
Or: How to Set up an Efficient Orchestration Environment for ML / DL on Kubernetes
If your company has already started getting into machine learning / deep learning, you will quickly relate to the following story. If your company is taking its first steps into data-science, here is what is about to be dropped on you. If none of the above strikes a chord, well it’s probably good to know what’s out there because data-science is all the rage now, and it won’t be long until it gets you too 🙂
The data-science team would like to keep developing their code on their laptops, but unfortunately for them, this is not possible. Their machines either lack memory or storage or they need GPU or several GPUs for added horsepower, and so they have to start working on remote machines. The code that they will be running on those machines will run from several hours to several days, and since it’s quite long, they obviously want to try different configurations / parameters and whatnot. DevOps to the rescue, you might think: let’s get them a K8s cluster and let them run their containers and leave us alone. Well, if only it was that easy…
To further explain this, let’s start with a quick set of rules you might be familiar with. Things you should AVOID doing on your K8s Cluster:
- Place all pods in the same namespace
- Manage too many different types of pods/repos workloads manually
- Assume you can control the order of the K8s scheduler
- Leave lots of stale (used once) containers hanging around
- Allow node auto-scaling to kick automatically based on pending jobs
- Give data-science teams your mobile number 😉
In a nutshell, the first rule of DevOps is: do not allow R&D teams to access your K8s cluster. This is your cluster not theirs 🙂
That said, with DL (and occasionally ML), the need to run heavy workloads is required from relatively early in the development process, and it continues from there. To top that, unlike traditional software, where a tested and (usually) stable version is deployed and replicated on the K8s cluster, in ML / DL the need is to run multiple different experiments, sometimes in the hundreds and thousands, concurrently.
In other words, unless we want to constantly set up permissions & resources for the continuously changing needs of the data-science teams, we have to provide an interface for them to use the resource we allocated for them.
Lastly, since we are the experts on K8s & orchestration in general, the data-science team will immediately come to us to support them in dockizing their code & environment. When things are simple, everything works. But since ML / DL code is unstable and packaging sometimes takes time, we will need to have it as part of the CI. Which means that the data-science team will have to maintain requirement/YAML files. And since these experiments are mostly ephemeral, we will end up building lots (and lots) of dockers that will be used only once. You see where this is going. Bottom line, someone needs to build something that dockizes the ML / DL teams’ environments, and I – for one – would rather not be that someone.
Let’s decompose the requirements list into its different ingredients:
- Resource Access:
For DevOps, resource access means permissions / security, reliability, location etc.
For a data scientist, resource access means which resource type to use and its availability. That’s it. Even a resource type that could be defined at low granularity is usually an overkill from the development teams’ perspective. What they care about is whether it is a CPU or a GPU machine and the number of cores. Three or four level settings for these resources (e.g. CPU, 1xGPU, 2xGPU, 8xGPU etc.) would probably be enough for most AI teams. - Environment Packaging:
Environment packaging is usually thought of as containerizing your code base. This is a reasonable assumption coming from a DevOps perspective.
For AI data science teams maintaining a docker file, a requirement.txt and updating Conda YAMLs is possible. However it’s a distraction from their core work, it takes time and it is easy to leave behind old setups because they are not used in the coding environment itself. The development environment is constantly changing and so the key is to extract the information without the need to manually keep updating it. Lastly, replicating environments easily from local machines to remote execution pods is also needed. - Monitoring:
For DevOps, monitoring usually means HW monitoring, CPU usage, RAM usage, etc.
For data science teams, monitoring is about model performance, speed, accuracy, etc. AI teams need to be able to monitor their applications (processes / experiments, whatever we call them) with their own metrics and with an easy to use interface. Unfortunately there is no standard for this kind of monitoring, and oftentimes adding more use case specific metrics gives the data science team a huge advantage in terms of understanding the black-box. This too is a constantly changing environment that needs to allow for customization for the data scientists. - Job Scheduling:
For DevOps, using K8s job scheduling is akin to resource allocation. E.g. a job needs resources which it will use for unlimited amounts of time. If we do not have enough resources, we need to scale.
For data science teams, job scheduling is actually an HPC challenge. Almost by definition there will never be enough resources to execute all the jobs (read: experiments) at the same time. On the other hand, jobs are short lived (at least relative to the lifespan of servers), and the question is which job to execute first and on which set of resources?
Kubernetes is a great tool for us to manage the organization’s HW clusters, but it is the wrong tool to manage AI workloads for data science & ML engineering teams.
