
Originally Published in PyTorch Medium by Omri Bar – Republished by author approval
TL;DR
-
- Theator improved their ML & Computer Vision powered surgical intelligence platform thanks to automation, implementing a full continuous integration (CI)/ delivery (CD)/ training (CT) pipeline, as well as creating a feedback loop to collect inference data to integrate with existing training datasets for improvement and continuous training (CT).
- PyTorch was chosen as the main ML/DL framework for both research exploration and production inference, and ClearML as the underlying MLOps solution for its effectiveness and robustness, which includes: experiment management, orchestration, dataops, as well as bonuses like optimizing physical data flow – all within a single control plane/dashboard for separate processes, pipelines, individuals, and more.
- For this workflow to work, the data management solution setup included: Versioning of datasets; Queryable datasets; Ability to mix and match datasets; Balancing datasets; Optimized data loading, and ClearML already consists of all such capabilities out-of-the-box, including deployment for ongoing move to production.
Performing surgery is largely about decision making. As Dr. Frank Spencer put it in 1978, “A skillfully performed operation is about 75% decision making and 25% dexterity”. Five decades later, and the surgical field is finally — albeit gradually — implementing advances in data science and AI to enhance surgeons’ ability to make the best decisions in the operating room. That’s where theator comes in: the company is re-imagining surgery with a Surgical Intelligence platform that leverages highly advanced AI, specifically machine learning and computer vision technology, to analyze every step, event, milestone, and critical junction of surgical procedures — significantly boosting surgeons’ overall performance.
The platform’s video-based analysis takes lengthy surgical operation videos and extracts meaningful information from them while maintaining patient privacy, providing surgeons with highlight reels of key moments in an operation, enhanced by annotations. This quantitative visualization of past surgeries not only enables surgeons to improve their craft from operation to operation, but it also informs surgical best practices for future procedures.
How did we make it possible? Automation was critical. As our R&D team expanded, we began to realize that we were spending too much time manually running model training and focusing on DevOps tasks, and not enough time dedicated to core product development. That’s when we realized that running all of these processes manually was infeasible and automating training pipelines was an absolute must. Now, when new data comes in, it’s immediately processed and fed directly into training pipelines — speeding up workflow, minimizing human error, and freeing up our research team for more important tasks.
