Tasks
ClearML Task lies at the heart of ClearML's experiment manager.
A Task is a single code execution session, which can represent an experiment, a step in a workflow, a workflow controller, or any custom implementation you choose.
To transform an existing script into a ClearML Task, call the Task.init() method
and specify a task name and its project. This creates a Task object that automatically captures code execution
information as well as execution outputs.
All the information captured by a task is by default uploaded to the ClearML Server, and it can be visualized in the ClearML WebApp (UI). ClearML can also be configured to upload model checkpoints, artifacts, and charts to cloud storage (see Storage). Additionally, you can work with tasks in Offline Mode, in which all information is saved in a local folder (see Storing Task Data Offline).
Tasks are grouped into a project hierarchical structure, similar to file folders. Users can decide how to group tasks, though different models or objectives are usually grouped into different projects.
Tasks can be accessed and utilized with code. Access a task by specifying project name and task name combination or by a unique ID.
You can create copies of a task (clone) then execute them with ClearML Agent. When an agent executes a task, it uses the specified configuration to:
- Install required Python packages
- Apply code patches
- Set hyperparameter and run-time configuration values
Modifying a task clone's configuration will have the executing ClearML agent override the original values:
- Modified package requirements will have the experiment script run with updated packages.
- Modified recorded command line arguments will have the ClearML agent inject the new values in their stead
- Code-level configuration instrumented with
Task.connectwill be overridden by modified hyperparameters.
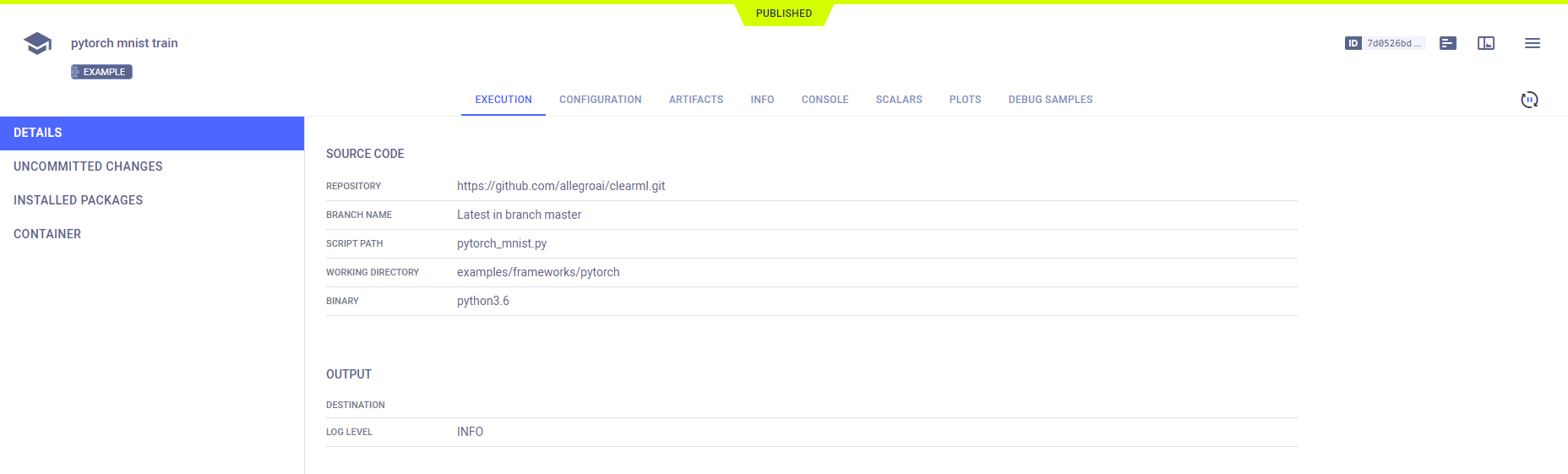
Task Sections
The sections of ClearML Task are made up of the information that a task captures and stores, which consists of code execution details and execution outputs. This information is used for tracking and visualizing results, reproducing, tuning, and comparing experiments, and executing workflows.
The captured code execution information includes:
- Git information
- Uncommitted code modifications
- Python environment
- Execution configuration and hyperparameters
The captured execution output includes:
For a more in-depth description of each task section, see Tracking Experiments and Visualizing Results.
