Making a Question Answering (QA) bot that can cite your own documentation and help channels is now possible thanks to chatGPT and Langchain, an open-source tool that cleverly uses chatGPT but doesn’t require retraining it. But it’s a far cry from “out of the box.” One example is that you have to get the prompt just right. To get an LLM (large language model) to do exactly what you want, your instructions will have to be very clear, so what if we automate that too?
The code is available on GitHub, you can find the link below!
Background: making a question answering chatbot based on your own documentation
Customer support is very hard to scale. From fully open-source projects to multinational corporations, it remains a pain point for almost all businesses and organizations. Thanks to Langchain and OpenAI, however, actually useful customized chatbots can be made to help answer questions that have been asked before or are stated in the documentation. In this way, the support team can focus more on helping users with novel or very complex problems.
Models like chatGPT aren’t plug-and-play, however. ChatGPT has no external access (as of the time of writing of this blog post), so it has to come up with an answer to a question “from memory,” which in reality means it tends to hallucinate answers that look like they make sense but are wrong.
To combat this, we’ll use the chatGPT API together with the following tricks:
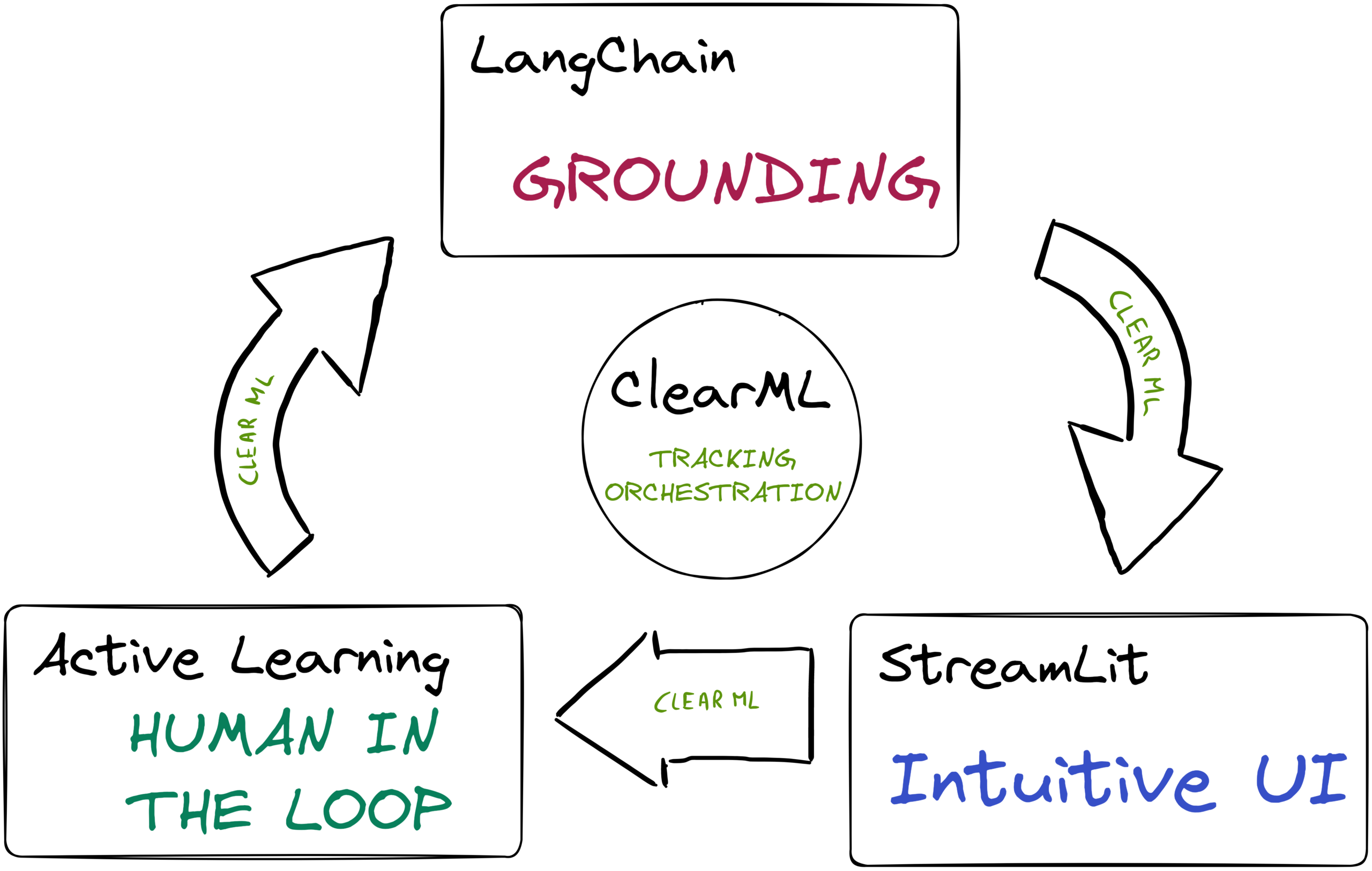
- Grounding using LangChain: Grounding is the process of giving the LLM as much relevant information as possible inside its prompt along with clear instructions and even examples. We’ll show the model relevant documentation snippets it can use to phrase its answer based on facts.
