as if it were a separate, smaller GPU, allowing multiple applications to run simultaneously without interference from one another, or using excessive memory.
Support for Multiple Workloads: By partitioning GPUs, it becomes possible to run various AI and HPC applications at the same time. AI workloads might include machine learning model training and inference, while HPC workloads could involve complex scientific simulations, data analysis, or other computationally intensive tasks.
Safety and Risk Mitigation: One of the key benefits of using NVIDIA’s technology for GPU partitioning is the ability to maintain stability and reduce the risk of failures that could disrupt critical processes. Our technology ensures that the demands of one partitioned GPU do not adversely affect the performance or reliability of others, with driver-level memory guardrails, each container has its own memory isolation and execution environment, ensuring maximum stability of the entire system.
Compatibility with NVIDIA GPUs: ClearML’s open source capabilities are compatible with a range of NVIDIA GPUs, including GTX™ (consumer-grade gaming GPUs), RTX™ (advanced gaming and professional graphics GPUs), non-MIG GPUs (GPUs that do not support Multi-Instance GPU technology for more granular partitioning), and datacenter-grade MIG enabled GPUs (high-performance GPUs designed for server environments).
In summary, leveraging NVIDIA’s time-slicing technology for GPU partitioning with ClearML’s Fractional GPU capabilities allows organizations and individuals to maximize their compute while preserving system stability with memory guardrails, to fully utilize GPU investments. It enables more efficient processing for diverse AI and HPC applications, enhances resource utilization, and ensures the reliable operation of critical tasks by minimizing the risk of computational failures. This approach is particularly beneficial in environments where high-performance, reliability, and efficient resource management are paramount.
Why We Created This Capability: The New Era of AI Demands More from GPUs
Gone are the days when AI and machine learning tasks could run smoothly on standard GPU setups. Today, there are often multiple AI, machine learning, and data science teams within a single organization who need access to compute, and the emergence of Generative AI has changed the game by demanding significantly more computational power. This new breed of AI thrives on dedicated AI infrastructures capable of delivering instant results with minimal delay.
Faced with the need for more computational power, companies find themselves at a crossroads. The ideal path to increase computing capabilities without expanding existing infrastructure remains elusive. This dilemma leaves many with tough choices: either invest in additional computing resources or delay projects to manage within the limits of current capacity. Both options come with their downsides, including increased costs and the potential loss of a competitive advantage and time to market due to slower project turnaround times.
ClearML’s own research proves this out: in a recent survey conducted on the State of AI Infrastructure in 2024, 96% of respondents said they are planning to expand their AI compute infrastructure, underscoring a strain on resources. 67% of respondents said they managed GPU usage through queue management and job scheduling, with only 39% of respondents using multi-instance GPUs.
So now the pressure is on to find a way to squeeze more power out of current setups. Without a viable solution to enhance computing capacity efficiently, organizations risk falling behind. Companies must navigate these waters carefully, balancing the need for technological advancement with the practicalities of infrastructure limitations and budget constraints.
The good news is that now with the general availability of ClearML’s new open source fractional GPUs, countless organizations of all sizes will be able to get more from their current compute setup. We’ve stepped up the game by opening up the capability to support multi-job with partitions that guarantee a secure and private computing experience. Each partition is equipped with its own dedicated memory, paving the way for consistent and reliable performance across the board.
ClearML employs driver-level memory guardrails, a strategy designed to ensure that different tasks run seamlessly alongside each other without any interference. This advanced monitoring system is the backbone of the platform’s ability to maintain high performance while processing multiple jobs simultaneously.
With the latest update, ClearML sets a new standard for privacy and efficiency in computing. The introduction of secure partitions with dedicated memory means that users can enjoy a worry-free computing environment where performance is never compromised. ClearML ensures that all tasks execute flawlessly, free from the risk of impacting one another. This level of oversight is crucial for maintaining the platform’s integrity – not to mention user satisfaction.
