A Simple Hyperparameter Optimization Guide.
TL:DR;
- Modern optimization is done with a combination of an optimizer and an early stopping strategy
- Use Bayesian Optimization as your optimizer if you want an easy, but much better alternative to random search.
- Use Hyperband as an early stopper to make things more efficient
- Beware of using time as your early stopping budget

Gridsearch is easy, but really not very good. Random search is a bit better and still easy to use. If you’re willing to put in a little time to understand some of the more useful settings for Bayesian optimization, you can get a lot more out of a lot less (and without needing a statistical PhD).
Most advanced optimizers actually consist of 2 parts: an optimizer and an early stopping strategy.
Popular Hyperparameter Optimization frameworks are:
- Optuna: wide range of both optimizers and what they call “pruners” (early stoppers)
- HpBandSter: most well known for BOHB, a Bayesian optimizer and Hyperband as an early stopper
Both of which can be used in ClearML, you can see their usage in our previous blogpost and details in the documentation here.
Choosing an Optimizer: Just use Bayesian Optimization.

Optimizer choices are:
Grid search
Never use
Random search
Use if you have practically unlimited compute, a lot of time or a very high number of dimensions. Generally way better than Grid Search though.
Bayesian Optimization
In general, these are your best bet if you just want an out of the box, much better alternative to Random search. They’re also a good bet when your optimization budget (we’ll cover this down below) is small to moderate. BO is considered the to-beat for new algorithms in the field of hyperparameter optimization.
HpBandSter uses their own variant of the Tree Parzen Estimator (TPE) and that’s basically your only choice there, but it’s a very solid one.
Optuna, on the other hand, implements the original TPE algorithm as their Bayesian Optimization option.
These estimators will optimize a single objective metric though, if you have multiple objectives to optimize, you can take a look at Optuna’s MOTPE, which is a multiobjective version of TPE.
Other Algorithms
Then there are other, more “researchy” algorithms to try in Optuna such as Covariance Matrix Adaptation Evolution Strategy (CMA-ES) and the very interesting and intuitive genetic algorithms like Nondominated Sorting Genetic Algorithm II (NSGA-II).
These are very interesting, but need a bit more knowledge about the actual underlying algorithms and will work better than BO in some cases and worse in others.
However, the difference isn’t nearly as pronounced as moving from Random Search to BO.
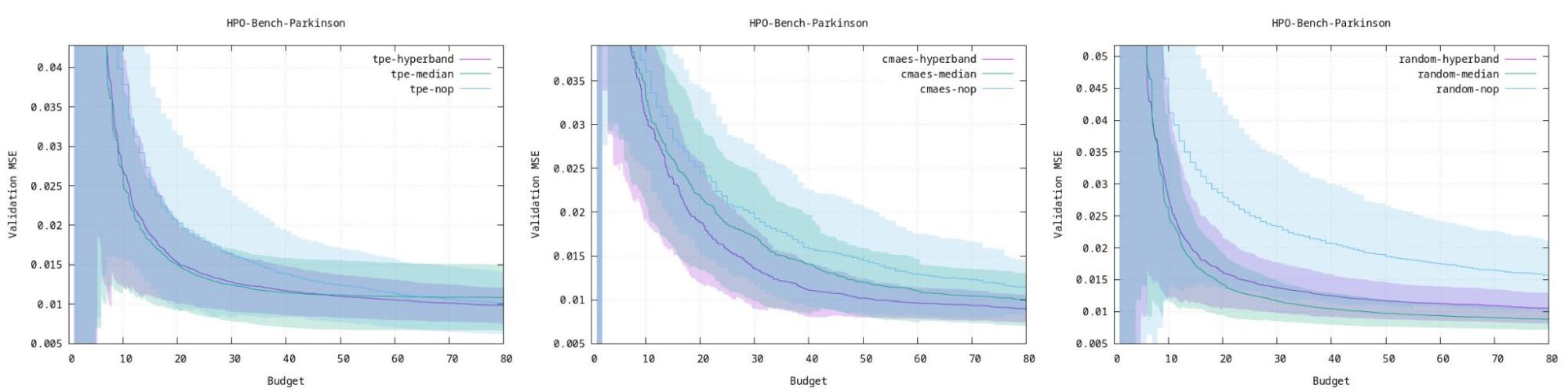
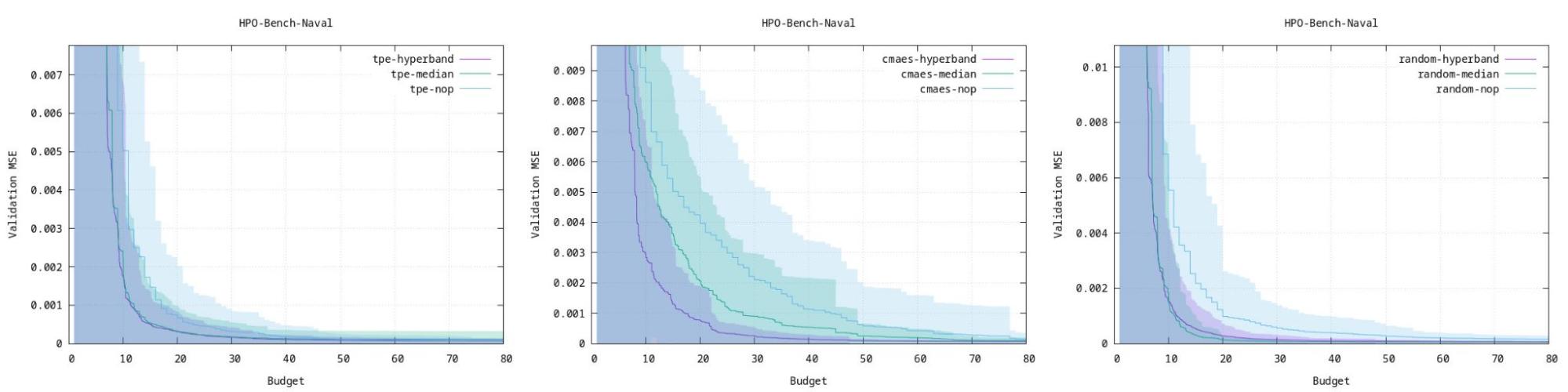
Optuna have a very nice page where they compare 3 algorithms with benchmarks on several different types of ml workloads. One can use those graphs to guesstimate what model might work best for your application.
Early Stopping: Budgets Explained

