Best Practices
This page covers clearml-data, ClearML's file-based data management solution.
See Hyper-Datasets for ClearML's advanced queryable dataset management solution.
The following are some recommendations for using ClearML Data.
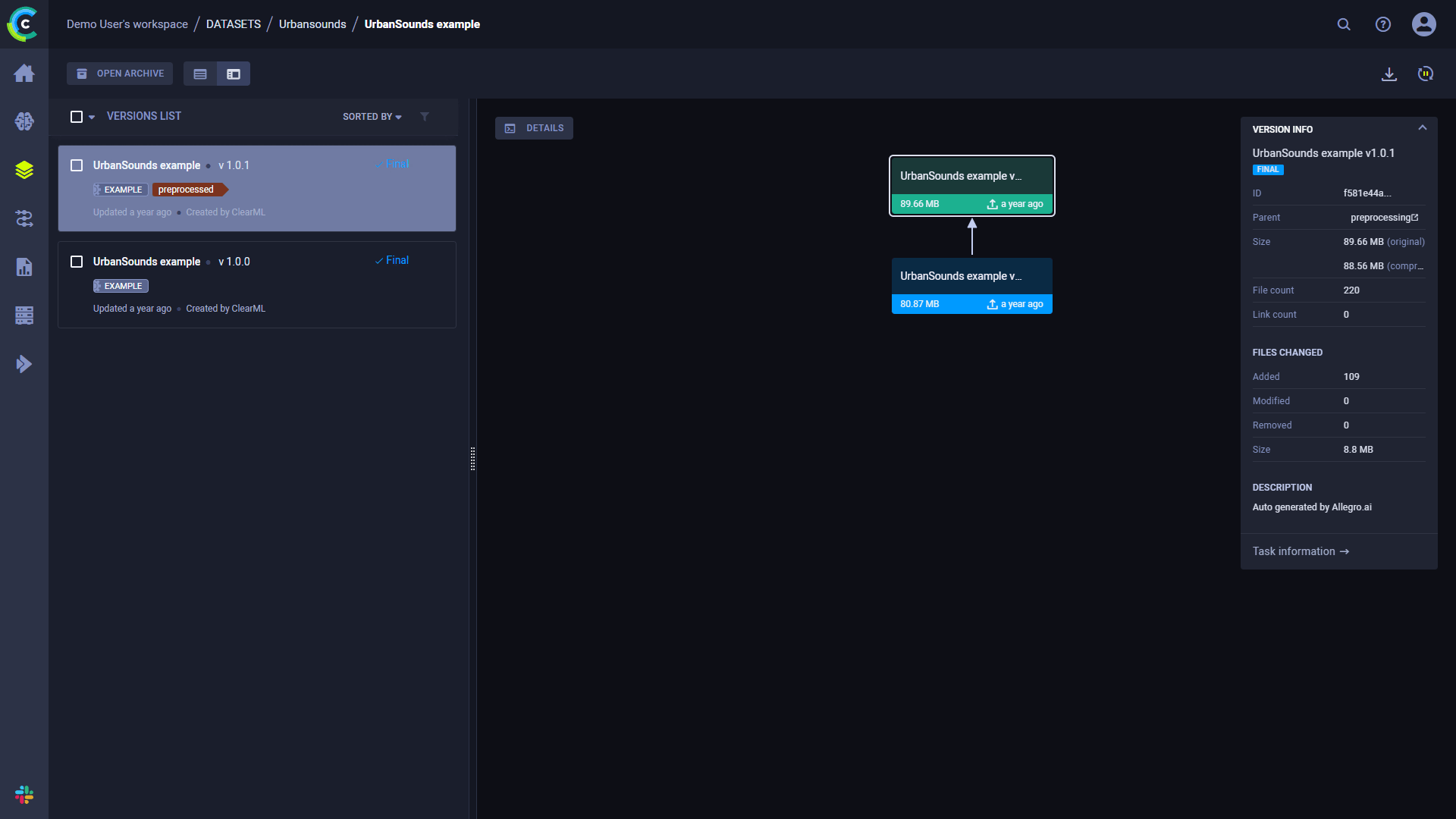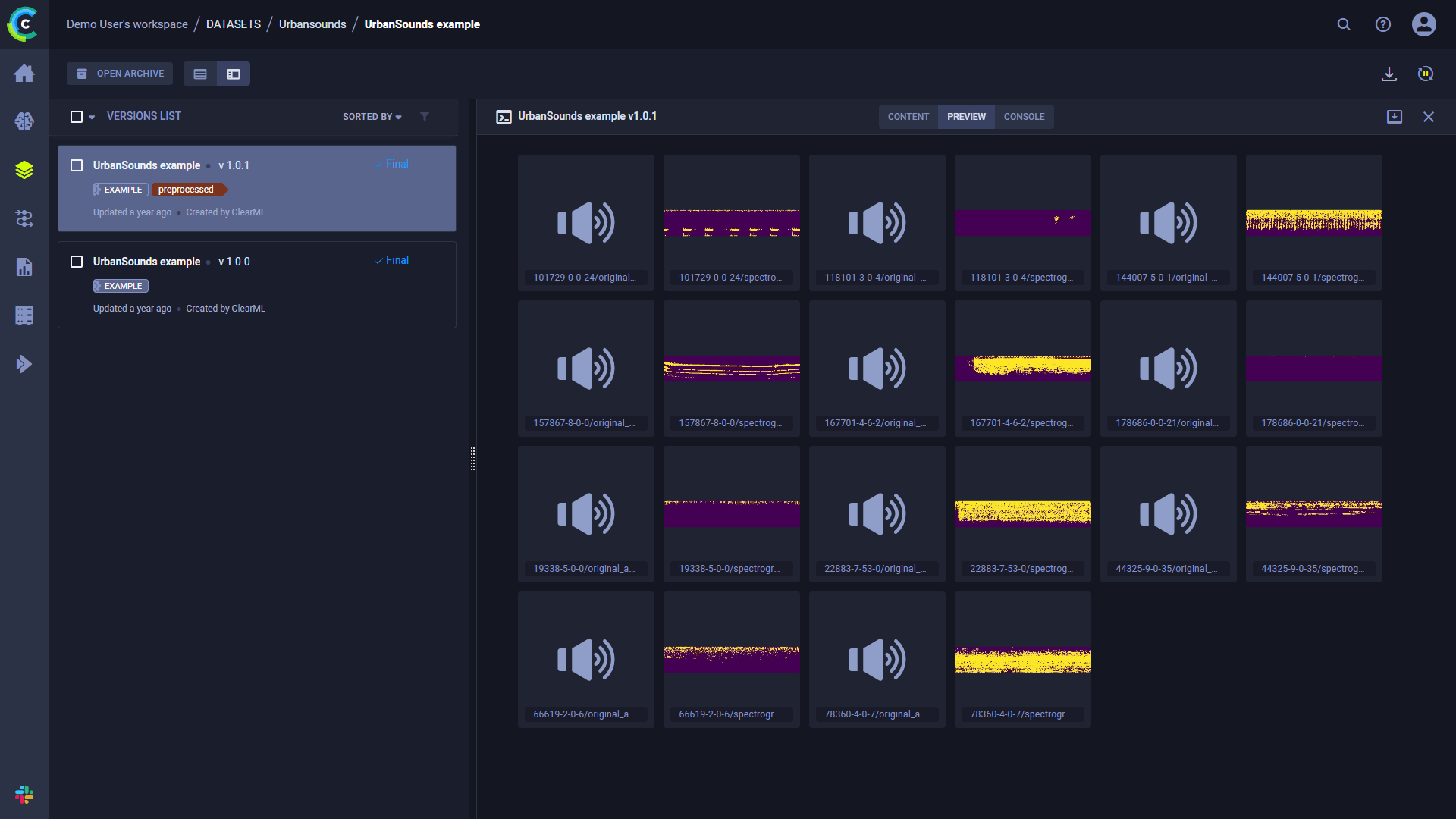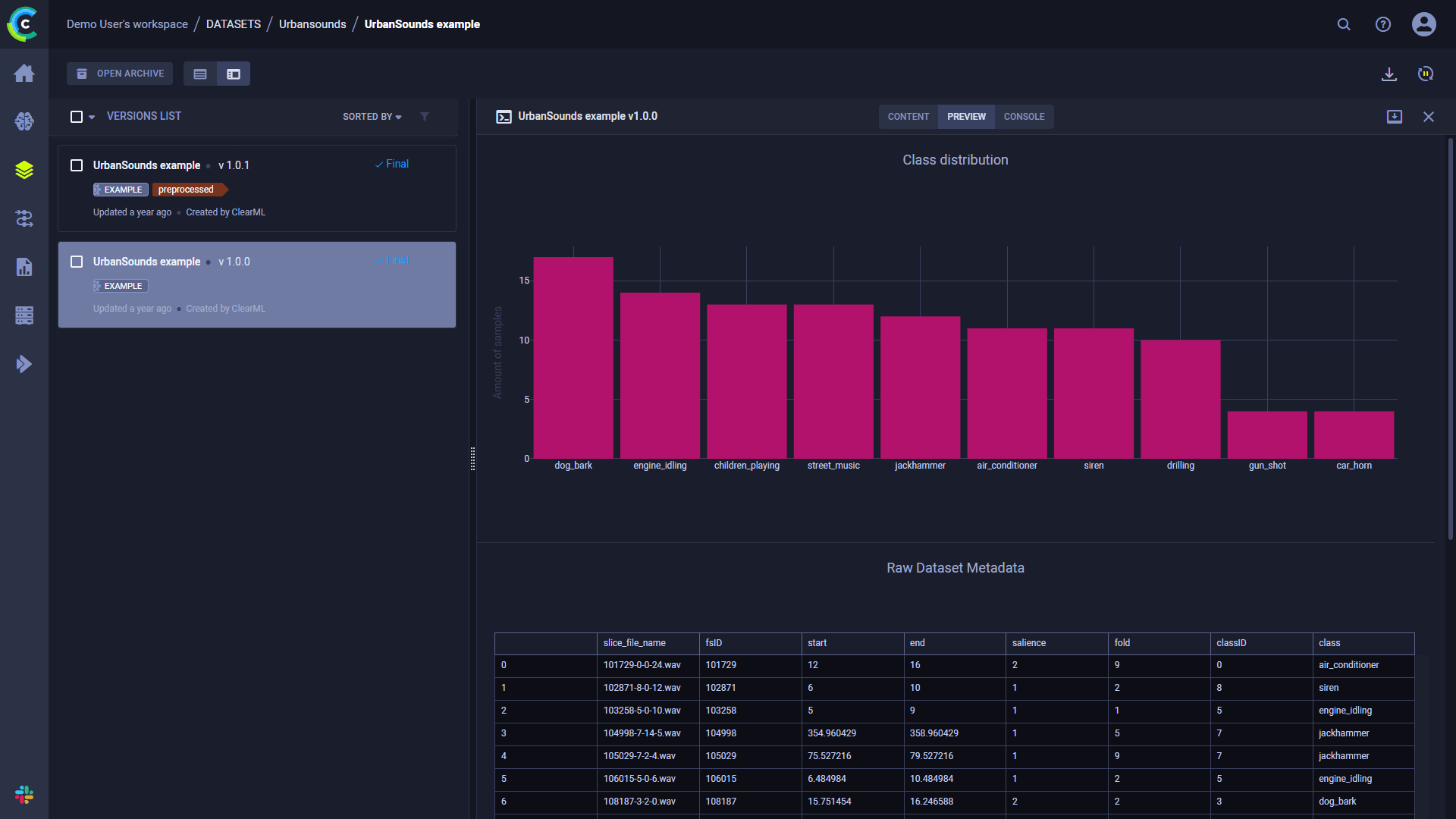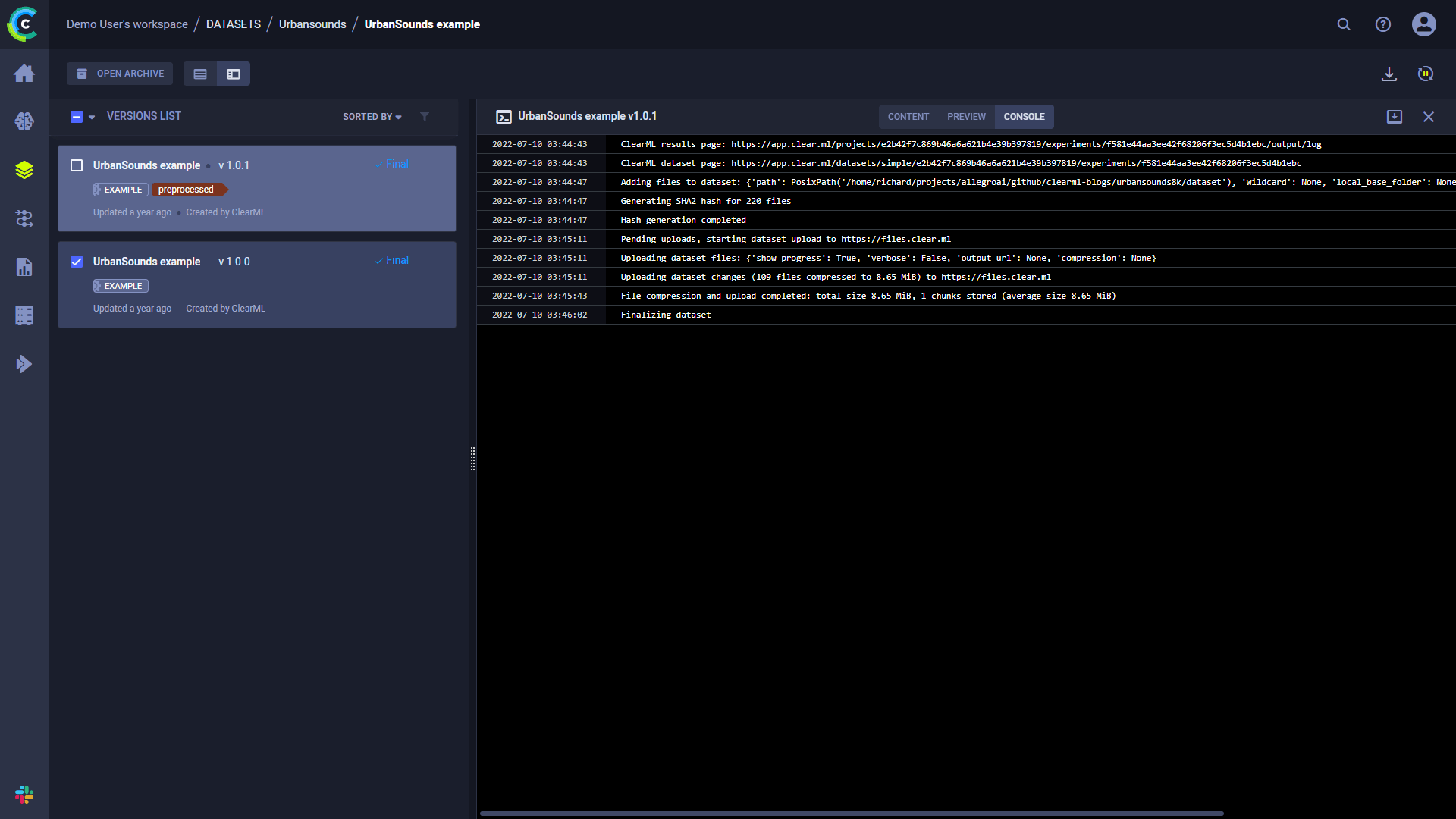
Versioning Datasets
Use ClearML Data to version your datasets. Once a dataset is finalized, it can no longer be modified. This makes clear which version of the dataset was used with which task, enabling the accurate reproduction of your experiments.
