Written by Victor Sonck, Developer Advocate at ClearML
ClearML is an open source MLOps platform, and we love the community that’s been growing around us over the last few years. In this post, we’ll give you an overview of the structure of the ClearML codebase so you know what to do when you want to contribute to our community.
Prefer to watch the video? Click below:
First things first. Let’s take a look at our GitHub page and corresponding repositories. Later on, we’ll cover the most important ones in detail.
The most important repository is of course the ClearML SDK. It contains everything that would run on your own machine, like the experiment manager, data versioning tool, automations, and much more.
Next, the SDK will have to talk to some kind of backend, that will store all our information, models, and data in order to visualize it somehow. The Clearml-server repository holds the code for that backend and the clearml-web repository contains the web UI.
The clearml-server is not to be confused with clearml-serving. This is where our custom model serving engine lives, which you can use to turn any model into an API, complete with CLI deployments, autoscaling, and model monitoring. It’s our newest project, so go check it out!
Then there’s the clearml-agent repository. It holds all the code necessary to run your experiments on any remote machine. It also communicates with the backend server to pull the tasks it should be working on.
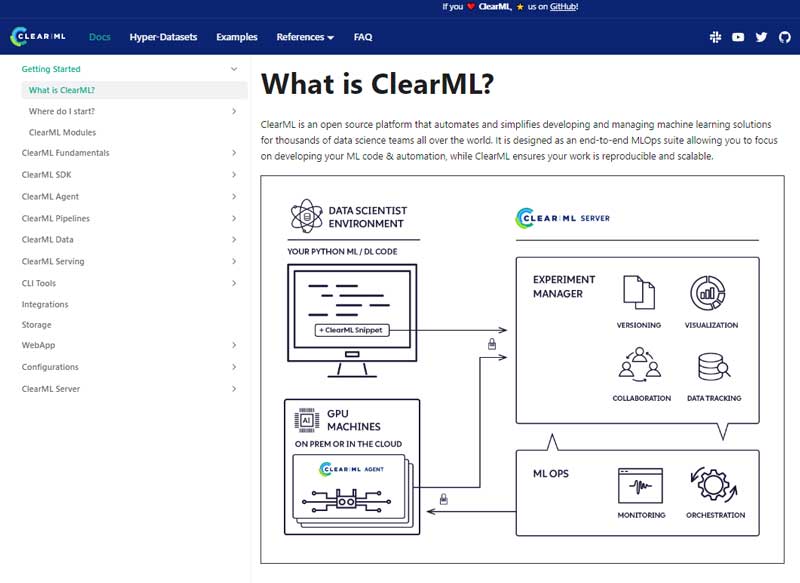
Finally, no good open-source tool can exist without good documentation. Our documentation site, hosted under clear.ml/docs, is built from this repository.
The rest of our repositories are more specialized, like the Helm Charts to run everything on Kubernetes, some examples of ClearML GitHub actions, or the clearml-blogs repository, where the example code from our blog posts lives.
How to Contribute
Ok, ok that was a lot. But how can you actually contribute to any of these repositories? Your best options to contribute are in the Documentation and in the SDK.
First of all, opening issues and PRs is the most straightforward way to contribute and the easiest way to start is with the documentation.
If you find a typo or some other mistake, you can easily edit the markdown file and open a PR. Or you created a simple test to check something? Add it as an example! A documentation PR always makes our day.
If something wasn’t quite clear, or could be explained in a better way, feel free to open an issue to discuss the problem with us! We’re always happy to brainstorm.
Second, you don’t even have to touch our repositories at all, to help out. Adding ClearML as a logger extension on other repositories is just as valuable.
Lots of machine learning projects like Huggingface, YOLOv5, or spaCy have built-in support for third-party experiment managers. Adding ClearML as an external logger is usually not very hard and is a nice exercise in both open-source contributing and ClearML usage. Feel free to add ClearML to your favorite machine learning repositories, as long as the maintainers are open to the idea, of course.