So, is there a better way? Of course! It’s called Kubernetes 😉
To address the specific needs of data science and ML engineering teams, ClearML designed an AI-Ops / ML-Ops solution called ClearML. It is part of the ClearML open source full solution for ML / DL experiment management, versioning and ML-Ops.
Since in most organizations K8s is already used for managing the organization’s HW resources, Trains Agent was designed to run on top of your K8s. However, ClearML can also manage orchestration directly on bare metal, other orchestration solutions such as SLURM or any combination thereof. In other words, it can utilize on-prem workstations to ease the load on the K8s cluster when everyone is at home.
From a K8s perspective, trains-agent-pod is just another service to spin, with exact multiple copies, with replicated setup, on different resources. Just like we would do with any other application running on our K8s. It also means you can seamlessly deploy the trains-agent-pod on multiple or single GPUs, share resources, mount storage etc. All to the comfort of the AI teams.
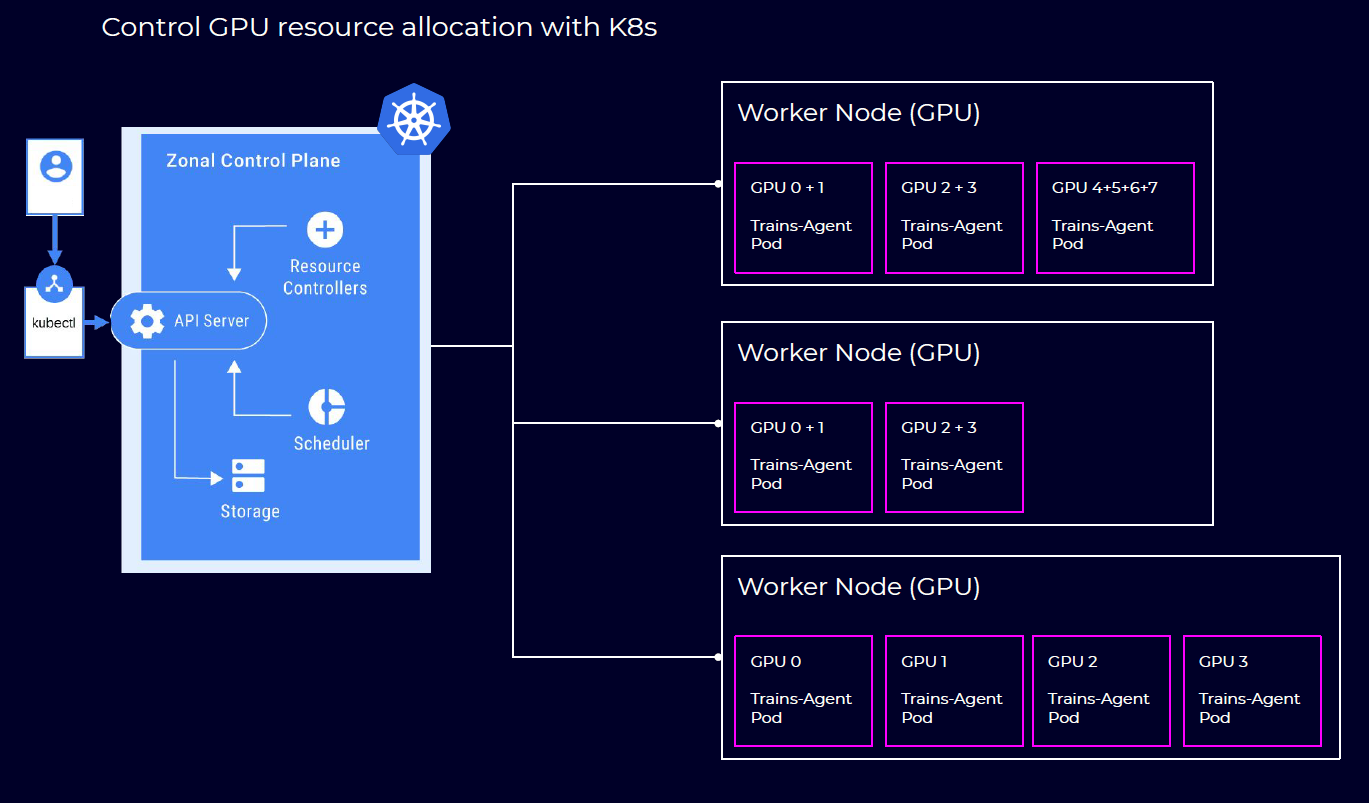
The data science team and ML engineers interface with the K8s nodes is facilitated through a totally different interface. They view trains-agent-pods as nodes on their own “cluster”, for which they are given the ability to launch their jobs (experiments) directly into the trains-agent execution queue, without interfering with any of the K8s schedulers.