Execution Configuration
ClearML logs a task's hyperparameters specified as command line arguments, environment or code level variables. This allows experiments to be reproduced, and their hyperparameters and results can be saved and compared, which is key to understanding model behavior.
Hyperparameters can be added from anywhere in your code, and ClearML provides multiple ways to log them. If you specify your parameters using popular python packages, such as argparse and click, all you need to do is initialize a task, and ClearML will automatically log the parameters. ClearML also provides methods to explicitly report parameters.
When executing a task through a ClearML agent, the ClearML instrumentation of your code allows for using the ClearML UI to override the original specified values of your parameters.
See Hyperparameters for more information.
Artifacts
ClearML allows easy storage of experiments' output products as artifacts that can later be accessed easily and used, through the web UI or programmatically.
ClearML provides methods to easily track files generated throughout your experiments' execution such as:
- Numpy objects
- Pandas DataFrames
- PIL
- Files and folders
- Python objects
- and more!
Most importantly, ClearML also logs experiments' input and output models as well as interim model snapshots (see Models).
Logging Artifacts
ClearML provides an explicit logging interface that supports manually reporting a variety of artifacts. Any type of
artifact can be logged to a task using Task.upload_artifact().
See more details in the Artifacts Reporting example.
ClearML can be configured to upload artifacts to any of the supported types of storage, which include local and shared folders, AWS S3 buckets, Google Cloud Storage, and Azure Storage. For more information, see Storage.
Debug samples are handled differently, see Logger.set_default_upload_destination
Accessing Artifacts
Artifacts that have been logged can be accessed by other tasks through the task they are attached to, and then retrieving the artifact with one of its following methods:
get_local_copy()- caches the files for later use and returns a path to the cached file.get()- use for Python objects. The method that returns the Python object.
See more details in the Using Artifacts example.
