Republished here with PyTorch permission – original post on PyTorch Medium.
Authored by Dan Malowany
This blog post is a first of a series on how to leverage PyTorch’s ecosystem tools to easily jumpstart your ML / DL project. The first part of this blog describes common problems appearing when developing ML / DL solutions, and the second describes a simple image classification example demonstrating how to use Allegro Trains and PyTorch to address those problems. In the coming week, we’ll release blog posts as a part of this series, focusing on examples for different use cases and data types, such as, text and audio. However, the principles demonstrated in this post and the others are all completely data agnostic.

Allegro Trains is an open-source machine learning and deep learning experiment manager and ML-Ops solution developed at Allegro AI that boosts GPU utilization and the effectiveness and productivity of AI teams. This solution provides powerful, scalable experiment management and ML-Ops tools with zero integration effort. As a part of the PyTorch ecosystem, Allegro Trains helps PyTorch researchers and developers to manage complex machine learning projects more easily. Allegro Trains is data agnostic and can be applied to structured data, image processing, audio processing, text processing and more.
Challenges in Deep Learning Projects
Every data scientist knows that machine and deep learning projects include way more tasks than just choosing the model architecture and training the model on your data. Machine learning projects include ongoing trial and error efforts that resemble lab scientific experiments more than a software development workflow. This is the reason that training sessions are commonly called experiments and a platform that helps manage these sessions as an experiment manager.
This unique workflow gives rise to several challenges that might substantially complicate and prolong the time a machine learning project converges to the required results.
Since a project includes numerous experiments, you need a simple and easy way to track these experiments, log all the hyperparameters values being used and enable reproducing an experiment that was successful even weeks and months later, when new data arrives. To do so you need to integrate an experiment manager to your workflow.
Another known challenge are the DevOps efforts that can consume a big chunk of the data scientist’s time if not managed properly. Training models is a process that takes time — hours and even days. As such, it is common practice to have training machines — local and cloud machines — allocated to perform the training sessions, while the data scientists’ own machines are reserved for further development of the project’s codebase. Managing all these machines, requires an ongoing DevOps effort: Setting up the machines, introducing a queue management system to manage the stream of experiments being sent to the machines and monitoring the status (GPU, CPU, memory) of the machines.
Furthermore, with time, different data scientists will use different versions of deep learning frameworks, such as PyTorch, that require different versions of Cuda, Cudnn and other packages. In addition, the different Python package versions will change from one person to another. Creating and spinning up adequate containers for each machine based on the experiment being sent can be frustrating.
To solve these challenges and more, you are encouraged to use Allegro Trains and other tools in the PyTorch ecosystem.
Let’s take a simple image processing example to demonstrate how these tools can help solve these challenges and many more. The full code can be found here.
Allegro Trains to the Rescue
The first tool we will discuss is the Allegro Trains experiment manager and ML-Ops solution. Trains supports experiment tracking, analysis, comparison, hyperparameter tuning, automation, reproducibility and a variety of additional features. It is a suite of three open source components:
- Trains Python package — This Python package allows you to integrate Allegro Trains into your Python code, with only two lines of code.
- Trains Server — This is Allegro Trains’ backend infrastructure. You can deploy your own self-hosted Trains Server in a variety of formats, including pre-built Docker images for Linux, Windows 10, macOS, pre-built AWS EC2 AMIs, and Kubernetes.
- Trains Agent — Trains Agent is the DevOps component of Allegro Trains that enables remote experiment execution, resource control and automation (like Trains’ built-in Bayesian hyperparameter optimization).