In order not to waste time, a lot of optimizers are coupled with an early stopping mechanism. These mechanisms are designed to take a certain amount of “budget” and optimally allocate it to the most promising hyperparameter configurations. In other words: they’ll save you a lot of time.
A budget is some kind of metric, that when low will train your model fast but relatively inaccurately and when high will take a long time to train, but the model performance will be better.
Examples are always easier, possible budgets include:
- Time
- Iterations (Hardware invariant as opposed to time, and ignores setup time)
- Amount of training samples
- Amount of features to use
- Number of cross validation folds
- Training image size
- …
So if our budget is e.g. amount of training samples, an optimizer can decide to train 100 hyperparameter configurations with a low budget (a subset of the training data, less training samples). This can speed up training significantly, but will yield poor results.
But if you choose your budget well, it will serve as an indication of how well the performance will be for the same combination of hyperparameters, given a higher budget (or, in our example, more training images)
Be careful when using time
It’s intuitive to use time as your budget: the more time spent training the model, the better it should perform, the hallmark of a good budget.
But time is relative, especially in the digital world. A faster machine will get much more training iterations in the same time than a slower machine, and differences in internet speed could lead to different setup times such as pip installs, even on the same machine.
So instead it makes sense to use the amount of model iterations instead, regardless of the time it takes to get these iterations. Only use time when you’re using the exact same environment for every candidate.
Choosing an Early Stopper: Use Hyperband
Successive Halving
Quite simply, this method kills half of the worst performing configurations every round. However, we still need to decide the amount of rounds ourselves. A hyperparameter again! So it’s usually a better bet to go for hyperband, because it is parameter-free!
Hyperband
Hyperband is based on successive halving, but runs multiple different versions of it each with a different amount of rounds, so it can figure out which one works best. This is why, when you use it, you’ll first encounter some “warmup” rounds. It’s optimizing the hyperparameter for the hyperparameter optimizer!
HPO settings in ClearML
ClearML employs a really cool concept for Hyperparameter Tuning. By abstracting the code into a black box “Task” and optimizing that instead of integrating e.g. optuna straight in your code, we can:
- Optimize ANYTHING without touching the code at all
- Easily switch out optimizer, early stopper or even the framework itself and rerun the task
- Easily scale to many machines
Check out our previous blogpost for more info.
Now that you know all of the above, the ClearML optimizer settings should make much more sense.
ClearML allows you to use 3 types of budget:
- Computation Time
- Number of job / tasks
- Iterations
You can configure clearml to use any of these by setting a value for their respective parameters. Just leave the others on None to ignore those budgets.
Compute time budget
As covered in the budget section, this is the most intuitive budget, but rarely the best one to choose. Instead, you should opt for either amount of iterations when training a deep learning network or any other iteration based model or a job-based budget if your models don’t work with iterations (such as SVMs or Random Forests).
You can set this budget by using the compute_time_limit setting.
But if you’re running HPO locally (on a single machine in an existing environment), it can still make sense to use it, because you’ll know exactly how long the whole process will take. (It will be a bit longer than the setting itself though, due to setup time and other small, non-compute based delays)
Job budget
A job budget simply takes the total amount of ClearML tasks as its budget. So hyperband knows it only has that amount of tasks to divide configurations into, no matter how long each task takes.
This is a good choice for any non-iteration based model.
You can set this budget by using the total_max_jobs setting.
Iteration budget
Iterations are captured automatically by ClearML, so whenever you’re training an iteration based model, it makes sense to use this budget.
You can set this budget by using the total_max_iterations setting.
You can also set the min_iteration_per_job to make sure every candidate has a chance to at least train for this amount of iterations before being eligible to be killed by the early stopper.
Finally, you can set any combination of these budgets and the first one to run out will determine the end of the hyperparameter optimization. In this case, it does make sense to use the time budget to make sure the process will be done before your deadline, but also allow hyperband to optimize for the amount of iterations to keep things uniform across machines.