
What if I want to serve a Huggingface model on ClearML? Where do I start?
In general, machine learning engineers know by now that a good model serving engine is invaluable when serving models in production. These days, NVIDIA’s Triton inference engine is a popular option to do so, but it is lacking in some respects.
In particular, defining custom model monitoring metrics can be a hassle, because a developer has to integrate them using Triton’s low-level C API to do so. Next to that, running custom python code, such as for pre- and postprocessing, is also not very straightforward. It is possible to define custom python endpoints and then combine them into a single API call using an ensemble structure. Not only is this structure cumbersome, but it also prevents you from auto-scaling your (usually CPU-bound) pre- and postprocessing code. It is possible to scale an endpoint in Triton, but only manually, which is not ideal in this case, leading to a possible bottleneck to the GPU serving of the actual model.
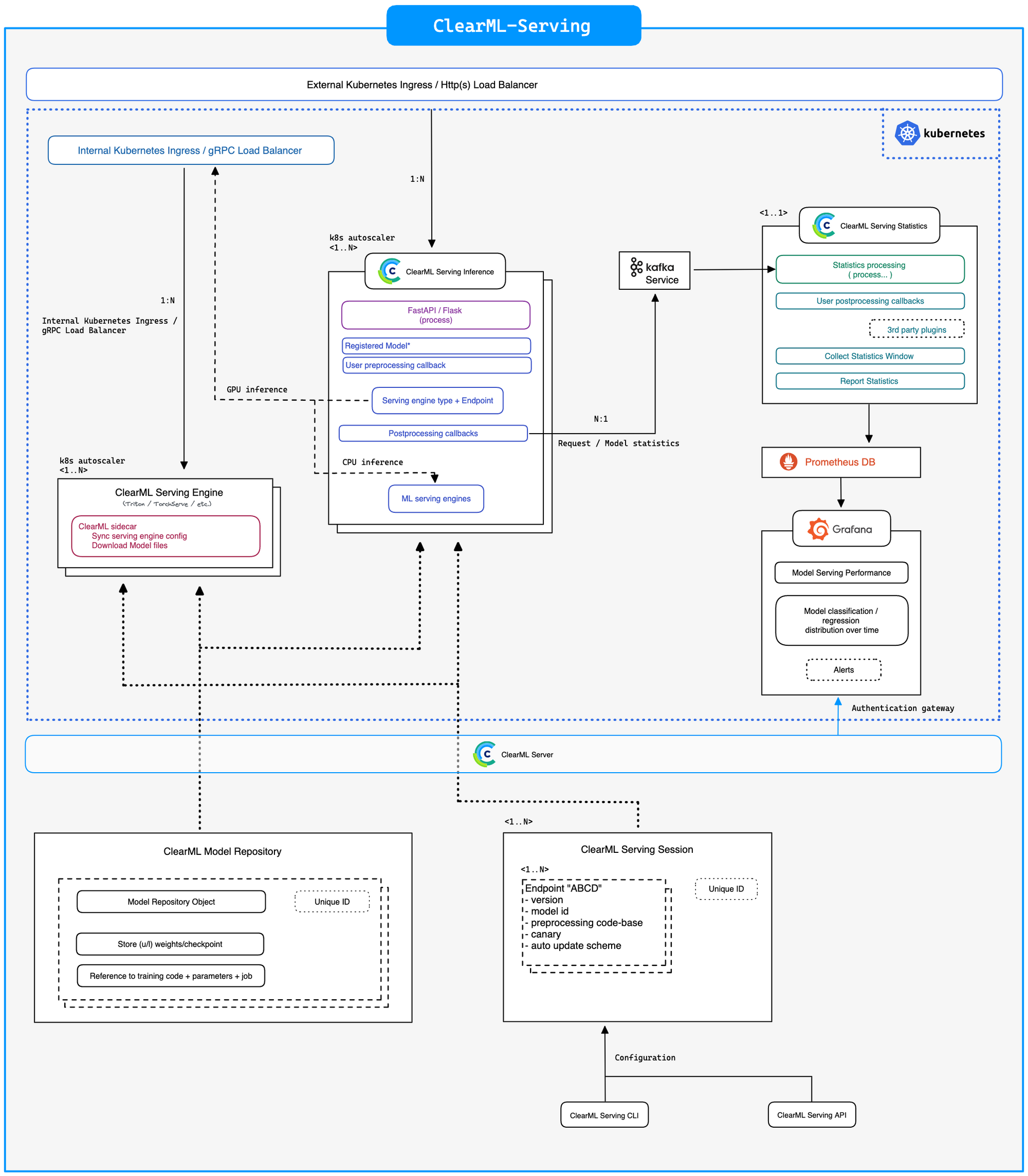
ClearML-Serving Architecture
In order to combat these issues with Triton, but still make use of its excellent performance, we have created ClearML-Serving. It creates a fully auto-scalable inference container that can run custom pre- and postprocessing code as well as capture any user-defined metrics and pipe them to Prometheus and Grafana.