Task Types
Tasks have a type attribute, which denotes their purpose. This helps to further organize projects and ensure tasks are easy to search and find. Available task types are:
- training (default) - Training a model
- testing - Testing a component, for example model performance
- inference - Model inference job (e.g. offline / batch model execution)
- controller - A task that lays out the logic for other tasks' interactions, manual or automatic (e.g. a pipeline controller)
- optimizer - A specific type of controller for optimization tasks (e.g. hyperparameter optimization)
- service - Long lasting or recurring service (e.g. server cleanup, auto ingress, sync services etc.)
- monitor - A specific type of service for monitoring
- application - A task implementing custom applicative logic, like autoscaler or clearml-session
- data_processing - Any data ingress / preprocessing (see ClearML Data)
- qc - Quality Control (e.g. evaluating model performance vs. blind dataset)
- custom - A task not matching any of the above
Task Lifecycle
ClearML Tasks are created in one of the following methods:
- Manually running code that is instrumented with the ClearML SDK and invokes
Task.init. - Cloning an existing task.
- Creating a task via CLI using clearml-task.
Logging Task Information
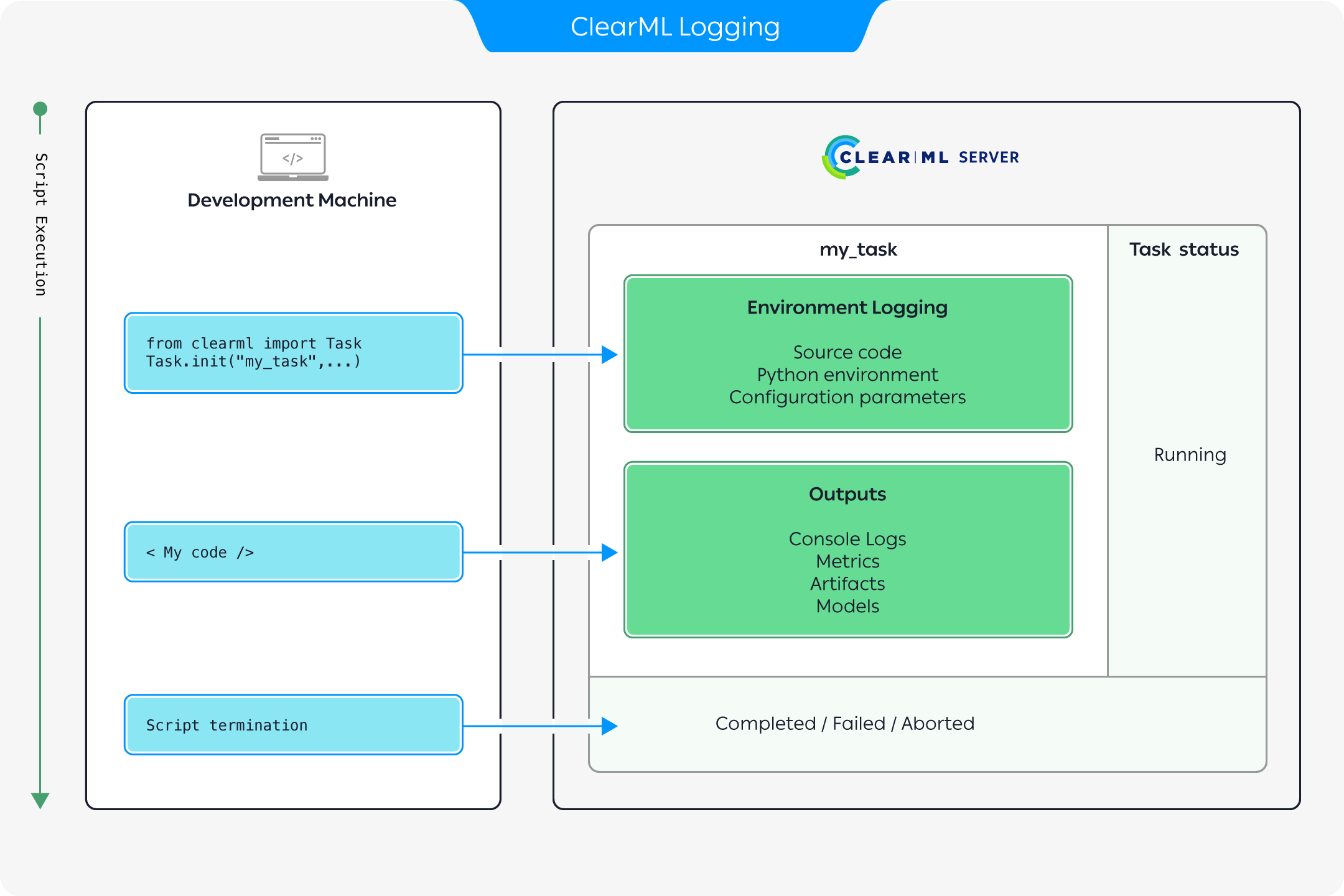
The above diagram describes how execution information is recorded when running code instrumented with ClearML:
- Once a ClearML Task is initialized, ClearML automatically logs the complete environment information
including:
- Source code
- Python environment
- Configuration parameters.
- As the execution progresses, any outputs produced are recorded including:
- Console logs
- Metrics and graphs
- Models and other artifacts
- Once the script terminates, the task will change its status to either
Completed,Failed, orAborted(see Task states below).
All information logged can be viewed in the task details UI.
Cloning Tasks
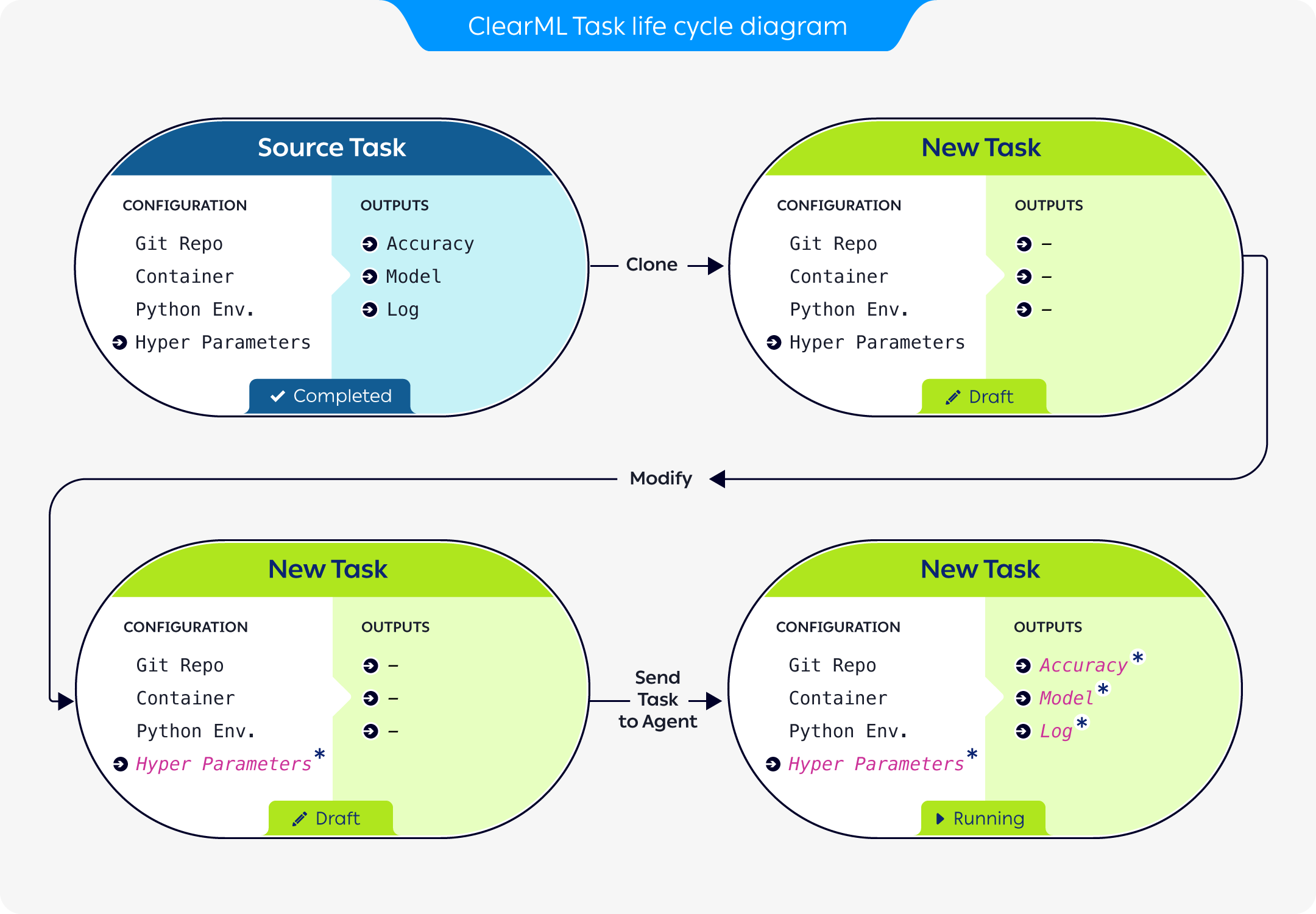
The above diagram demonstrates how a previously run task can be used as a baseline for experimentation:
- A previously run task is cloned, creating a new task, in
Draftmode (see Task states below).
