Next Steps
So, you've already installed ClearML's python package and run your first experiment!
Now, you'll learn how to track Hyperparameters, Artifacts, and Metrics!
Accessing Experiments
Every previously executed experiment is stored as a Task. A Task's project and name can be changed after the experiment has been executed. A Task is also automatically assigned an auto-generated unique identifier (UUID string) that cannot be changed and always locates the same Task in the system.
Retrieve a Task object programmatically by querying the system based on either the Task ID, or project and name combination. You can also query tasks based on their properties, like tags (see Querying Tasks).
prev_task = Task.get_task(task_id='123456deadbeef')
Once you have a Task object you can query the state of the Task, get its model(s), scalars, parameters, etc.
Log Hyperparameters
For full reproducibility, it's paramount to save hyperparameters for each experiment. Since hyperparameters can have substantial impact on model performance, saving and comparing these between experiments is sometimes the key to understanding model behavior.
ClearML supports logging argparse module arguments out of the box, so once ClearML is integrated into the code, it automatically logs all parameters provided to the argument parser.
You can also log parameter dictionaries (very useful when parsing an external configuration file and storing as a dict object), whole configuration files, or even custom objects or Hydra configurations!
params_dictionary = {'epochs': 3, 'lr': 0.4}
task.connect(params_dictionary)
See Configuration for all hyperparameter logging options.
Log Artifacts
ClearML lets you easily store the output products of an experiment - Model snapshot / weights file, a preprocessing of your data, feature representation of data and more!
Essentially, artifacts are files (or Python objects) uploaded from a script and are stored alongside the Task. These artifacts can be easily accessed by the web UI or programmatically.
Artifacts can be stored anywhere, either on the ClearML server, or any object storage solution or shared folder. See all storage capabilities.
Adding Artifacts
Upload a local file containing the preprocessed results of the data:
task.upload_artifact(name='data', artifact_object='/path/to/preprocess_data.csv')
You can also upload an entire folder with all its content by passing the folder (the folder will be zipped and uploaded as a single zip file).
task.upload_artifact(name='folder', artifact_object='/path/to/folder/')
Lastly, you can upload an instance of an object; Numpy/Pandas/PIL Images are supported with npz/csv.gz/jpg formats accordingly.
If the object type is unknown, ClearML pickles it and uploads the pickle file.
numpy_object = np.eye(100, 100)
task.upload_artifact(name='features', artifact_object=numpy_object)
For more artifact logging options, see Artifacts.
Using Artifacts
Logged artifacts can be used by other Tasks, whether it's a pre-trained Model or processed data. To use an artifact, first you have to get an instance of the Task that originally created it, then you either download it and get its path, or get the artifact object directly.
For example, using a previously generated preprocessed data.
preprocess_task = Task.get_task(task_id='preprocessing_task_id')
local_csv = preprocess_task.artifacts['data'].get_local_copy()
task.artifacts is a dictionary where the keys are the artifact names, and the returned object is the artifact object.
Calling get_local_copy() returns a local cached copy of the artifact. Therefore, next time you execute the code, you don't
need to download the artifact again.
Calling get() gets a deserialized pickled object.
Check out the artifacts retrieval example code.
Models
Models are a special kind of artifact. Models created by popular frameworks (such as PyTorch, TensorFlow, Scikit-learn) are automatically logged by ClearML. All snapshots are automatically logged. In order to make sure you also automatically upload the model snapshot (instead of saving its local path), pass a storage location for the model files to be uploaded to.
For example, upload all snapshots to an S3 bucket:
task = Task.init(
project_name='examples',
task_name='storing model',
output_uri='s3://my_models/'
)
Now, whenever the framework (TensorFlow/Keras/PyTorch etc.) stores a snapshot, the model file is automatically uploaded to the bucket to a specific folder for the experiment.
Loading models by a framework is also logged by the system; these models appear in an experiment's Artifacts tab, under the "Input Models" section.
Check out model snapshots examples for TensorFlow, PyTorch, Keras, scikit-learn.
Loading Models
Loading a previously trained model is quite similar to loading artifacts.
prev_task = Task.get_task(task_id='the_training_task')
last_snapshot = prev_task.models['output'][-1]
local_weights_path = last_snapshot.get_local_copy()
Like before, you have to get the instance of the task training the original weights files, then you can query the task for its output models (a list of snapshots), and get the latest snapshot.
Using TensorFlow, the snapshots are stored in a folder, meaning the local_weights_path will point to a folder containing your requested snapshot.
