
Authored by Raviv Pavel, CTO and Co-founder @ Neural Guard – published by author approval
TL;DR
-
- Neural Guard’s successful methodology and process to build datasets for DL models that optimize ROI and Time-To-Market to significantly increase competitiveness
-
- How ClearML Hyper-Datasets provided all the functionality required in a single MLOps solution to build specialized pipelines on top and connect to the rest of the research and production environments
-
- Step-by-step of the methodology, process, and implementation
A Methodology for Optimizing Dataset ROI & Maximizing TTM in Applied AI
Building machine learning (ML) and deep learning (DL) models requires plenty of data as a training-set and a test-set where the model is tested against and evaluated. Best practices related to the setup of train-sets and test-sets have evolved in academic circles; however, within the context of applied data science, organizations must consider a very different set of requirements and goals. Ultimately, any model a company builds aims to address a business problem, and in this context there are two overarching goals: build with the highest return-on-investment (ROI) and at the fastest time-to-market (TTM). Both have significant financial implications – especially TTM, which, beyond reducing direct costs, allows them to get to market faster than competitors and gain tactical and strategic financial advantages as a result.
Neural Guard produces automated threat detection solutions powered by AI for the security screening market. We detect specific, high-risk items in CT and X-Ray imagery by leveraging neural networks to analyze a security scanner’s output. In this blog post, we discuss the methodology we have developed for building datasets for DL models that optimize ROI and TTM, which enabled us to significantly increase our competitiveness within this market.
As any data scientist knows, to validate a model one needs to set aside its testing data. It’s also a no-brainer that the test data cannot be part of the training dataset itself
The standard practice in academic research is to first create a train-set, then set aside a small part for a test-set. Ultimately in academic research, algorithm and model performance are tested against well-known, accepted datasets, so that comparisons can be made. In these situations, the dataset is immutable and cannot be changed. For this goal, the methodology makes sense.
As a result, researchers and data scientists put most of their focus on the quality of the model, with datasets – as immutables – getting less focus; and the test-set almost a given. Granted, you want to make sure the test-set is reflective of the train-set. Any subset is either randomly picked or sometimes picked with a more sophisticated methodology, but still random methodology for each label, always maintaining the distribution of labels. However, that’s about it.
Data Costs Money. A Lot of Money
As a rule of thumb, deep learning networks are data-hungry. When data scientists are asked “how much data do you need?” The correct answer, at least from the researcher’s side, is pretty much always: “more.” But this ignores a fundamental problem: In academic research, researchers rarely have to deal with the burden of creating the dataset themselves, be it for testing or training, usually because there is a known benchmark or as they need to work on a specific dataset. On the other hand, for research (and development) within the context of applied science in real-world industry applications, we are indeed burdened by the difficulties and complexities related to creating the dataset.
Getting more data requires more time and money, and maintaining it isn’t cheap either. For example, at Neural Guard we currently use some two million images. While in the automotive industry this is not considered significant, in the security market it absolutely is. Creating such datasets requires expensive x-ray machines, real threats (e.g. guns, knives, explosives, etc.), a large variety of luggage items, and highly trained data annotators.
The cost of obtaining and maintaining a dataset are non-negligible:
- Collecting data in and of itself may be costly if you do not already have broad operational implementation of your solution. Sensors (cameras or others) are needed to capture data, with storage and networking to move the data from collection site(s) to training locations.
- Labelers are required to tag it, and sometimes you may need highly skilled laborers such as doctors or engineers; in our case, x-ray machine operators were required.
- We need data collection personnel and data engineers to amalgamate, sort the data, and make it accessible to data scientists in relevant storage and formats.
- More data means higher storage costs and more compute time for training the model, which directly translates into dollar cost when it’s a cloud instance running the code or if the additional load necessitates purchasing more on-prem compute resources, which are costly and also need to managed and maintained.
- Datasets maintenance (beyond storage, etc.) is also costly. Datasets often need to be modified, labels may need fixing, and every so often we discover that how we labeled classes may not have been optimal and relabeling a whole class is needed (e.g., we grouped folded and open knives together, but then discovered the model performs better when we separate the two into different classes). The larger the dataset, the higher relabeling and fixing costs. And because data science requires reproducibility, we need versioning. The larger the dataset, the greater the costs associated with keeping older versions.
Thus, we can posit that for an applied science problem, an organization’s goal would be to get the “best results” (essentially the best performing model possible), with the least amount of data. In fact, we actually want to get the best performance for the least amount of investment, in data and all its related processes, as well as other costs, including time.
Of course, defining “best performance” is shooting at an evasive target. In academic research, we want to beat SOTA results, and every 0.1% improvement in accuracy is actually impressive (Granted, there are academic papers concerning themselves with optimization of costs or ROI for given models, but they are not relevant for the hypothesis of this post for various reasons). Yet research in a commercial context is different. There are business trade-offs to be made and model performance improvements sometimes come at a cost (higher inference latency, longer research time, etc.). We need to have an understanding of the business objective to define proper success metrics. Let’s state even more accurately that often-times, our target is to reach a certain performance threshold (not necessarily the best attainable performance) for said budget.
Why should the test-set come before the train-set?
In the context of deep learning-based solutions, the business metrics and performance indicators defining our business goals are reflected in our test-set while model performance on the test-set determines whether our model is “ready”. We first check our model against the test-set, and if we get results that meet our KPIs , we are good to go! The test-set becomes the “single point of truth”, making building a test-set one of the most important aspects of applied research and development.