Next to these advantages, ClearML-Serving also integrates very well into the rest of the ClearML ecosystem if you want it to. Easily deploying models that are already stored using the experiment manager and fully supporting automation such as triggers and pipelines.
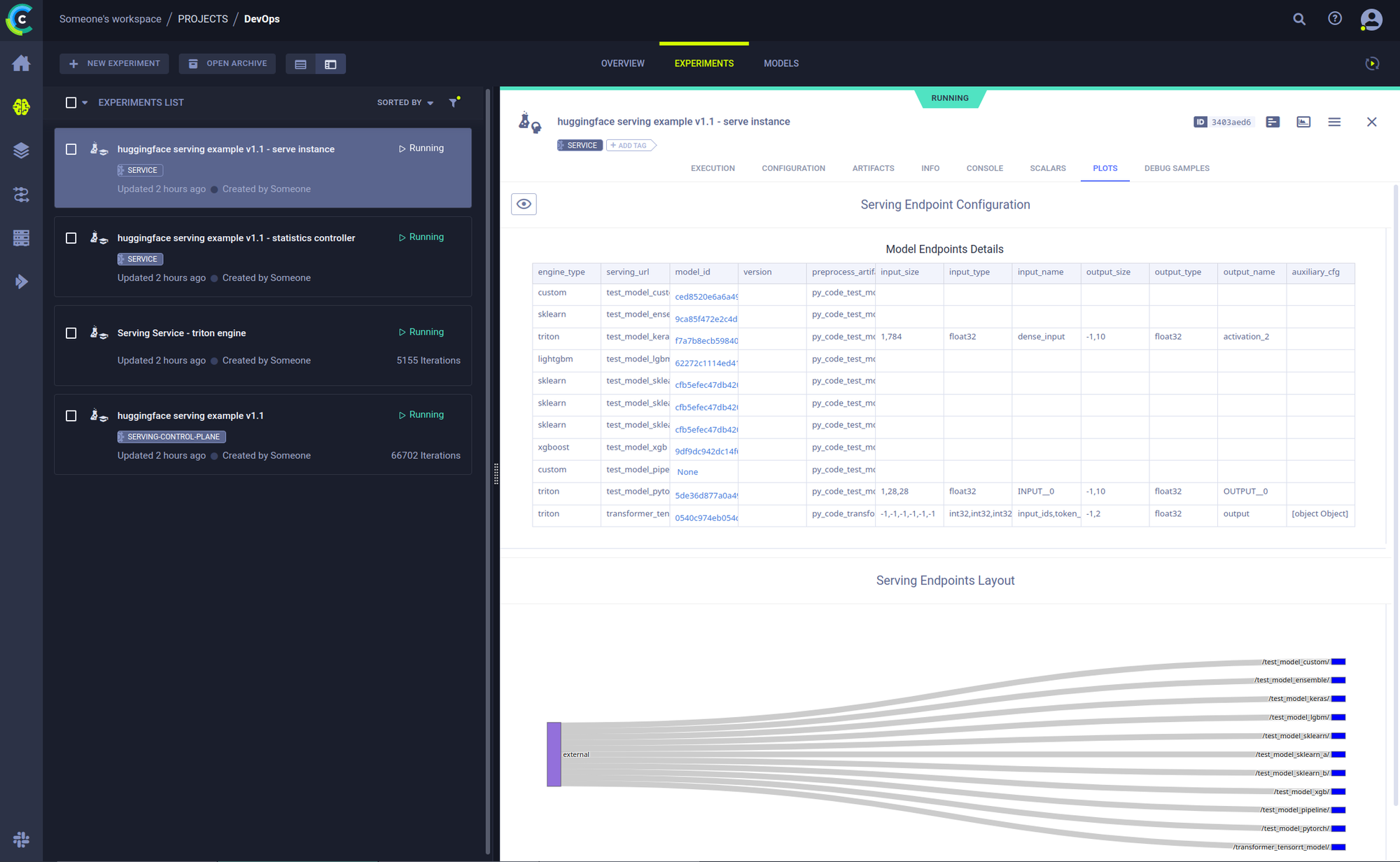
Just like anything else in ClearML, a serving instance is a Task, which will keep track of console output, version history and basic machine monitoring. In short, it extends your favorite open-source MLOps toolbox with yet another open-source tool for you to enjoy.
Serving a Hugginface model
This blogpost will cover some of the resources, findings and best practices to note while deploying models. Our example in the ClearML-Serving repository shows you step-by-step how to set it up on your own machine.
A model and a tokenizer
Most models available on Huggingface these days are made in Pytorch. Technically, Triton actually supports Pytorch models out of the box, so you just can just serve the model that way if you prefer. It’s not just the model though.
A lot of models require what is called a tokenizer, to preprocess the incoming data first, before sending it to the model. Huggingface themselves actually have a nice video that explains the concept. Barring more complex approaches, it is a sort of lookup table made in advance, that converts text inputs to numbers that the model can actually work with.
It would be bad practice to expect a user request (e.g. an API call from a webpage) to do this tokenization client-side. That would mean the tokenizer is spread out over every single device or endpoint that wants to do an API request to the server and would be a nightmare to keep updated in lockstep with the model itself.