The new task retains all the source task's configuration. The original task's outputs are not carried over. - The new task's configuration is modified to reflect the desired parameters for the new execution.
- The new task is enqueued for execution.
- A
clearml-agentservicing the queue pulls the new task and executes it (where ClearML again logs all the execution outputs).
Task States
The state of a task represents its stage in the task lifecycle. It indicates whether the task is read-write (editable) or read-only. For each state, a state transition indicates which actions can be performed on an experiment, and the new state after performing an action.
The following table describes the task states and state transitions.
| State | Description / Usage | State Transition |
|---|---|---|
| Draft | The experiment is editable. Only experiments in Draft mode are editable. The experiment is not running locally or remotely. | If the experiment is enqueued for a worker to fetch and execute, the state becomes Pending. |
| Pending | The experiment was enqueued and is waiting in a queue for a worker to fetch and execute it. | If the experiment is dequeued, the state becomes Draft. |
| Running | The experiment is running locally or remotely. | If the experiment is manually or programmatically terminated, the state becomes Aborted. |
| Completed | The experiment ran and terminated successfully. | If the experiment is reset or cloned, the state of the cloned experiment or newly cloned experiment becomes Draft. Resetting deletes the logs and output of a previous run. Cloning creates an exact, editable copy. |
| Failed | The experiment ran and terminated with an error. | The same as Completed. |
| Aborted | The experiment ran, and was manually or programmatically terminated. The server's non-responsive task monitor aborts a task automatically after no activity has been detected for a specified time interval (configurable). | The same as Completed. |
| Published | The experiment is read-only. Publish an experiment to prevent changes to its inputs and outputs. | A Published experiment cannot be reset. If it is cloned, the state of the newly cloned experiment becomes Draft. |
SDK Interface
See the task SDK interface for an overview for using the most basic Pythonic methods of the Task class.
See the Task reference page for a complete list of available methods.