PipelineController
The PipelineController Class
Create the PipelineController, where you will define
the pipeline's execution logic:
from clearml import PipelineController
pipe = PipelineController(
name="Pipeline Controller", project="Pipeline example", version="1.0.0"
)
name- The name for the pipeline controller taskproject- The ClearML project where the pipeline tasks will be created.version- Numbered version string (for example,1.2.3). If not set, find the pipeline's latest version and increment it. If no such version is found, defaults to1.0.0
See PipelineController for all arguments.
Pipeline Parameters
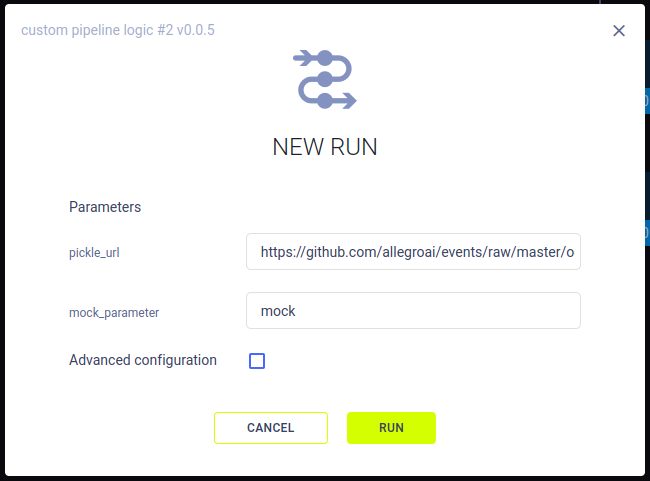
You can define parameters for controlling different pipeline runs:
pipe.add_parameter(
name='pickle_url',
description='url to pickle file',
default='https://github.com/allegroai/events/raw/master/odsc20-east/generic/iris_dataset.pkl'
)
name- Parameter namedefault- Parameter's default value (this value can later be changed in the UI)description- String description of the parameter and its usage in the pipeline
These parameters can be programmatically injected into a step's configuration using the following format: "${pipeline.<parameter_name>}".
When launching a new pipeline run from the UI, you can modify their values for the new run.
Additional Configuration
You can connect configuration dictionaries or files to a pipeline controller using
PipelineController.connect_configuration()
by providing the configuration object, or file path.
For files, call connect_configuration() before reading the configuration file. If it's a local file, input a relative
path.
config_file = pipe.connect_configuration(
configuration=config_file_path,
name="My Configuration",
description="configuration for pipeline"
)
my_params = json.load(open(config_file,'rt'))
You can view the configuration in the pipeline's task page's CONFIGURATION tab, in the section specified in the
name parameter.
Pipeline Steps
Once you have a PipelineController object, add steps to it. These steps can be existing ClearML tasks or functions in your code. When the pipeline runs, the controller will launch the steps according to the specified structure.
Steps from Tasks
Creating a pipeline step from an existing ClearML task means that when the step is run, the task will be cloned, and a new task will be launched through the configured execution queue (the original task is unmodified). The new task's parameters can be specified.
Task steps are added using PipelineController.add_step():
pipe.add_step(
name='stage_process',
parents=['stage_data', ],
base_task_project='examples',
base_task_name='pipeline step 2 process dataset',
parameter_override={
'General/dataset_url': '${stage_data.artifacts.dataset.url}',
'General/test_size': 0.25},
pre_execute_callback=pre_execute_callback_example,
post_execute_callback=post_execute_callback_example
)
name- Unique name for the step. This step can be referenced by any proceeding steps in the pipeline using its name.- One of the following:
base_task_projectandbase_task_name- Project and name of the base task to clonebase_task_id- ID of the base task to clone
cache_executed_step– IfTrue, the controller will check if an identical task with the same code (including setup, e.g. required packages, docker image, etc.) and input arguments was already executed. If found, the cached step's outputs are used instead of launching a new task.execution_queue(optional) - The queue to use for executing this specific step. If not provided, the task will be sent to the default execution queue, as defined on the class.parents(optional) - List of parent steps in the pipeline. The current step in the pipeline will be sent for execution only after all the parent steps have been executed successfully.parameter_override- Dictionary of parameters and values to override in the current step. See parameter_override.configuration_overrides- Dictionary of configuration objects and values to override in the current step. See configuration_overrides.monitor_models,monitor_metrics,monitor_artifacts- see here.
See PipelineController.add_step for all arguments.
parameter_override
Use the parameter_override argument to modify the step's parameter values. The parameter_override dictionary key is
the task parameter's full path, which includes the parameter section's name and the parameter name separated by a slash
(for example, 'General/dataset_url'). Passing "${}" in the argument value lets you reference input/output configurations
from other pipeline steps. For example: "${<step_name>.id}" will be converted to the Task ID of the referenced pipeline
step.
Examples:
- Artifact URL access:
'${<step_name>.artifacts.<artifact_name>.url}' - Model access URL access:
'${<step_name>.models.output.-1.url}' - Different step parameter access:
'${<step_name>.parameters.Args/input_file}' - Pipeline parameters (see adding pipeline parameters):
'${pipeline.<pipeline_parameter>}'
configuration_overrides
You can override a step's configuration object by passing either a string representation of the content of the configuration object, or a configuration dictionary.
Examples:
- Configuration dictionary:
configuration_overrides={"my_config": {"key": "value"}} - Configuration file:
configuration_overrides={"my_config": open("config.txt", "rt").read()}
Steps from Functions
Creating a pipeline step from a function means that when the function is called, it will be transformed into a ClearML task, translating its arguments into parameters, and returning values into artifacts.