Here are the ins and outs of our automation process.
From Software to Data Science Domain
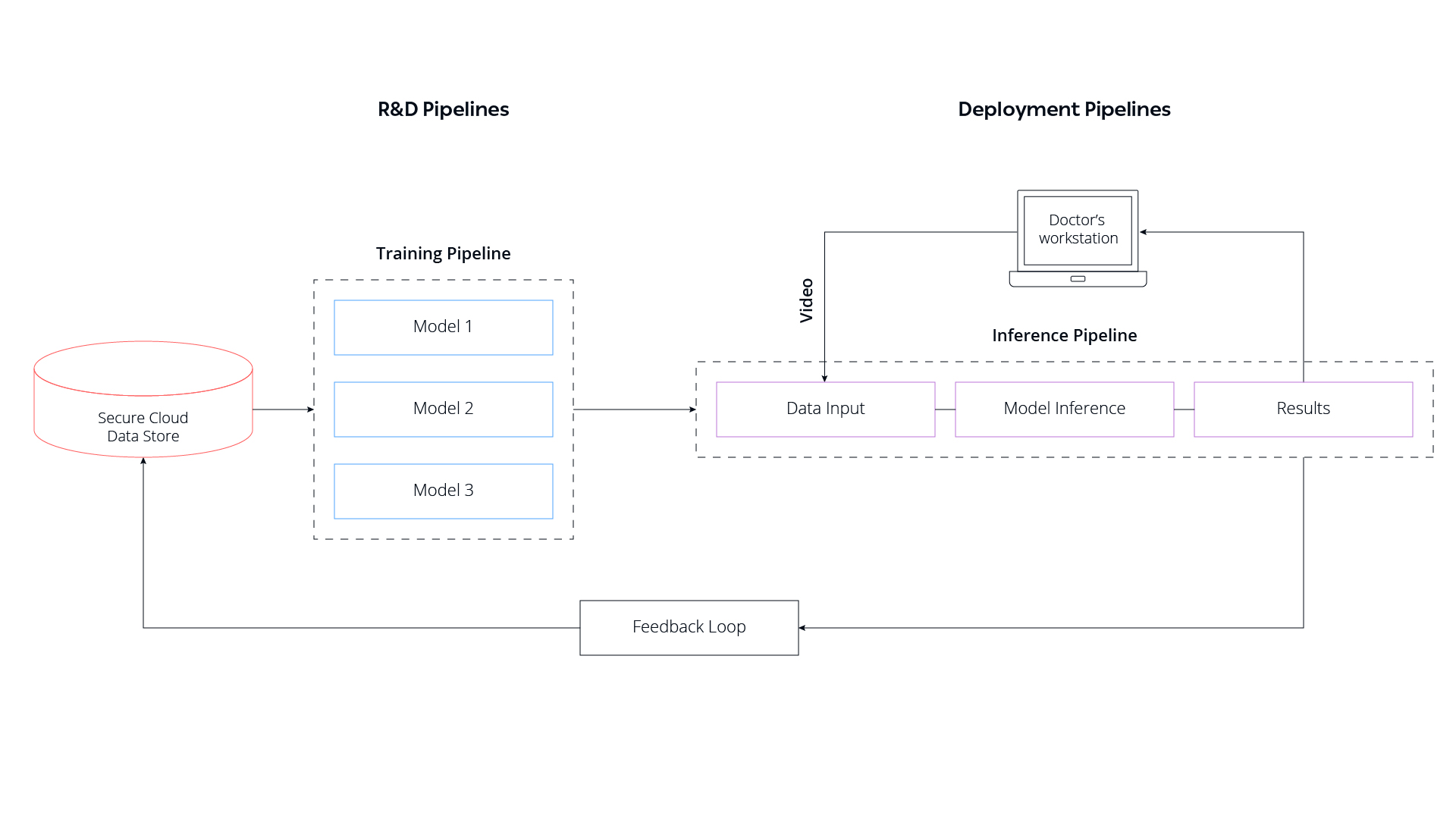
At theator, our strong engineering culture complements our core research principles and practices. In order to automate our training pipelines, we decided to borrow the “nightly build” concept from SW engineering, adapting it to the deep learning domain. The idea, in short, was to build a full continuous integration (CI)/ delivery (CD)/ training (CT) pipeline.
This automated pipeline trains and tests multiple models at night — as the name “nightly build” implies. It includes pipelines that generate several models chained together and manages multiple parallel pipelines that run concurrently with multiple procedure types. Experiments that pass the bar are placed in a deployment pipeline, which ultimately delivers the models to the end-users for inference.
Lastly, after annotation refinements, a feedback loop is created to collect inference data and integrate it with existing training datasets for improvement and continuous training (CT).
Building the automation was complex since there were multiple moving parts, all of which needed to be integrated together. We also faced challenges regarding ease and cost of computation, setup, maintenance, and more, and it became increasingly clear that minimizing these challenges meant choosing the optimal tools for the job. We mainly focused on selecting two core tools, i.e. the framework of choice, and the platform or toolchain on top of which our research and deployment pipeline automation was built, end to end.
We chose PyTorch as our main ML/DL framework for both research exploration and production inference. The models we typically develop at theator are a combination of state-of-the-art methods — tailored for the surgical domain — and modules developed in-house. Since our research team stays up-to-date regarding relevant computer vision publication releases, we frequently explore new techniques related to the field. Integrating new ideas with our proprietary modules — and exploring their impact — requires a flexible framework: one that enables fast experimental iterations of sub-components of the training flow, e.g., new network architecture or a novel layer structure. We identified PyTorch as the best framework to deliver the flexibility that we needed. With PyTorch we can easily disassemble and reassemble the parts we want to focus on and it provides frictionless top to bottom debugging capabilities — from the data loading parts through their tensor representations, down to the network’s gradients during the learning process.