As with artifacts, all models are cached, meaning the next time you run this code, no model needs to be downloaded. Once one of the frameworks will load the weights file, the running task will be automatically updated with “Input Model” pointing directly to the original training Task’s Model. This feature lets you easily get a full genealogy of every trained and used model by your system!
Log Metrics
Full metrics logging is the key to finding the best performing model! By default, ClearML automatically captures and logs everything reported to TensorBoard and Matplotlib.
Since not all metrics are tracked that way, you can also manually report metrics using a Logger object.
You can log everything, from time series data and confusion matrices to HTML, Audio, and Video, to custom plotly graphs! Everything goes!
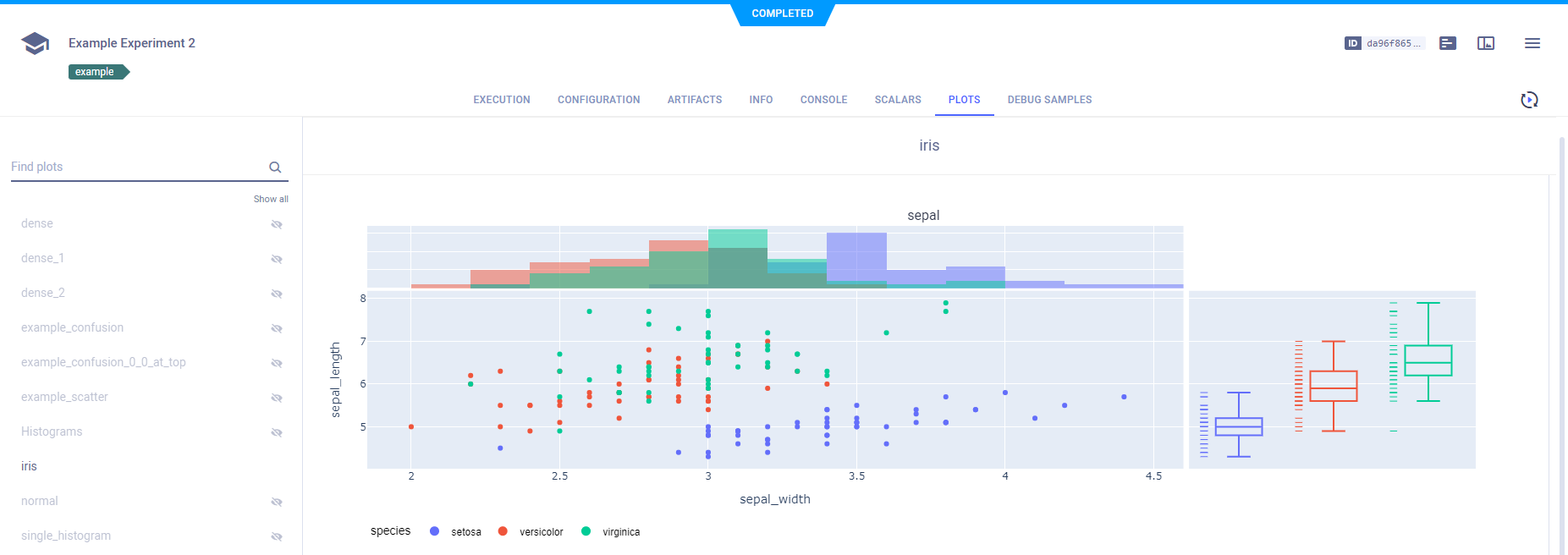
Once everything is neatly logged and displayed, use the comparison tool to find the best configuration!
Track Experiments
The experiments table is a powerful tool for creating dashboards and views of your own projects, your team's projects, or the entire development.