In the case that the skip_global_imports parameter of PipelineController
is set to False, all global imports will be automatically imported at the beginning of each step's execution.
Otherwise, if set to True, make sure that each function which makes up a pipeline step contains package imports, which
are automatically logged as required packages for the pipeline execution step.
Function steps are added using PipelineController.add_function_step():
pipe.add_function_step(
name='step_one',
function=step_one,
function_kwargs=dict(pickle_data_url='${pipeline.url}'),
function_return=['data_frame'],
cache_executed_step=True,
)
pipe.add_function_step(
name='step_two',
# parents=['step_one'], # the pipeline will automatically detect the dependencies based on the kwargs inputs
function=step_two,
function_kwargs=dict(data_frame='${step_one.data_frame}'),
function_return=['processed_data'],
cache_executed_step=True,
)
name- The pipeline step's name. This name can be referenced in subsequent stepsfunction- A global function to be used as a pipeline step, which will be converted into a standalone taskfunction_kwargs(optional) - A dictionary of function arguments and default values which are translated into task hyperparameters. If not provided, all function arguments are translated into hyperparameters.function_return- The names for storing the pipeline step's returned objects as artifacts in its ClearML task.cache_executed_step- IfTrue, the controller will check if an identical task with the same code (including setup, see task Execution section) and input arguments was already executed. If found, the cached step's outputs are used instead of launching a new task.parents(optional) - List of parent steps in the pipeline. The current step in the pipeline will be sent for execution only after all the parent steps have been executed successfully.pre_execute_callbackandpost_execute_callback- Control pipeline flow with callback functions that can be called before and/or after a step's execution. See here.monitor_models,monitor_metrics,monitor_artifacts- see here.
See PipelineController.add_function_step for all
arguments.
Important Arguments
pre_execute_callback and post_execute_callback
Callbacks can be utilized to control pipeline execution flow.
A pre_execute_callback function is called when the step is created, and before it is sent for execution. This allows a
user to modify the task before launch. Use node.job to access the ClearmlJob
object, or node.job.task to directly access the Task object. Parameters are the configuration arguments passed to the
ClearmlJob.
If the callback returned value is False, the step is skipped and so is any step in the pipeline that relies on this step.
Notice the parameters are already parsed (for example, ${step1.parameters.Args/param} is replaced with relevant value).
def step_created_callback(
pipeline, # type: PipelineController,
node, # type: PipelineController.Node,
parameters, # type: dict
):
pass
A post_execute_callback function is called when a step is completed. It lets you modify the step's status after completion.
def step_completed_callback(
pipeline, # type: PipelineController,
node, # type: PipelineController.Node,
):
pass
Models, Artifacts, and Metrics
You can enable automatic logging of a step's metrics /artifacts / models to the pipeline task using the following arguments:
monitor_metrics(optional) - Automatically log the step's reported metrics also on the pipeline Task. The expected format is one of the following:- List of pairs metric (title, series) to log: [(step_metric_title, step_metric_series), ]. Example:
[('test', 'accuracy'), ] - List of tuple pairs, to specify a different target metric to use on the pipeline Task: [((step_metric_title, step_metric_series), (target_metric_title, target_metric_series)), ].
Example:
[[('test', 'accuracy'), ('model', 'accuracy')], ]
- List of pairs metric (title, series) to log: [(step_metric_title, step_metric_series), ]. Example:
monitor_artifacts(optional) - Automatically log the step's artifacts on the pipeline Task.- Provided a list of artifact names created by the step function, these artifacts will be logged automatically also
on the Pipeline Task itself. Example:
['processed_data', ](target artifact name on the Pipeline Task will have the same name as the original artifact). - Alternatively, provide a list of pairs (source_artifact_name, target_artifact_name), where the first string is the
artifact name as it appears on the step Task, and the second is the target artifact name to put on the Pipeline
Task. Example:
[('processed_data', 'final_processed_data'), ]
- Provided a list of artifact names created by the step function, these artifacts will be logged automatically also
on the Pipeline Task itself. Example:
monitor_models(optional) - Automatically log the step's output models on the pipeline Task.- Provided a list of model names created by the step's Task, they will also appear on the Pipeline itself. Example:
['model_weights', ] - To select the latest (lexicographic) model, use
model_*, or the last created model with just*. Example:['model_weights_*', ] - Alternatively, provide a list of pairs (source_model_name, target_model_name), where the first string is the model
name as it appears on the step Task, and the second is the target model name to put on the Pipeline Task.
Example:
[('model_weights', 'final_model_weights'), ]
- Provided a list of model names created by the step's Task, they will also appear on the Pipeline itself. Example:
You can also directly upload a model or an artifact from the step to the pipeline controller, using the
PipelineController.upload_model
and PipelineController.upload_artifact
methods respectively.
Controlling Pipeline Execution
Default Execution Queue
The PipelineController.set_default_execution_queue
method lets you set a default queue through which all pipeline steps will be executed. Once set, step-specific overrides
can be specified through execution_queue of the PipelineController.add_step
or PipelineController.add_function_step
methods.
Running the Pipeline
Run the pipeline by using one of the following methods:
PipelineController.start- launches the pipeline controller through theservicesqueue, unless otherwise specified. The pipeline steps are enqueued to their respective queues or in the default execution queue.PipelineController.start_locally- launches the pipeline controller locally. To run the pipeline steps locally as well, passrun_pipeline_steps_locally=True.