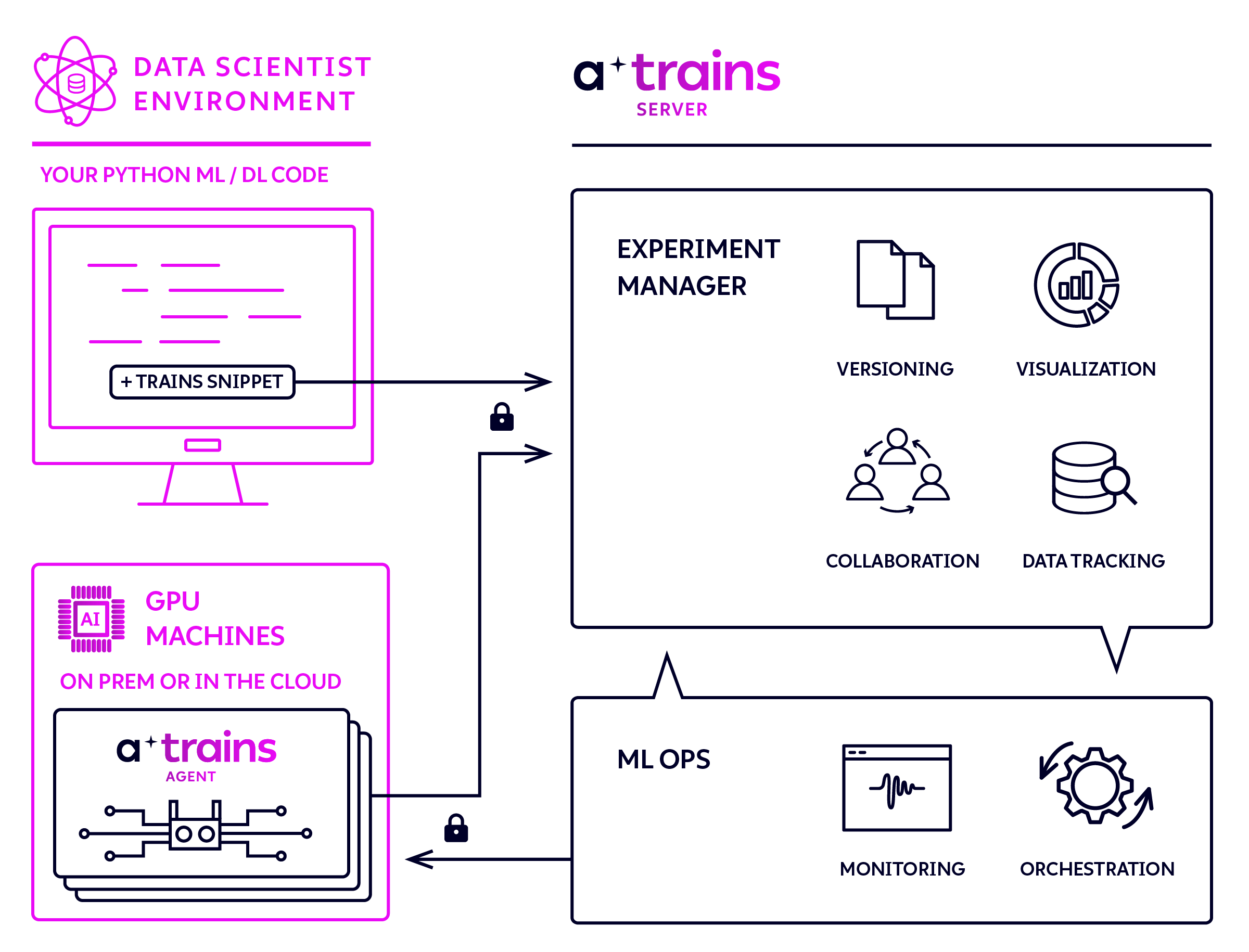
One of the great things about Allegro Trains is that there is zero integration effort to use with PyTorch. You only need to add the following two lines of code at the top of your main script and you are set to go:
from trains import Task task = Task.init(project_name='Image Classification', task_name='image_classification_CIFAR10')
Allegro Trains organizes your PyTorch developments into projects, so once you will execute your code your experiment will be logged under the relevant project in the web app. Now that we integrated our code to Allegro Trains, we can enjoy all the benefits that come with it:
- Reproducibility — All the execution data for each experiment is — automagically — logged on the Trains Server: git repository, branch, commit id, uncommitted changes and all used Python packages (including their specific versions at time of execution). This ensures that it is possible to reproduce the experiment at any time. We are all familiar with cases where a package version changes and our script simply doesn’t work anymore. This feature helps us avoid having to troubleshoot such frustrating cases.
- Improved teamwork — With Allegro Trains there is continuous sharing of what each team member is doing, which enables visually brainstorming the results, effectively debating issues and possible remediations with teammates and sharing an experiment that performed well on one use case to easily be applied to another use case by a teammate working on another project.
- Effortless experiments tracking and analysis — Allegro Trains web app includes a variety of analysis and comparison tools, such as creating a leaderboard ranking all the team’s experiments based on a chosen metric, parallel coordinates and more.
There are many more features of and benefits from using Allegro Trains, some of which we will discuss later on. For now let’s go back to our code.