We chose ClearML for the underlying platform or toolchain. The key selling point for us was the fact that ClearML provides most of the critical pieces needed in a highly integrated toolchain, including experiment management, data and metadata management, ML-Ops, orchestration, and automation components. It also has additional bonuses like optimizing the physical data flow for training and more.
The Control Plane
Because we manage multiple use cases — and new data coming in typically correlates with one or more of those use cases — training multiple models concurrently is inevitable. Doing so with separate models, however, also incurs high operational costs driven by extensive cycles and reduced researcher focus. Our researchers and engineers knew that they needed a single control plane to manage these multiple concurrent processes. To accomplish this effectively, we began using an advanced feature of ClearML that enables us to set up master controller apps which — among other things — manipulate multiple, complex pipelines concurrently. The feature can orchestrate an unlimited number of concurrent pipelines, spread across various datasets and machines, on-prem or in the cloud.
We set up our master controller to automatically run experiments, change configuration files with the correct data and model configuration, and then launch the experiment on remote machines. Our researchers complete a “recipe file” and the pipeline controller takes it from there.
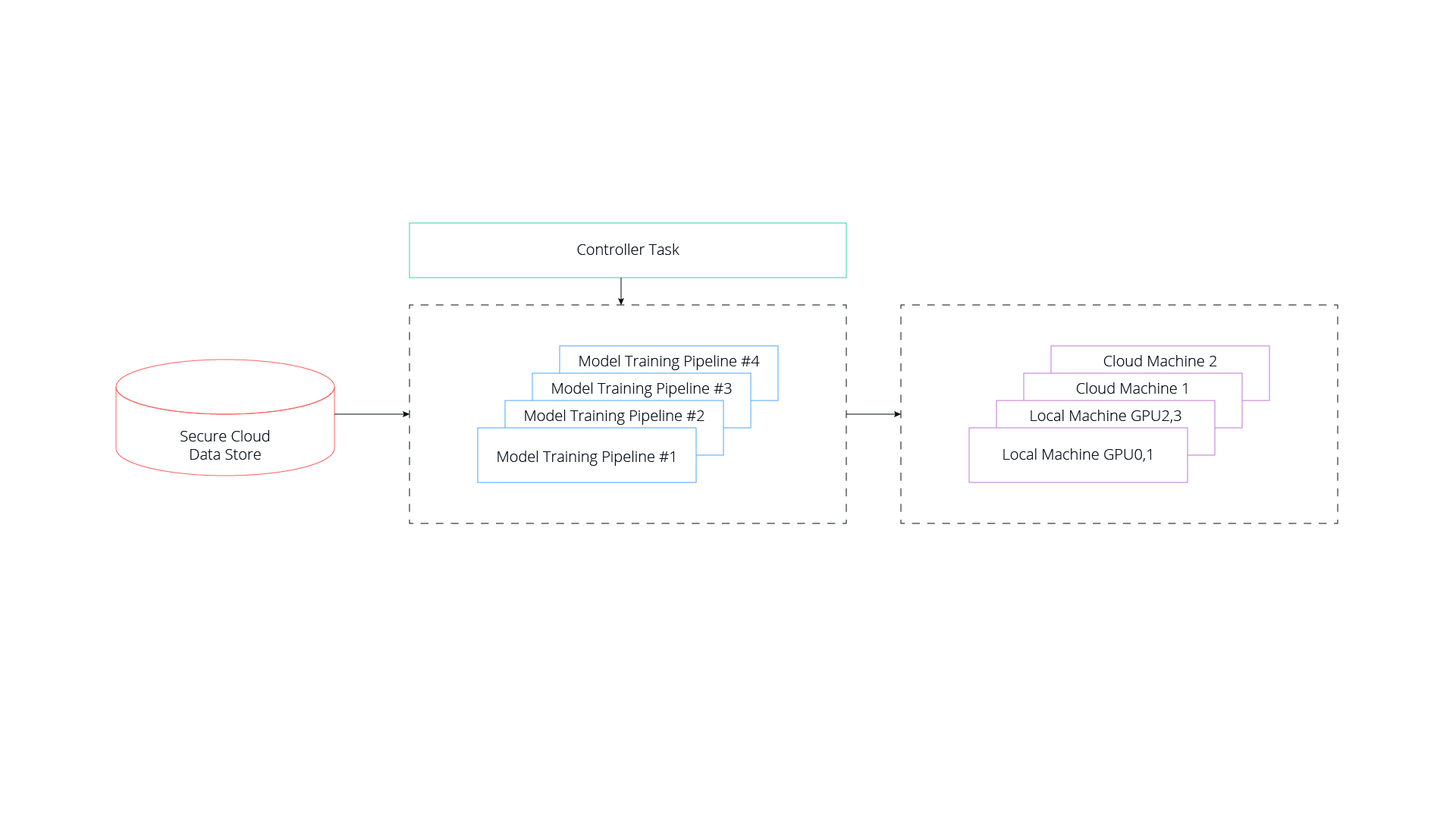
The Workflow in a Nutshell
Let’s dive a bit into our R&D pipeline and explore the setup.
The first step was to create a version of the data from the various video sources: these build upon the original training video sets and other videos, coming in periodically from active medical centers in deployment, that are annotated and added to the training sets.