Instead, it makes a lot of sense to deploy the tokenizer as a preprocessing step, server-side, right before a request reaches the model server itself. ClearML-Serving makes this easy to do by allowing you to specify a custom python preprocessing class that does this for you.
"""Hugginface preprocessing module for ClearML Serving."""
from typing import Any
from transformers import AutoTokenizer, PreTrainedTokenizer, TensorType
# Notice Preprocess class Must be named "Preprocess"
class Preprocess:
"""Processing class will be run by the ClearML inference services before and after each request."""
def __init__(self):
"""Set internal state, this will be called only once. (i.e. not per request)."""
self.tokenizer: PreTrainedTokenizer = AutoTokenizer.from_pretrained("philschmid/MiniLM-L6-H384-uncased-sst2")
def preprocess(self, body: dict, state: dict, collect_custom_statistics_fn=None) -> Any:
"""Will be run when a request comes into the ClearML inference service."""
tokens: BatchEncoding = self.tokenizer(
text=body['text'], return_tensors=TensorType.NUMPY, padding=True, pad_to_multiple_of=8
)
return [tokens["input_ids"].tolist(), tokens["token_type_ids"].tolist(), tokens["attention_mask"].tolist()]
def postprocess(self, data: Any, state: dict, collect_custom_statistics_fn=None) -> dict:
"""Will be run whan a request comes back from the Triton Engine."""
# post process the data returned from the model inference engine
# data is the return value from model prediction we will put is inside a return value as Y
return {'data': data.tolist()}
The one blog post to rule them all
This blog post, written by Michaël Benesty (also known as the excellent name pommedeterresautee), is an excellent resource to get started with deploying a Huggingface model on Triton.