Once you need to change the dataset's contents, you can create a new version of the dataset by specifying the previous dataset as a parent. This makes the new dataset version inherit the previous version's contents, with the dataset's new version contents ready to be updated.
Organize Datasets for Easier Access
Organize the datasets according to use-cases and use tags. This makes managing multiple datasets and accessing the most updated datasets for different use-cases easier.
Like any ClearML tasks, datasets can be organized into projects (and subprojects). Additionally, when creating a dataset, tags can be applied to the dataset, which will make searching for the dataset easier.
Organizing your datasets into projects by use-case makes it easier to access the most recent dataset version for that use-case.
If only a project is specified when using Dataset.get(), the method returns the
most recent dataset in a project. The same is true with tags; if a tag is specified, the method will return the most recent dataset that is labeled with that tag.
In cases where you use a dataset in a task (e.g. consuming a dataset), you can easily track which dataset the task is
using by using Dataset.get()'s alias parameter. Pass alias=<dataset_alias_string>, and the task using the dataset
will store the dataset's ID in the dataset_alias_string parameter under the task's CONFIGURATION > HYPERPARAMETERS >
Datasets section.
Document your Datasets
Attach informative metrics or debug samples to the Dataset itself. Use Dataset.get_logger()
to access the dataset's logger object, then add any additional information to the dataset, using the methods
available with a Logger object.
You can add some dataset summaries (like table reporting) to create a preview of the data stored for better visibility, or attach any statistics generated by the data ingestion process.
Periodically Update Your Dataset
Your data probably changes from time to time. If the data is updated into the same local / network folder structure, which
serves as a dataset's single point of truth, you can schedule a script which uses the dataset sync functionality which
will update the dataset based on the modifications made to the folder. This way, there is no need to manually modify a dataset.
This functionality will also track the modifications made to a folder.