- Active Learning: The exact instruction prompt we’ll give to the LLM can be learned, too! We’ll use an Active Learning loop to iteratively improve the initial instruction prompt using a human in the loop to get to the very best performance. ClearML will keep track of the progress and orchestrate the loop.
- Intuitive UI: We’ll build a Streamlit app so that any user, QA specialist, or Labeler can evaluate and rate the current iteration of the bot. Doing this is a very important step of the process because it allows other people to take part in the optimization process.
We’ll show how each of these components plays its role in the process, so let’s start with the first one: grounding using LangChain.
Question answering on your own data: Langchain
Langchain is an open-source tool to “chain” together smart calls to LLM APIs such as those from OpenAI, to perform a more personalized and specific task than is usually possible to do with these models out of the box.
Essentially, it’s turning pre-built, well-tested prompts into “modules” that you can just plug and play into a larger chain of logic.
A primer on Langchain: Math
Remember that these LLM models are not very good at maths? Well, through the clever use of Langchain, we can actually fix that.
from langchain import OpenAI, LLMMathChain
llm = OpenAI(temperature=0)
llm_math = LLMMathChain(llm=llm, verbose=True)
llm_math.run("What is 13 raised to the .3432 power?")
Entering new LLMMathChain chain... What is 13 raised to the .3432 power? ```python import math print(math.pow(13, .3432)) ``` Answer: 2.4116004626599237 > Finished Chain
Clearly, a lot of stuff happened behind the scenes here. Looking at the source code reveals the trickery involved. I’ll spare you the specifics, but here is roughly what happened when calling llm_math.run
- First of all, the question “What is 13 raised to the .3432 power” is formatted into a larger, pre-built prompt, that contains a description of the problem and a way for the model to answer the question, along with some examples.
- That prompt makes sure the AI will always reply with a code-block, which it can do much better than actual math
- A postprocessing function then spins up an actual code execution environment, extracts the code block and runs it.
- The result that the LLM produced is detected and overwritten by the actual result of the code running, in this way we are sure it will always be correct IF it runs.
No training was done here, just a smart way of getting the LLM to output a standardized output format, which you can then parse and use just like any other data in a normal program or API.
Documentation Question Answering Bot
The documentation approach works in the same way, only there are much more steps involved. These are the major parts involved:
- Use the OpenAI Embedding API to embed your documentation and other possibly helpful information
- Given the user question, retrieve relevant information and ask the LLM to extract the useful parts verbatim
- Given the question and useful parts of the documentation, ask the LLM to reply, citing its sources based on the relevant pieces of info it received.
Pro tip: use ClearML-Data to keep track of your own documentation! The versioning system allows you to easily keep track of newer versions of the documentation, the task of preprocessing the docs into text files can be tracked using the experiment manager and the two will always be linked. As a bonus, this setup makes it super easy to automate the generation of these text files and then embeddings whenever a new version of your documentation is pushed.


This setup can lead to some truly impressive results as well as some explicit cases of it being confidently wrong. However, is this something we can try to solve using prompt engineering? After all, as we saw above, Langchain is just using specific prompt templates in the back, so what if we ask an LLM to find the optimal prompt?