The accompanying GitHub repository offers a convert_model command that can take in a Huggingface model and convert it to ONNX, after which it can be optimized using TensorRT.
This is an excellent start and even if the conversion does not work outright, the code itself offers a very nice boilerplate to bootstrap your own conversion workflow. Model conversion is not an easy task, so any people working on it in this capacity are a godsend.
A note on TensorRT, ONNX, and Triton versions
“Deep learning model conversion” roughly translates to dependency hell. Docker containers and lots of patience are advised. Here is a short rundown of things to take into account.
Triton only serves TensorRT model binaries that are compiled for exactly its own version and nothing else. No backwards compatibility.
ONNX versions are tied in lockstep to TensorRT versions to ensure compatibility. You can check the compatibility matrix here.
Then we’re not even talking yet about which version of Pytorch was used to train the model originally and how it relates to ONNX.
Chances are very high that the transformer-deploy docker image has a different triton version than what ClearML-Serving uses at any given time, which will give issues later on. Check this page for more information about which TensorRT version is shipped in which Triton container.
If they don’t match up, the ClearML Triton image has been built by us for a few different versions of Triton, if none of them match what you need, build the image locally with the right Triton version and make sure it is picked up by docker compose when you set up the stack, or build the transformers-deploy image locally with the correct version and use it to run the model conversion. Your model has to be optimized using the exact same TensorRT version or it will not serve!
Deploying the models
Once you’ve read through all of that, it’s time for actual deployment. This is not the focus of this blogpost, to learn more, check out the README here. But in short, there’s only a few steps you need to do in order to get things going (after initial ClearML-Serving setup of course).
- Upload the model file
clearml-serving --id <your_service_ID> model upload --name "Transformer TensorRT" --project "Hugginface Serving" --path model.bin
- Create an endpoint for it
clearml-serving --id <your_service_ID> model add --engine triton --endpoint "transformer_tensorrt_model" --model-id <your_model_ID> --preprocess examples/huggingface_tensorrt/preprocessing.py --input-size "[-1, -1]" "[-1, -1]" "[-1, -1]" --input-type int32 int32 int32 --input-name "input_ids" "token_type_ids" "attention_mask" --output-size "[-1, 2]" --output-type float32 --output-name "output" --aux-config platform=\\"tensorrt_plan\\" default_model_filename=\\"model.bin\\"
Hotswapping models & Canary deployments
One cool thing you can do using ClearML-Serving is seamlessly updating models to a new version, simply by using the command line. The clearml Serving Service supports automatic model deployment and upgrades, directly connected with the model repository and API.
When the model auto-deploy is configured, a new model versions will be automatically deployed when you “publish” or “tag” a new model in the clearml model repository. This automation interface allows for simpler CI/CD model deployment process, as a single API automatically deploy (or remove) a model from the Serving Service.
clearml-serving --id <service_id> model auto-update --engine triton --endpoint "transformer_tensorrt_model" --preprocess "preprocess.py" --name "Transformer TensorRT" --project "Hugginface Serving" --max-versions 2
You can even set up canary deployments, where x% of people get served model A and 100-x% of people get model B, fully configurable of course 🙂
# First add 2 endpoints corresponding to your requirements
clearml-serving --id <service_id> model canary --endpoint "transformer_tensorrt_model" --weights 0.1 0.9 --input-endpoints transformer_tensorrt_model/2 transformer_tensorrt_model/1
Next Steps
In a following blogpost, we aim to add our own benchmarks to the excellent timings provided by the blogpost mentioned above. It would be very interesting to see just how much the independent scaling possibility is contributing to the final inference speed.
Next to that, we will show you how to add custom metrics to a serving instance, which will allow you to monitor your whole list of endpoints using Prometheus and Grafana.
