Improving patient care is right up there with the importance of optimizing the allocation and efficiency of precious resources when it comes to today’s healthcare. But that’s been difficult for people alone to accomplish, even with automation. The good news is that machine learning is now addressing these challenges and a company called Iodine Software is leading the innovation.

The company has pioneered a new approach called CognitiveMLTM, which uses proprietary AI technology and machine learning (ML) algorithms to generate real-time, highly focused, predictive insights that clinicians and hospital administrators can leverage to dramatically augment the management of care delivery – facilitating critical decisions, scaling clinical workforces through automation, and improving the financial position of health systems. The Company’s platforms are trusted by more than 700 hospitals and are used by more than 2,500 healthcare providers nationwide.
How Iodine Works
We recently sat down with Jon Matthews, Director of Data Science at Iodine, to talk about how the company is using machine learning to provide AI-enabled intelligent care. “Iodine offers an advanced AI engine in the clinical documentation space that enables hospitals and healthcare providers to fully specify the conditions of the patients they are treating, which allows the patient record to be complete and accurate. As a result, hospitals are then able to be reimbursed for everything they are providing for the patient,” he said.
By combining machine learning with natural language processing, Iodine is able to surface advanced insights from clinical data that were simply not possible before. Healthcare organizations use these insights to become more efficient, more resilient, and deliver a higher standard of care to their patients. To do that, Iodine employs a team of seven full-time data scientists who are responsible for maintaining more than 150 machine learning models. Some of these models are known as condition models, which take the outputs from their NLP system that extracts symptoms and diagnoses along with summarized lab results, orders, medication, and other data to predict whether a patient actually has a medical condition.
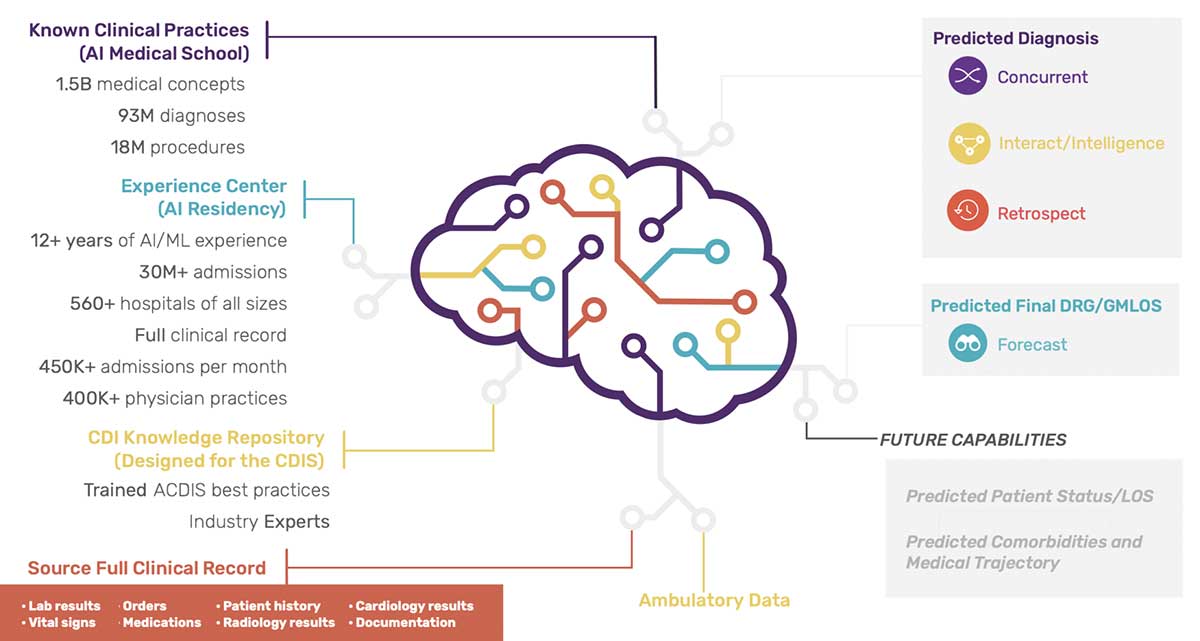
Matthews explains how it works: “There are two major model loops; one that analyzes text and extracts data, and a tabular model that does the actual predicting of whether someone has a condition. There is a third class that uses CNNs and RNNs along with that tabular data to predict more complex medical conditions.”
Iodine employs a team of seven full-time data scientists who are responsible for maintaining more than 150 machine learning models.
Iodine’s systems receive a continuous stream of data from their client hospitals’ EMR (electronic medical records). The company’s data pipelines process and clean up the data and run the models, which are output to a web app. Matthews noted that the software prioritizes which cases need to be reviewed by clinical improvement specialists, which is typically when there are conditions that are not fully documented and may need further information.
“We have a policy that anything that goes into production has to be created in ClearML,” Matthews said. “That allows us to keep the code together. We store all the data using ClearML data. That way, we have clear tracking of the code, clear tracking of the data and a nice view on model performance. It makes it easy to determine which model is doing better.”
How Iodine Chose ClearML
Before choosing ClearML, the company demoed several other offerings, but they were deemed too complex or trying to do too much and not very well. Matthew also notes that it was difficult to find one that worked on-prem, which was a clear differentiator for going with ClearML. “I really liked how easy it is to use ClearML,” Matthews recalled. “We were able to try it out on the Open Source server and do our own personal projects and we liked it. We just put a couple of lines of code at the beginning of our script and then it captures everything, which is really nice. That made it easy to convince our users to switch over from their legacy file share-based process, saving things to random places, to having everything all together.”
Keeping Sensitive Data
Where It Belongs
Matthews noted that before ClearML, consultants who help the company build models could not access the company’s GPU cluster, as they are not allowed to access sensitive data such as protected health information. This meant they had to do everything on their machines, which was inefficient. Now with ClearML, they have compute resources available to them. The company’s data scientists simply access the data to de-identify it and then store it for the consultants to use within ClearML such that they are not exposed to any sensitive data. “Our consultants can use our GPU systems without having to SSH into our machines, which our security protocol does not allow,” Matthews said. “They can run training on premises and have access only to their specific projects, minimizing risk. This also helps them more easily meet deadlines as well.”
Enabling Easier Collaboration
He also noted that ClearML has made it easier to collaborate. “It’s nice to have everything out in the open and see what’s going on. I also know that if I am stuck doing something, I can look at how other people have done it in the past. If someone else needs help, I can see exactly what they’re doing and where they are stuck,” Matthews said. “We can also use it as a catalog. In fact, one of my team members was asking how to create a new type of model, and I was able to show him one I had already created.”
Maximizing Productivity
One of the biggest benefits of ClearML that Matthews has found is regaining time that was previously lost to inefficiency. “With ClearML, we’ve stopped wasting so much time re-doing experiments. Before, probably a quarter of our modeling time was just rework, because we would do an experiment and completely forget what happened – and then do the same thing over and over again. That’s been eliminated, because with ClearML, you can go back and look at exactly what you did.”
Looking Forward
Matthews says they’re developing a “Publish Model” button, a Webhook to automatically upload the model to their model serving software, noting that it could save eight hours per model deployment.
“We update models pretty consistently, because as medicine evolves, our datasets grow. We check them into the main product repo, and then we deploy the main products in our staging environment, do our testing there, and then deploy again to production,” Matthews said. “What we’re going to do to make this process easier is have a new model serving infrastructure where ClearML just seamlessly pushes models to production,” he concluded.
If you’d like to get started with ClearML, get the Open Source version on GitHub. If you need to scale your ML pipelines and data abstraction or need unmatched performance and control, please request a demo.