Try Now
To learn more about ClearML’s free open source GPU capabilities, check it out on our GitHub repo. Get started with ClearML by using our free tier servers or by hosting your own.
BACKGROUND
What is GPU Partitioning and Why Is It Important?
GPU partitioning is a technology that allows the resources of a single Graphics Processing Unit (GPU) to be divided into smaller, isolated partitions with a dedicated “chunk” of GPU allocated for them. This enables multiple applications or containers to share a single physical GPU, with each having access to a portion of the GPU’s resources, such as its compute units, memory, and so on.
The purpose of GPU partitioning is to enhance resource utilization and efficiency, especially in environments where multiple tasks or users need access to GPU acceleration but don’t require the full capabilities of a dedicated GPU. By partitioning a GPU, administrators can optimize hardware usage, reduce costs, and ensure that resources are allocated according to the needs of different applications or users.
GPU partitioning is particularly relevant in cloud computing, data centers, and server environments where virtualization is common. It supports scenarios such as virtual desktop infrastructure (VDI), gaming, professional graphics applications, and machine learning workloads, enabling more flexible and efficient use of GPU resources.
Key benefits of GPU partitioning include:
- Improved resource utilization: By dividing a GPU into smaller units, it ensures that the GPU’s capabilities are fully utilized, reducing idle times.
- Cost efficiency: Organizations can save on hardware costs by maximizing the use of existing GPUs instead of purchasing additional units.
- Flexibility and scalability: Partitioning allows for dynamic allocation and reallocation of GPU resources based on changing workload demands.
- Isolation: Each partition can operate independently, ensuring that the activities in one partition do not interfere with those in another, which is crucial for security and performance consistency.
Open Fractional GPUs Have Additional Benefits
Open GPU partitioning is important for several reasons, offering benefits to individuals, organizations, and the broader technology community by fostering innovation, inclusivity, and cost efficiency. Here are some key reasons why open source GPU partitioning is significant”
- Accessibility and Inclusivity: Open GPU partitioning solutions make advanced GPU technologies accessible to a wider audience, including small organizations, researchers, and hobbyists who may not have the budget for expensive proprietary solutions. This inclusivity fosters a diverse community of users and developers, contributing to more innovative and varied use cases.
- Transparency and Trust: Open source projects are characterized by their transparency, allowing anyone to inspect, modify, and enhance the source code. This transparency helps build trust among users, as they can verify the security, efficiency, and fairness of the resource allocation algorithms used in the partitioning.
- Customization and Flexibility: With access to the source code, organizations and individuals can customize the GPU partitioning software to meet their specific needs, whether that’s optimizing for certain types of workloads, improving performance, or enhancing security features.
- Cost Efficiency: Open source solutions can significantly reduce costs associated with GPU virtualization and partitioning. Organizations can avoid the licensing fees associated with proprietary solutions and can contribute to or benefit from community-driven enhancements, reducing the need for expensive in-house development.
- Collaboration and Community Support: Open source projects benefit from the collective expertise and contributions of a global community. This collaborative environment accelerates innovation, as developers from diverse backgrounds contribute improvements, features, and fixes. Users can also receive support and advice from the community, enhancing their ability to deploy and manage GPU partitioning effectively.
- Education and Research: Open GPU partitioning tools serve as valuable resources for education and research, allowing students, educators, and researchers to study, experiment with, and develop advanced computing solutions without commercial constraints. This openness supports the advancement of knowledge and the training of the next generation of computer scientists and engineers.
- Driving Standards and Interoperability: Open source projects often play a crucial role in establishing industry standards and promoting interoperability between different systems and technologies. By providing a common framework for GPU partitioning, open source projects can help ensure compatibility and ease of integration across various platforms and environments.
Overall, open GPU partitioning embodies the principles of open innovation, collaboration, and democratization of technology, enabling more equitable access to advanced GPU capabilities and encouraging the development of creative and efficient solutions in computing.