Meta-learning: AIs training AIs
The idea of meta-learning here is to optimize the prompt template that Langchain uses to generate the answers to a user’s questions. Naturally, asking GPT to create a new prompt has to be done by using… another prompt. But this last prompt is much more universally applicable though since it’s a prompt optimizing prompt. Ok, that’s a lot of prompts, let’s draw a diagram here to keep track of everything.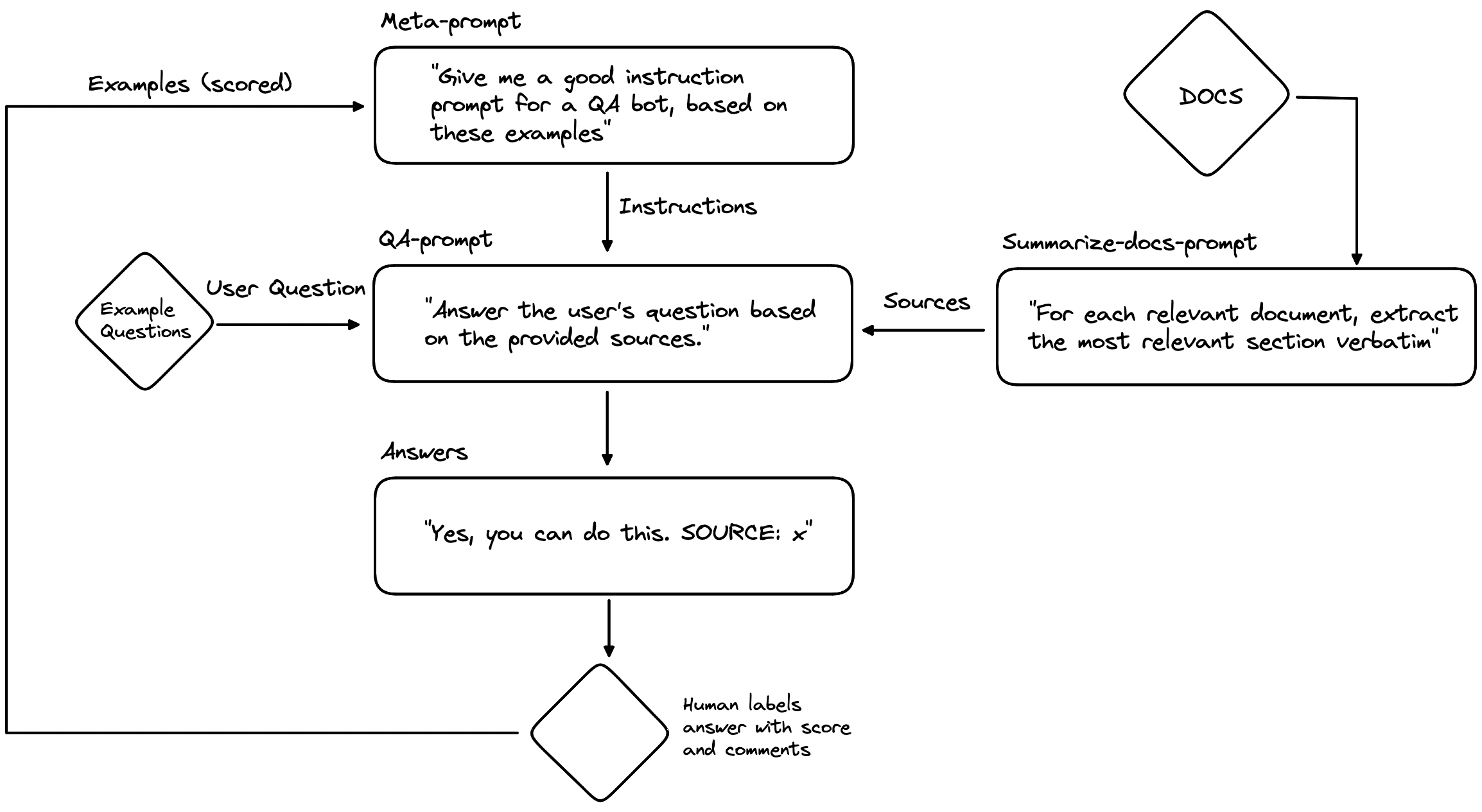
So a meta-prompt is used to generate the QA prompt (with instructions) for the QA bot. The meta-prompt has some example QA prompts, along with how well their output when used by the QA bot was rated by a human and some free-text comments and feedback.
Based on these examples and feedback, it will try to create a new QA prompt that it thinks will perform better. The generated QA prompt is then combined with the sources from the documentation and the user question. In this case, we’ll use questions from a given set of examples for a human to rate.
The QA bot answers each of the example questions and a human rates its total performance along with some feedback comments. This information can now be added to the Meta-prompt, so it can make a new, better QA prompt and the cycle continues.