A third way to contribute is by working on the SDK, but that needs a little more explanation: ClearML SDK
First of all, you can help out by sharing your awesome examples. Let’s say you made a really cool pipeline or you have a specific way that you use clearml-data. Show it to the rest of the world by adding it to the examples folder!
Next to examples, you can write a binding. The experiment manager automatically integrates with a number of external libraries and to do that, each of those supported libraries has what’s called a binding.
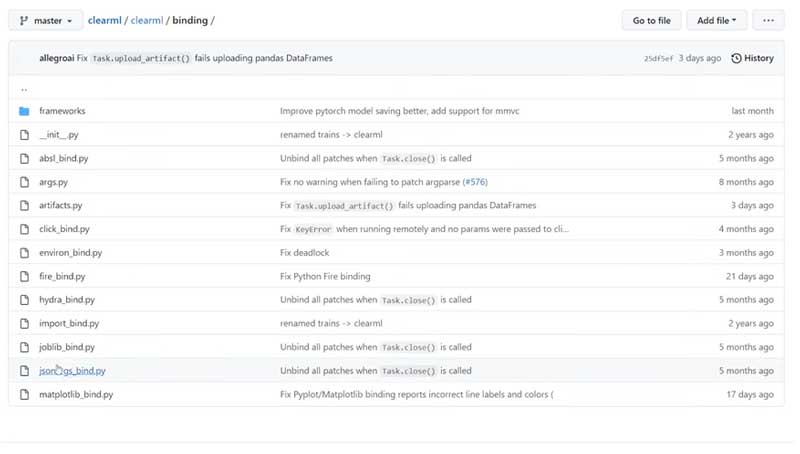
A binding essentially says: if this external library has been imported in the script of the user, replace its most interesting functions with our own version of that function. Each of those patched functions will call the original library function first and then add some ClearML login magic on top.
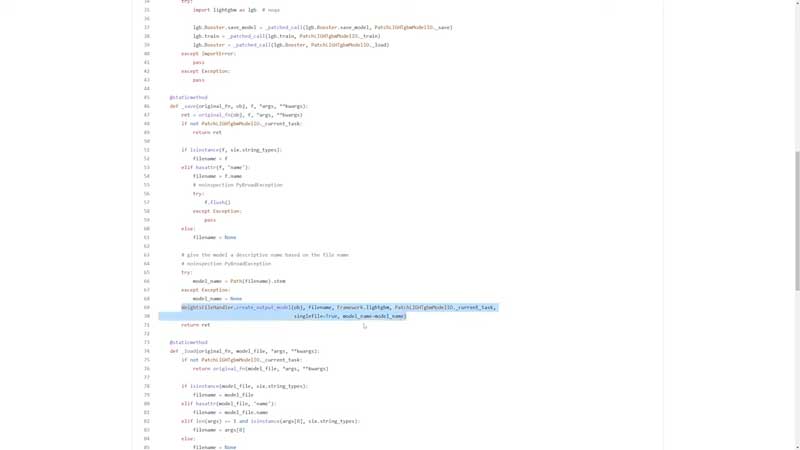
In this example, we will override the save function, call the original save first and then report it as a ClearMLl output model on the current task, before returning the output of the original function itself. That’s pretty cool, right? Give it a try by either extending an existing binding or creating a new one for your favorite library!
You can also add custom hyperparameter search algorithms for example or custom automations in the automations folder.
Finally, you can find the command line tools in the CLI folder if you think some arguments should be added or removed, or you can find clearml-data here if you want to add cool features like custom metadata tracking.
People use ClearML all over the world. We’re a small team, so it’s difficult for us to cover every use case and test every scenario. Thanks to community members like you, we can actually make a product that people want to use. So thank you so much for doing so!
Get Started
Get started with ClearML by using our free tier servers or by hosting your own. Read our documentation here. To learn more about ClearML, please visit: https://clear.ml.
If you need to scale your ML pipelines and data abstraction or need unmatched performance and control, please request a demo.