To accomplish this, we set up a data management solution which included:
- Versioning of datasets
- Queryable datasets
- Ability to mix and match datasets
- Balance datasets
- Optimized data loading
We chose ClearML because all of these capabilities are included out-of-the-box in their enterprise data management solution. Using their system, we’re able to organize our datasets in a queryable structure, monitor incoming data, and automatically trigger the training pipeline periodically — or when events such as when data doubles, or we receive incoming data from a new source. This is the CI aspect of our solution.
A particularly helpful feature of ClearML is that it also tracks the machines’ status for utilization and models’ status for performance. Live tracking of model performance provides our researchers with quick insights that can shorten training times or lead to new research avenues. At the same time, machine observability enables them to maximize the utilization of our hardware. Correlating between an experiment’s behavior and machine utilization provides another debugging capability layer — therefore, combining these two features multiplies their impact.
On the data handling side, during training and inference, a surgical video that took hours to complete is represented as a huge 4D tensor. This makes it difficult to digest and process sequentially, out of the box. We’ve written customized data loading functionalities — based on PyTorch video handling modules — to develop our internal surgical vision models. Wrapping them with PyTorch data distribution and data parallelism has helped us achieve significant and essential acceleration in training and running experiments.
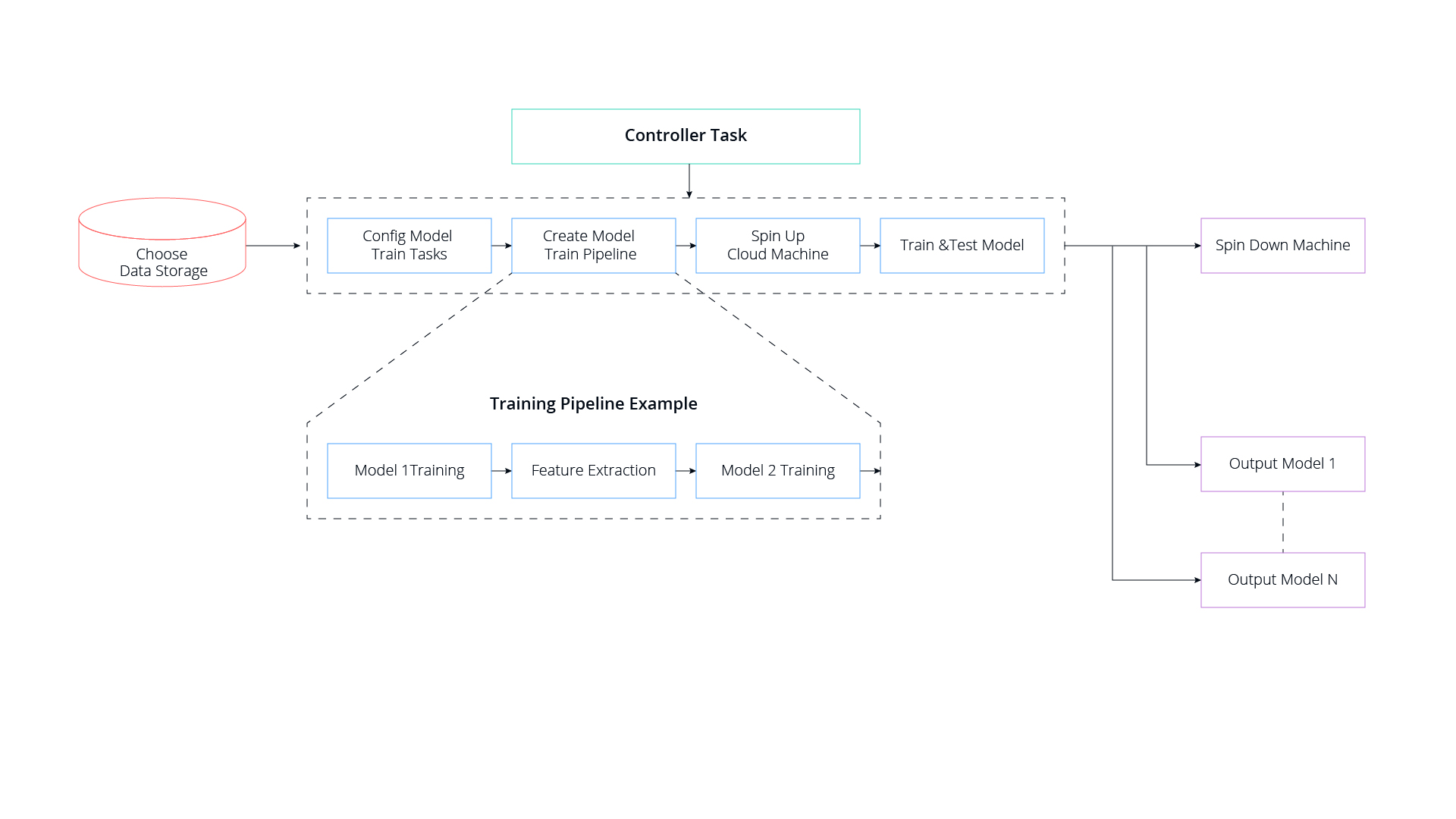