We could also try to optimize the summarize-docs prompt in the same way, but let’s keep it “simple” and focus on only the QA prompt in this blogpost.
Polishing it up: Involving Colleagues and Quality Assurance
Once we implement the diagram from above, we now have a closed loop that theoretically should get better based solely on some freeform input of a human. In order to get that input, let’s polish the experience enough so that anyone with a computer can contribute. In this way, you’re involving your whole team and even beyond in the Promptimyzer.
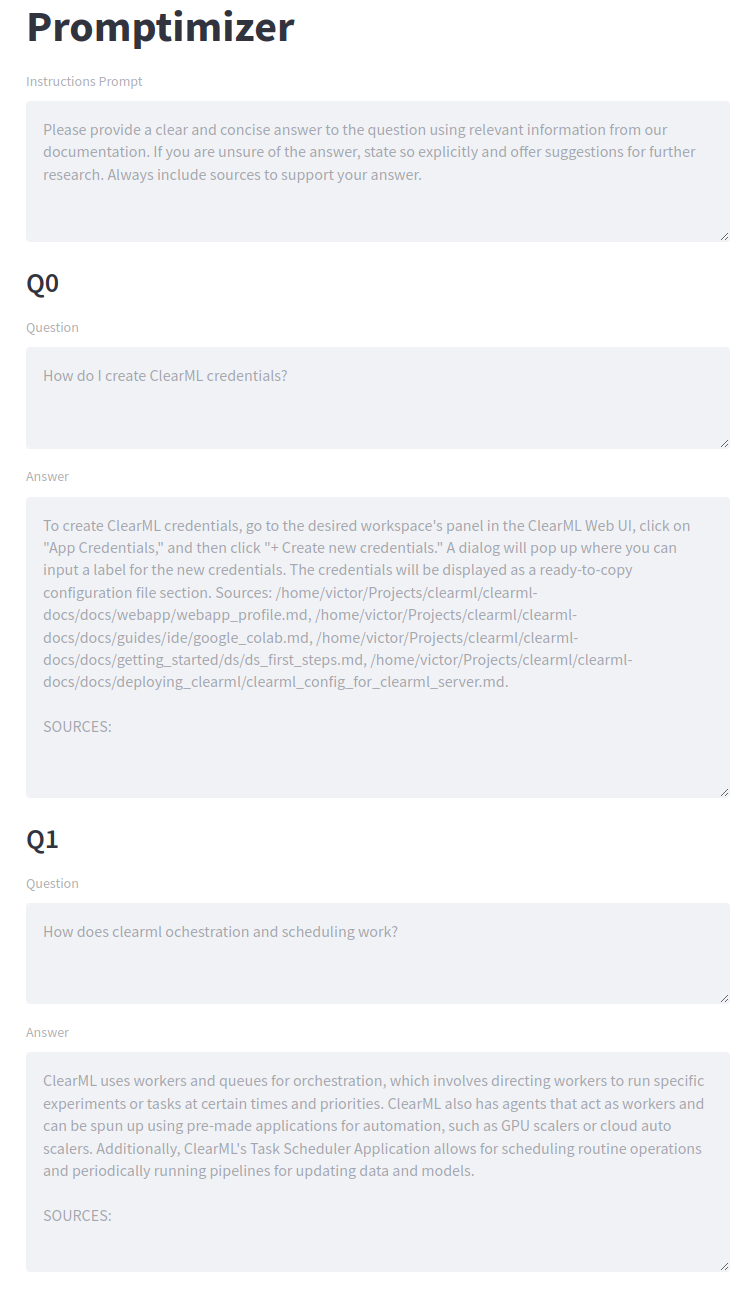
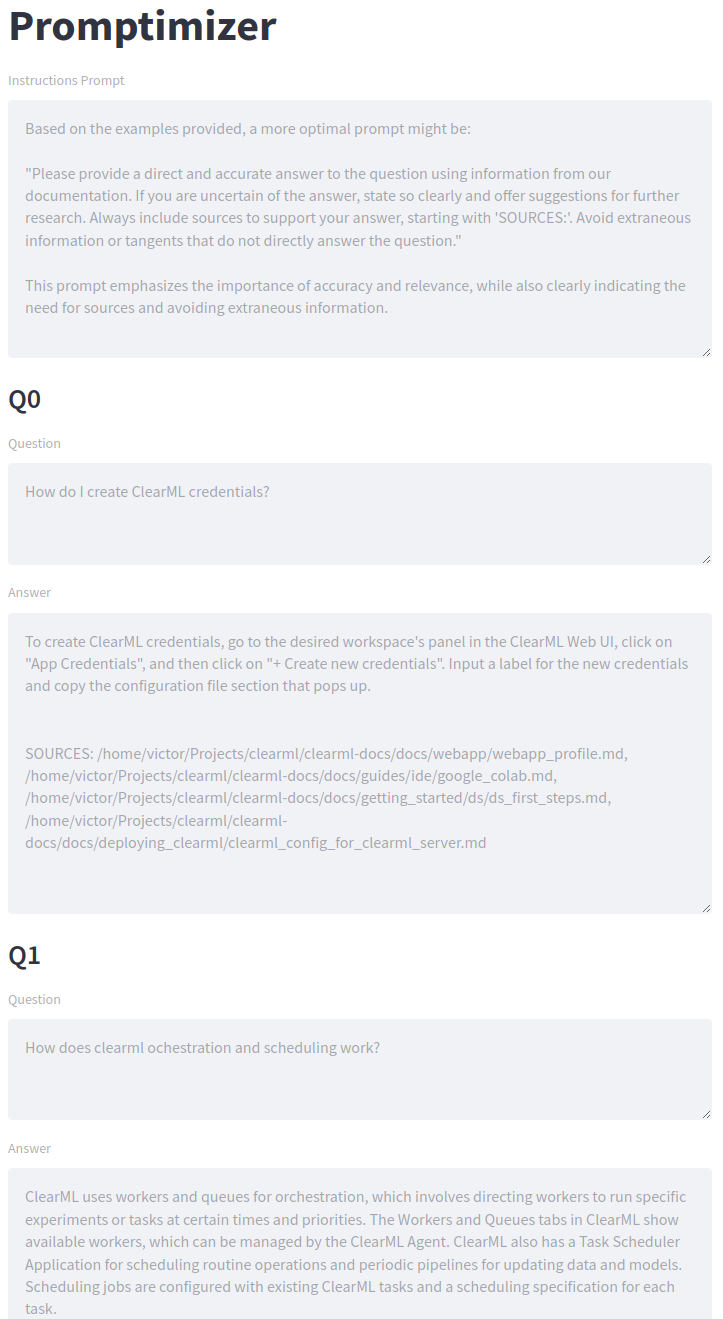
To make everything pretty and easy to deploy, we wrapped the Langchain process into a Streamlit app. As you can see in the screenshot, the structure is very similar to our diagram. First, there is the instructions prompt (for the QA bot). This will be generated by the LLM and is the prompt we’re optimizing.
Next, we have a number of sample user questions. This is where your Quality Assurance team will come in. They can have full freedom on which sample questions to ask and potentially come up with a standardized way of scoring them.
Finally, the scoring section can be used by any colleague to assess the quality of the responses. This feedback is fed back into the system by appending it as an example for the prompt generator. After clicking the submit button, a new round of generation will begin. We’re doing gradient descent using nothing but text!
Deploying it with ClearML
Versioning your documentation data
When using your documentation for embedding and then later as reference info for the QA bot, it makes a lot of sense to use ClearML-Data to version control this data. In this way you can always easily revert, see any made changes and easily automate the data generation based on e.g. a new version of the documentation.
Experiment Management
ClearML has a native integration with Langchain, so every time you run a chain, ClearML will keep a record of which exact calls were made to the OpenAI API and what all the return values were. This allows for easy debugging but also serves as a searchable history of your experiments.