What the trains-agent-pod does is to pick a job from the ClearML job execution queue (with priorities, job order and a few more things), then set up the environment for the job, either inside the docker or as sibling docker, and monitor the job (including terminating it if the need arises).
his means ClearML maps a trains-agent-pod resource to exactly one job (as expected) and divides management into two parts: resource allocation, provisioned by Kubernetes; and job allocation & execution performed by the ClearML system.
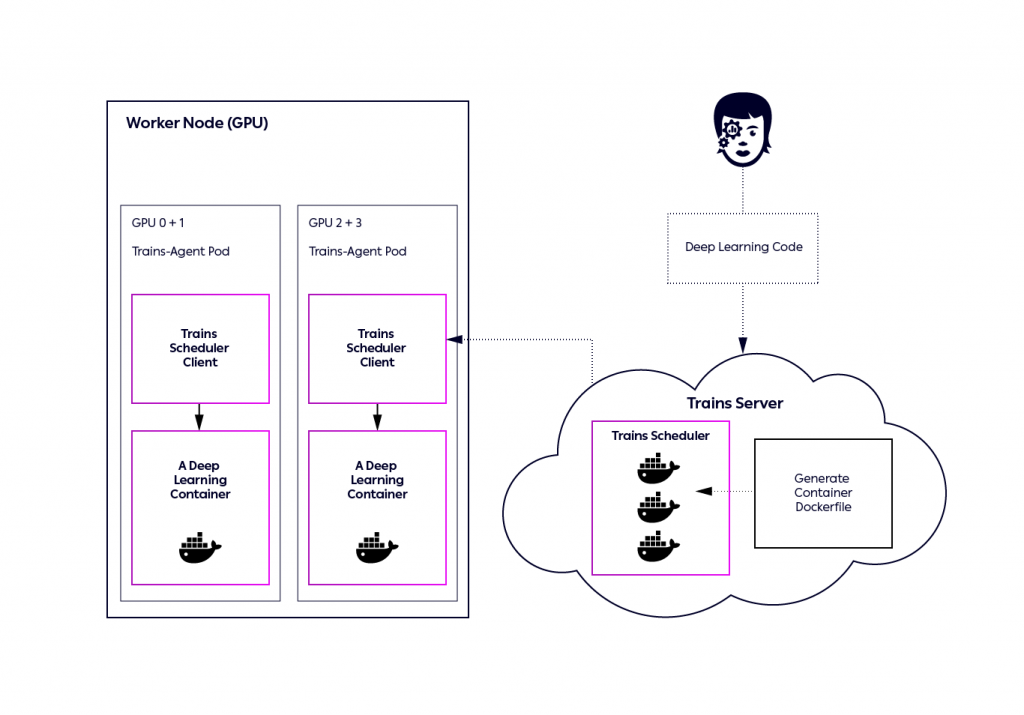
Here is how it works from A to Z:
- Kuberenetes spins trains-agent-pod pods on GPU instances, mapping job queues into different resources.
For example:
– 6 pods with 1xGPU per pod will listen to the single_gpu_queue
– 2 pods with 2xGPU per pod will listen to the dual_gpu - Data science and ML engineering teams work with the ClearML experiment manager that automatically logs the entire environment on which they are developing (including git repo packages etc).
- From the Trains web application, a data scientist or ML engineer can send an experiment (job) into an execution queue (for example single_gpu queue).
- Trains-agent-pod on one of the nodes picks the job from the job queue, sets up the environment needed, and starts executing the job, while monitoring it as well.
- Once the job is completed or aborted, the trains-agent-pod will pick the next one on the list.
- The AI team can control the order of jobs in the queue or move jobs from one queue to another, giving them the ability to select the type of resource their job will use. For example sending a job to the dual_gpu queue, makes sure only pods with 2 GPUs will pick the job for execution.
The DevOps team is only needed when new HW resources need to be allocated or resource allocation needs to be changed. For everything else, the users (read: AI team) self-service through the easy to use ClearML web interface, purposely built for their needs, while letting us, the DevOps team, manage the entire operation.
To summarize, here is what you need to do to make your life almost perfect:
- Get the trains-agent-helm from Github / Nvidia NGC
- Allocate X GPU and Y CPU pods
- Generate a user/pass configuration file
- Email everyone their user/pass
- Go get a beer, you have done your part, data science rocks!
To learn more about how to install ClearML & Trains Agent and get started, refer to the documentation or watch the quick introductory video. If you’re an Nvidia customer, you can read more here or get started quickly from the ClearML NGC container.