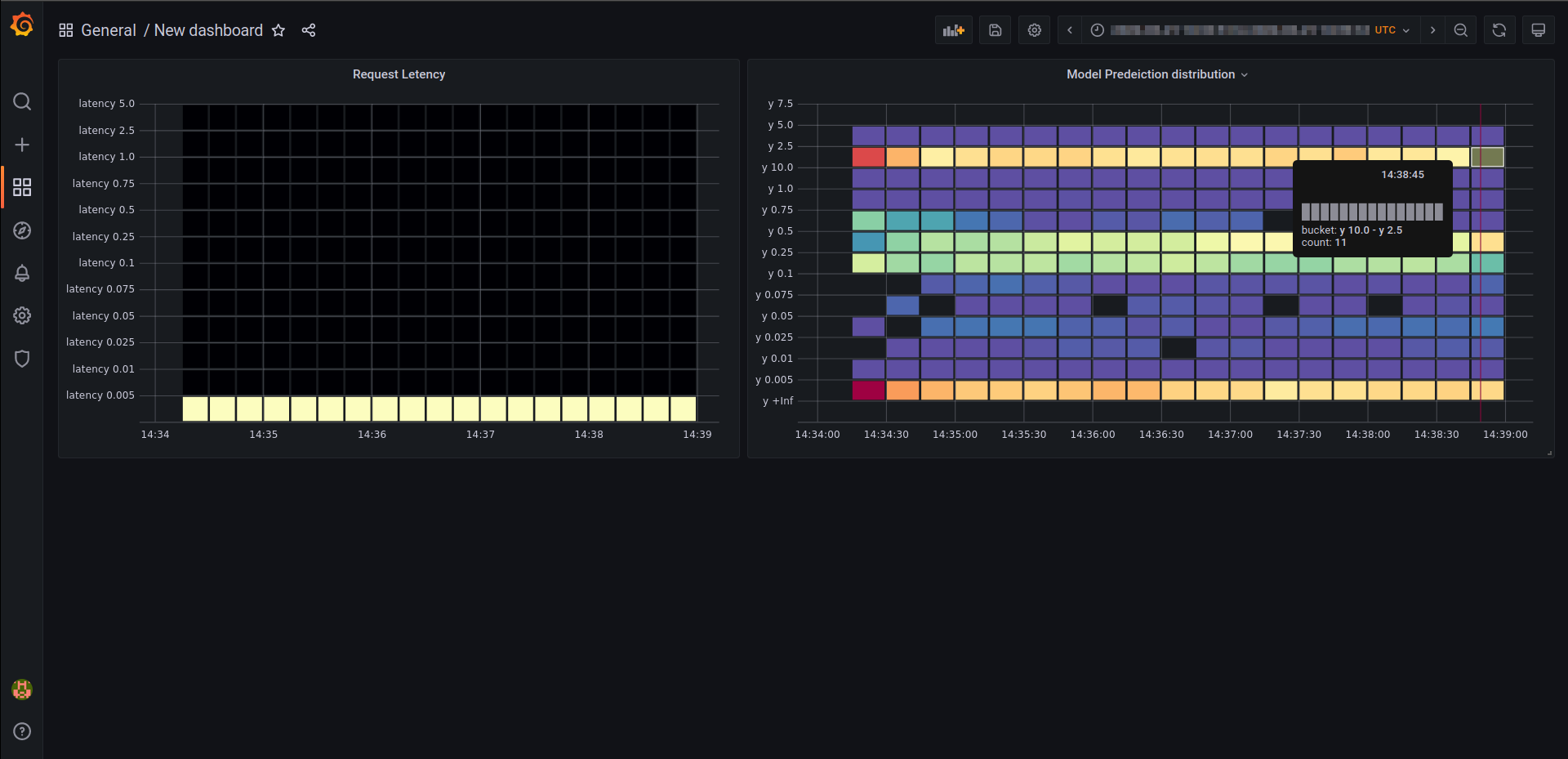
Stay tuned!