When it’s Time to Deploy
Having already covered the heavy load of automating the training of deployment-ready models, let’s now discuss the deployment aspect of our solution.
Since we run a live production platform (which has a continual feedback loop that enables retraining) we had to close the loop between creating and refining training models, and quickly deploy them — sometimes deploying multiple models at once. This problem is further complicated by the fact that pipelines may contain multiple models, and swapping models for better-performing alternatives might actually diminish the entire pipeline’s performance.
To mitigate this risk, we built a regression test pipeline that simulates production-like environments and tests the model on real field-data. This step, combined with ClaerML comparison dashboard, allows us to be confident in our pipeline and grants a “seal of approval” for models to be deployed into production. Finally, deploying models as part of the production base-code is quickly achieved with PyTorch, which enables robust and stable production-ready APIs that translates into fast surgical video analysis of new procedures curated from the operating room at inference time. This is the CD part of the solution.
Wrapping it all up
Having built this framework to automate and manage our entire process, from model development to deployment to continuous training for model improvement, we’ve evolved from a company that relied on traditional ML practices to a fully automated, scalable organization. Along the way, we’ve saved our researchers and engineers countless hours by allowing them to focus on where the true value-add lies. With this reduction in training time and costs, we’re now able to double down on our ultimate goal of perfecting and delivering better models for our end users.