Next you want to make sure all the parameters are reflected in the experiment manager web app and that there are no “magic numbers” hidden in the code. You can use the well known argparse package and Allegro Trains will automatically pick it up. Or you can just define a configuration dictionary and connect it to the Allegro Trains task object:
configuration_dict = {'number_of_epochs': 3, 'batch_size': 4, 'dropout': 0.25, 'base_lr': 0.001}
configuration_dict = task.connect(configuration_dict)
Now it is time to define our PyTorch Dataset object. It is always useful to use the built-in datasets that come with PyTorch’s domain libraries. Here we will use the CIFAR10 dataset that can be easily loaded with the popular torchvision. We will also use PyTorch’s DataLoader that represents a Python iterable over a dataset. The DataLoader supports single- or multi-process loading, customizing loading order and optional automatic batching (collation) and memory pinning:
Next we will define our model. PyTorch enables easy and flexible model configuration that makes researching model architecture as easy as possible. In our example, we will create a simple model:
It is important to note that torchvision also includes a useful set of popular pretrained models that can be a great backbone basis for every model you want to build.
Although TensorBoard is part of the TensorFlow framework, it is fully integrated into PyTorch as well. This enables an easy way to report scalar values (such as loss, accuracy, etc.), images (for example the images we fed into our model for debug purposes) and more. Here comes another automagical feature of Allegro Trains — it will automatically pick up all the reports sent to TensorBoard and will log them under your experiment in the web app. So let’s add TensorBoard to our code and use it to report the loss value during the training session:
During the test session that comes at the end of each epoch, we can report some debug images with their ground truth labels and the prediction made by the model, as well as the accuracy per label and the total accuracy:
Finally, at the end of the experiment, we want to save the model. So we will finish our code with:
ch.save(net.state_dict(), './cifar_net.pth')
Allegro Trains will automatically detect that you are saving the model and will register the model location to the experiment in the Allegro Server. It is recommended to upload a copy of the model to a centralized storage (local or cloud), and Allegro Trains can do that for you, if such storage is available. Just easily add the centralized storage location when initializing Allegro Trains task object, and the snapshot will be stored in the designated storage and will be linked to your experiment, so you will have access to it from any of your machines.
Now all we have to do is run the experiment and watch its progress in the webapp. Allegro Trains not only logs all your reports, but also adds status reports on the machine and its GPU.
Note: As we didn’t install a Trains-server in this blog, the experiment will be logged on the Allegro Trains demo server. This demo server is meant for easy and fast experimentation with the Allegro Trains suite. Allegro Trains Python package automatically works with the demo server, if a self-hosted Trains-server wasn’t installed.
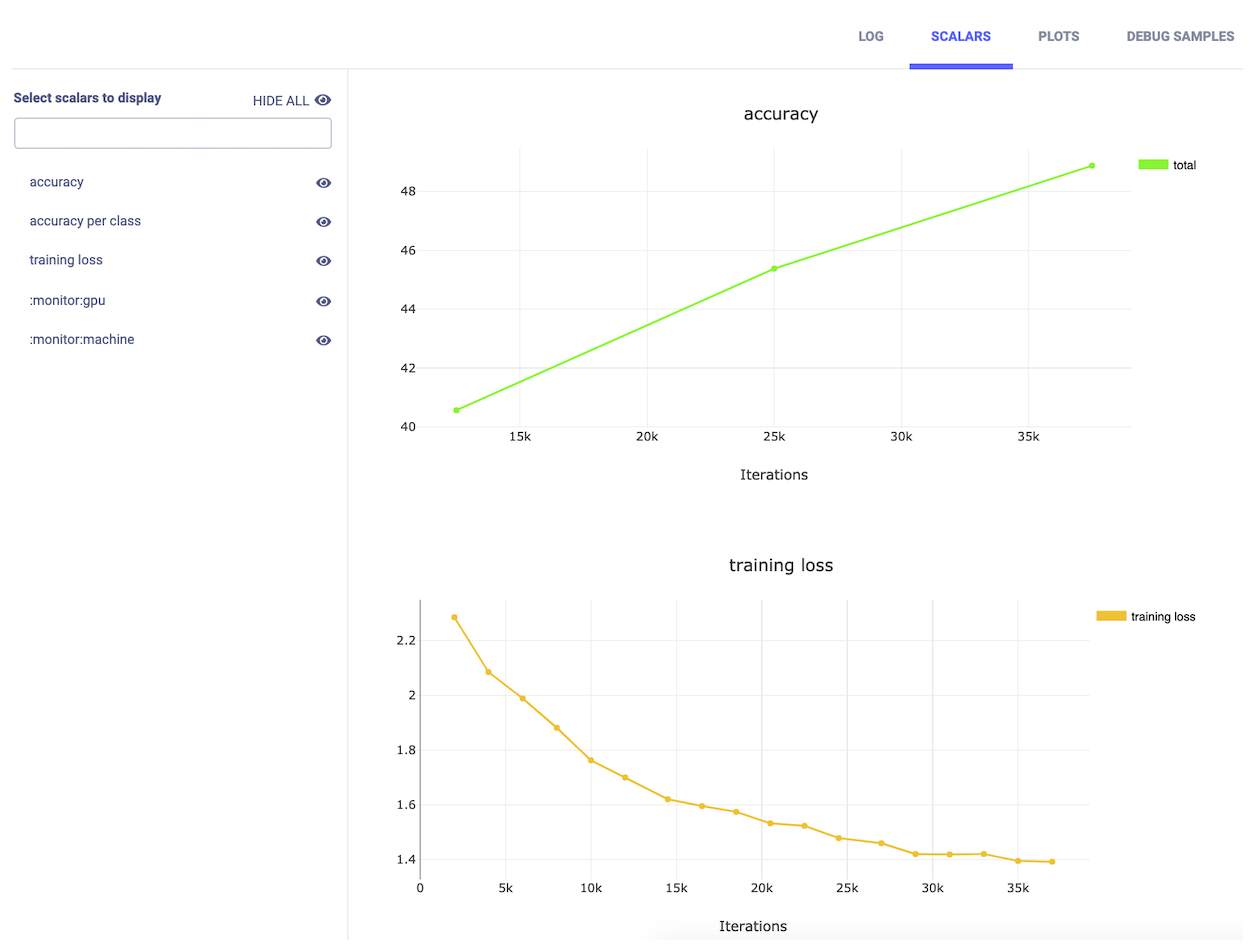
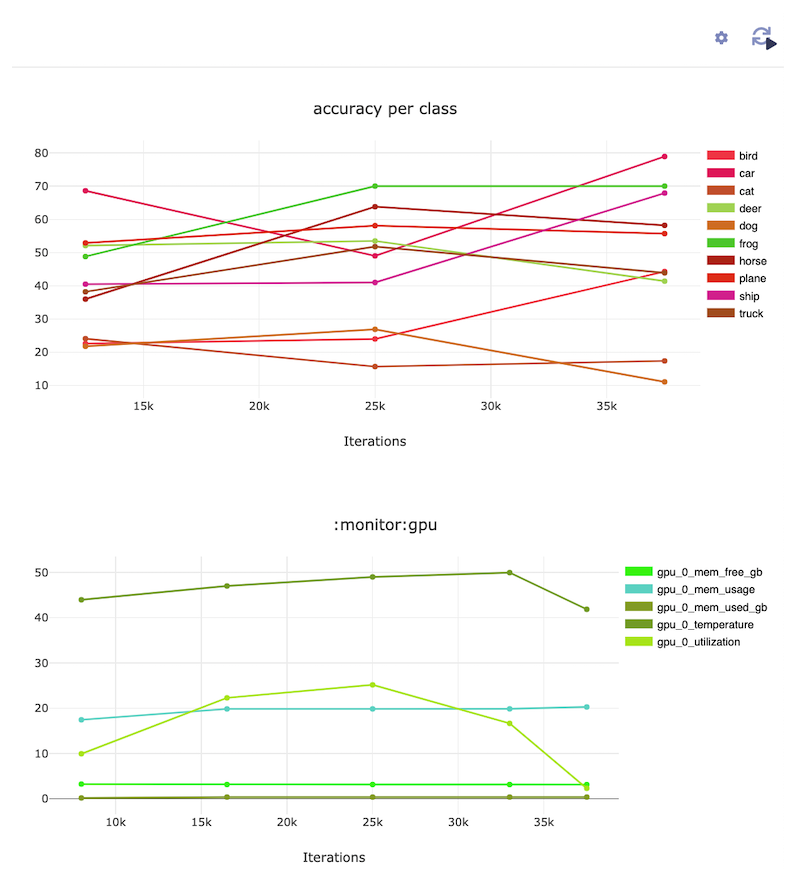
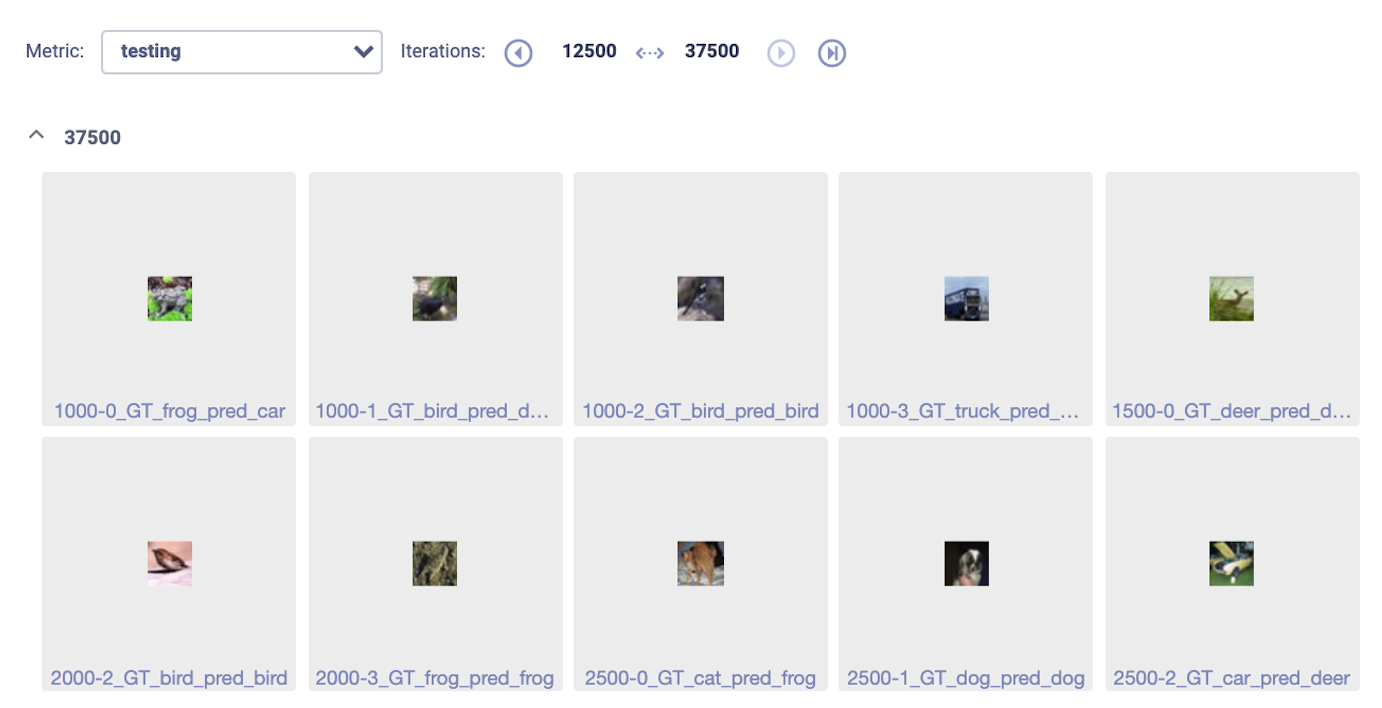
Now comes one of the best features of Allegro Trains: Once your experiments are logged into Trains Server, you can enjoy ML-Ops capabilities. All you need to do is install Trains Agent on each machine designated for executing the experiments. Trains Agent is a daemon that spins a container for you and runs your code. Whether it is an office computer or cloud machine, Trains Agent will make it available to the team members, with full queue management and machine diagnosis capabilities.
The installation of trains-agent is as simple as:
pip install trains-agent
Once installed, you execute a simple configuration command:
trains-agent inithttps://clear.ml/docs/deploying_trains/trains_agent_install_configure/#configuring-trains-agent
In order to register the machines into Trains Server, you simply create queues in the webapp and set the machine to listen to a specific queue:
trains-agent daemon -queue my_queue
All you have got left to do is to choose the task in the webapp, change the hyper parameters and trains-agent will take care of the rest. You can also name a container from DockerHub you want Trains Agent to use, when running your experiment. For example, just state that the requested docker is “nvidia/cuda:10.0-cudnn7-runtime” and your experiment will be executed within this docker. Now you can stop harassing the DevOps team every time you need a new Cuda version in your container. Python packages versions can also be updated from the webapp, so you don’t need a new container everytime you want to update the version of the numpy package.
Summary
Machine learning is an exciting field that has numerous applications. However, managing machine learning projects includes addressing many unique challenges. Companies tend to either neglect taking the time and effort to form an infrastructure that helps cope with those challenges, or try to build it themselves. In both cases, they end up diverting too much effort and focus from the core machine & deep learning research and development. The PyTorch ecosystem includes a set of open source tools that once integrated into your workflow, will boost the productivity of your machine learning team.
In this tutorial we demonstrated how using Allegro Trains, Torchvision and PyTorch built-in support for TensorBoard enables a more simple and productive machine and deep learning workflow. With zero integration efforts and no cost, you get an experiment management system and an ML-Ops solution.
To learn more about Allegro Trains, reference its documentation. In the next blog post of this series we will demonstrate how to leverage the tools discussed here to initiate an automatic bayesian optimization hyperparameter search on your experiment.