Streamlit deployment
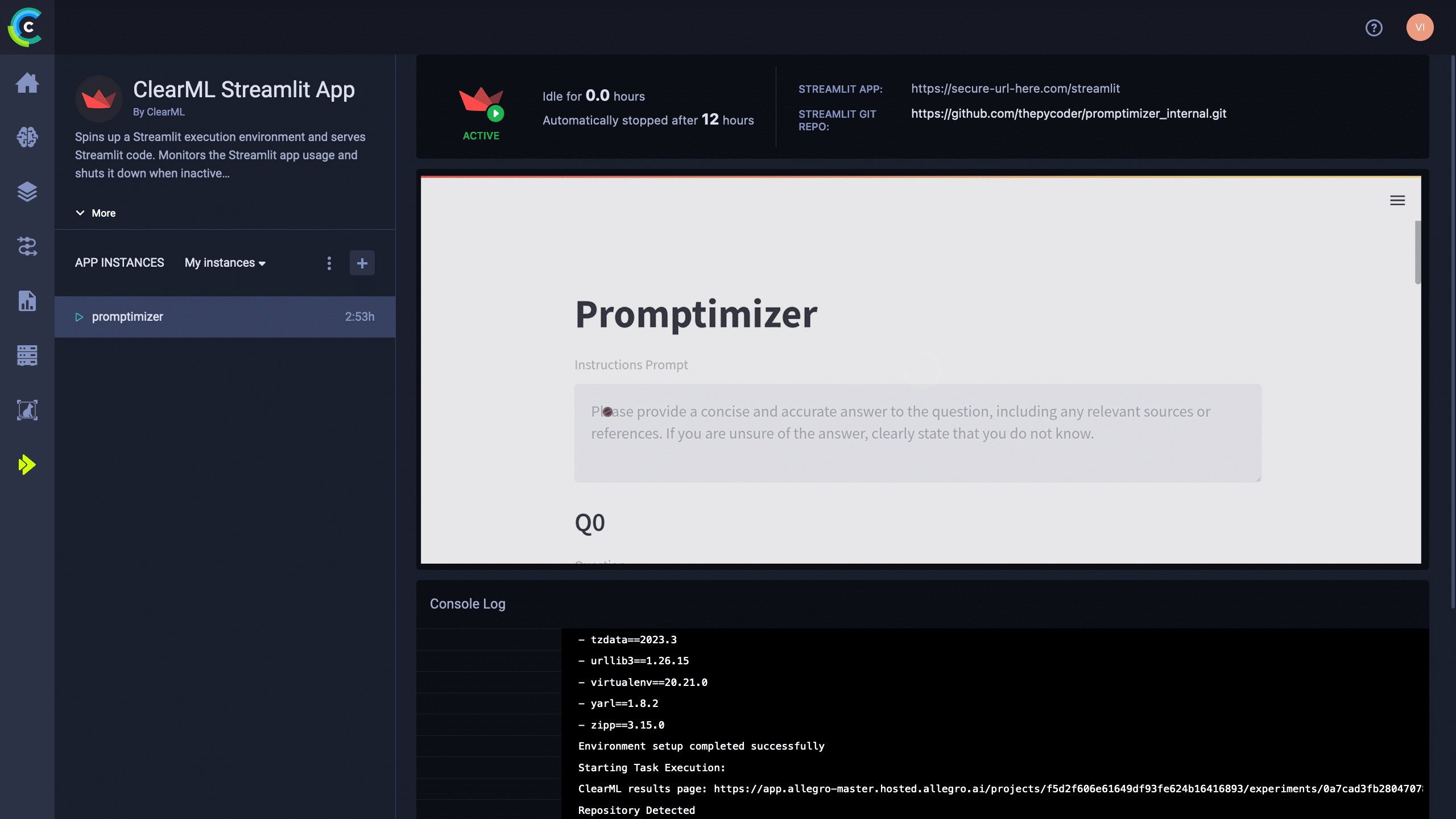
Enterprise users can even host their gradio and streamlit apps directly from within the ClearML webUI. In this way, the whole system is integrated and you have a clear (pun intended) overview of the whole flow.
Results and Code
As you can see from the screenshot above, the bot didn’t do a very good job in reporting its sources (in the right format). So that will be our main feedback for this prompt. After clicking submit, the second prompt seems much better already and the generated answers reflect this.
We did quite some testing and playing around. The results are quite hard to objectively quantify, but anecdotally, the prompts do get better although it is questionable if the process is easier than simply creating the prompts yourself and testing them out.
However, it was an interesting experiment nonetheless and this approach is much more scalable if you have a large number of people that can label the prompts.
If you want to play around with this yourself, you can find the code on GitHub here.
Next Steps
This is only the beginning of what these Large Language Models can do. LLMOps, too, is only in its infancy. In future blog posts, we want to explore LLMOps further, so let us know which challenges you face and what you would like to see us demonstrate.
Next to the use case, it’s also going to be very interesting when the open-source, self-hosted versions of these models come into play. Then we’ll have to start dealing with LLMOps on-prem, which is going to be super interesting and challenging in its own right.
Finally, it’d be interesting to see completed LLM Infrastructure architectures in production, when more and more of our Clients start to use ClearML for their end-to-end LLMOps journey. We, for one can’t wait!
Post your suggestions in our Slack channel and we will be more than happy to discuss 🙂