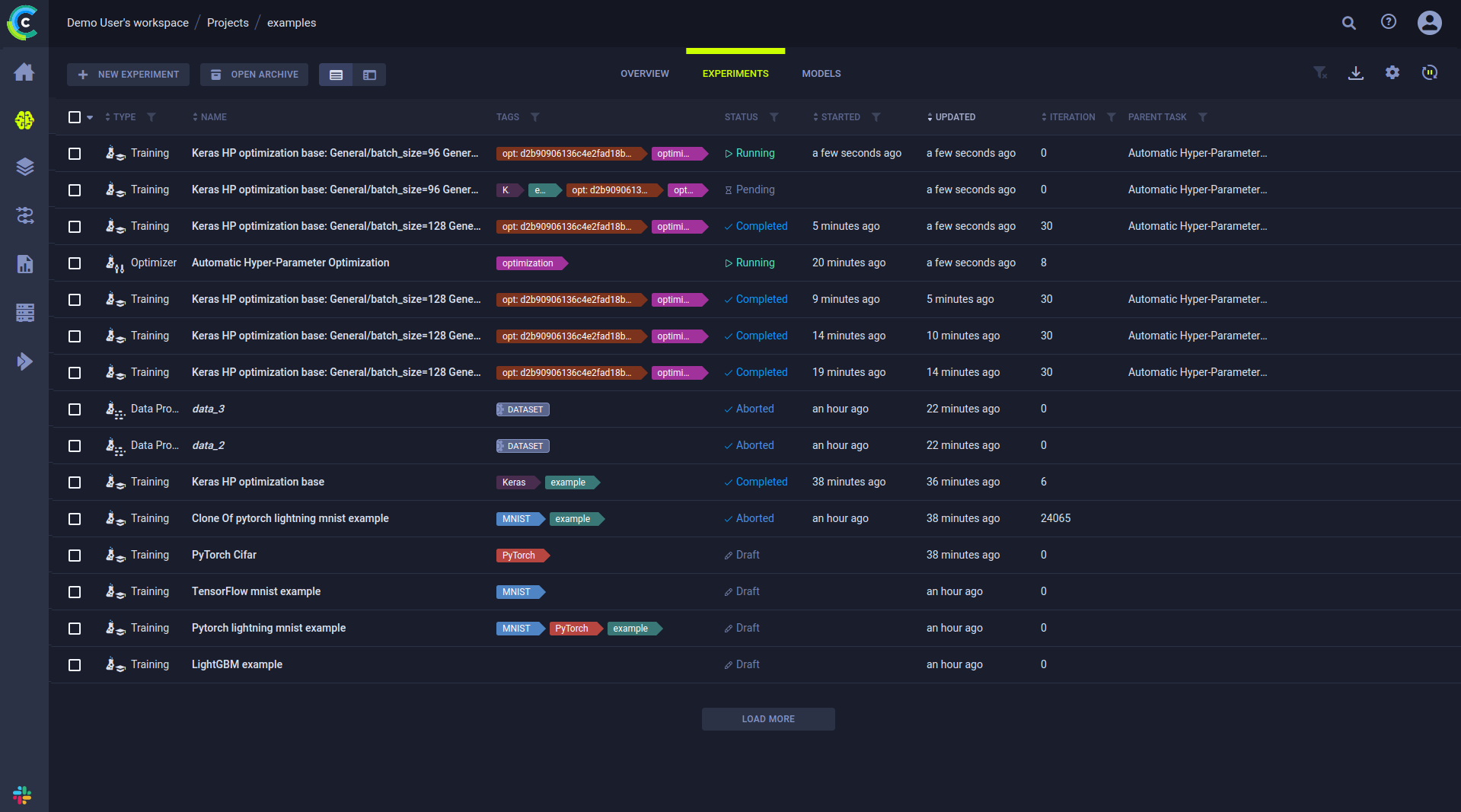
Creating Leaderboards
Customize the experiments table to fit your own needs, adding desired views of parameters, metrics, and tags. You can filter and sort based on parameters and metrics, so creating custom views is simple and flexible.
Create a dashboard for a project, presenting the latest Models and their accuracy scores, for immediate insights.
It can also be used as a live leaderboard, showing the best performing experiments' status, updated in real time. This is helpful to monitor your projects' progress, and to share it across the organization.
Any page is sharable by copying the URL from the address bar, allowing you to bookmark leaderboards or to send an exact view of a specific experiment or a comparison page.
You can also tag Tasks for visibility and filtering allowing you to add more information on the execution of the experiment. Later you can search based on task name in the search bar, and filter experiments based on their tags, parameters, status, and more.
What's Next?
This covers the basics of ClearML! Running through this guide you've learned how to log Parameters, Artifacts and Metrics!
If you want to learn more look at how we see the data science process in our best practices page, or check these pages out:
- Scale you work and deploy ClearML Agents
- Develop on remote machines with ClearML Session
- Structure your work and put it into Pipelines
- Improve your experiments with Hyperparameter Optimization
- Check out ClearML's integrations with your favorite ML frameworks like TensorFlow, PyTorch, Keras, and more
YouTube Playlist
All these tips and tricks are also covered in ClearML's Getting Started series on YouTube. Go check it out :)