Based on all of the above, I would like to make the case that for industry model training, we should not follow the methodology of creating a data-set, and then reserving some percent of it aside as a test-set. Rather, our first priority is to define and build the best test-set we can. In fact, the quality of the test-set is one of the most critical variables that ultimately impact the quality of the end model performance. If the test-set accurately reflects the real-world scenario (i.e.,. it is of “high quality”) then a model performing well on it will ultimately be a model performing to our expectations in production. This is where domain knowledge and experience becomes invaluable, as it takes the process of test-set building from simple subset allocation, to a set of rules and procedures.
Here are some key aspects to consider when addressing the notion of “high quality”:
- The number of test image, per-class, needs to be large enough to be statistically viable
- The dataset should be well balanced and fully represent the domain. These are some of the properties we track and balance:
- Class
- Class instance
- Complexity of the object’s placement and angle.
- Background (luggage) type
- Background complexity
- Scanner model
Expanding our dataset to train-set & training
Only once we have the test-set ready, can we move to the next stage: creating the train-set. The need to build our own datasets also means we can design the test-set to fit our deployment environment and be able to replicate the test-set’s mix for the train-set. Once we have built a test-set, we’ll just go and build a train-set by essentially manufacturing “clones” of the test-set: the same label and background distribution, the same background objects and object postures, but different images and preferably different object and background instances. At Neural Guard, we have an in-house data production facility, where we produce new images at a rate of some 130K new labeled images per month.
When we reach a ratio of 1:1 of test-set vs. train-set, we can do our first pass of “train and evaluate” (We start at the 1:1 ratio because it does not make sense to have a train-set smaller than the test-set). If the model’s performance during evaluation meets the requirements, we can stop here. When it doesn’t – and it usually doesn’t – we need to extend our train-set and test with ever growing ratios. We start with a ratio of 2:1 trains:test dataset, and so on, and continue until we meet the required threshold. From our experience, the ratio usually ends up at 4:1 to 5:1. Ideally, the train-set should not be expanded uniformly, but rather based on each ;9ass; the per-class ratio depends on how difficult the class is. In our domain, objects that blend with their background are harder to train.
See example below of a knife, and the same knife in a bag with metal objects:
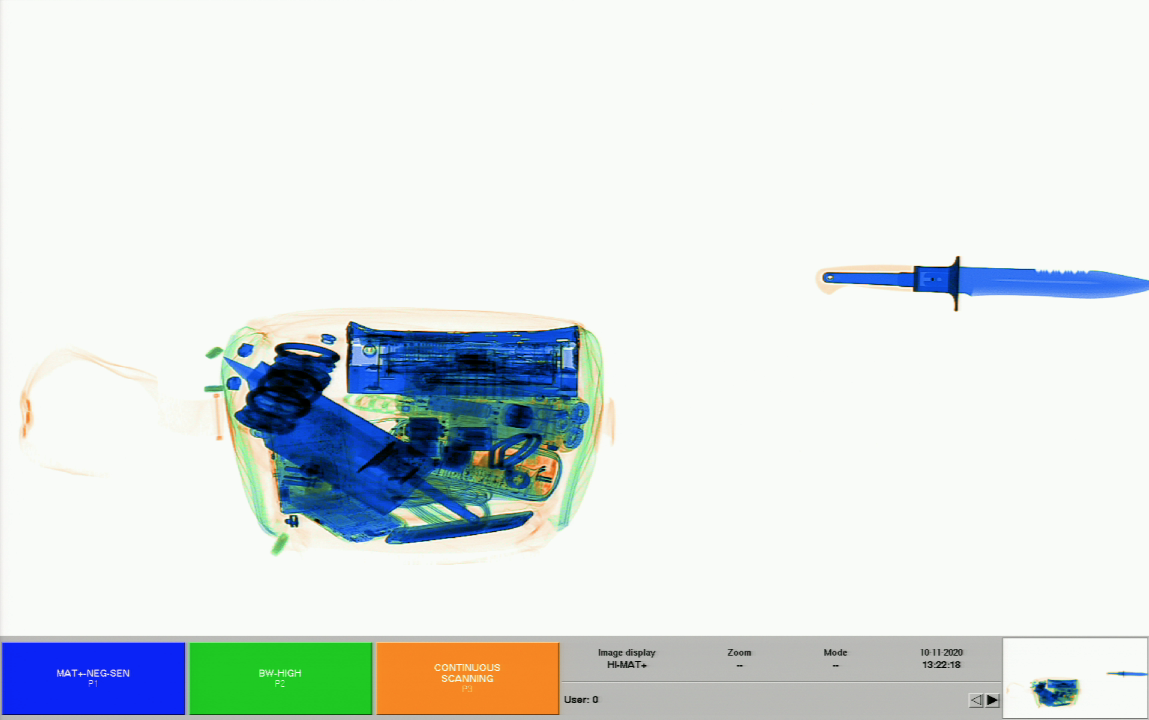
Following this methodology, we can generate only as much data as we need, allowing us to minimize data-related costs: manufacturing and labeling data, data storage and archiving costs, maintenance, etc. Ultimately keeping the dataset size smaller allows us to get the fastest TTM while also keeping costs down. In the methodology detailed above, we can do this without compromising on performance.
From theory to practice
This is all great in theory, but how does one tackle the task of actually building such a test-set? We came to the conclusion that getting intimate with the data – while being able to manage it – is the key to being able to build a proper test-set. Ideally, we need to be able to:
- Easily get label distribution and other statistics for each dataset
- Version datasets so we can track progression
- Have fine-grained control of which subsets of our dataset are used for any training run and for the test-set.
- Connect the dataset management tool to the experiment management tool to tie results, data and metadata together
- Change data on-the-fly during longer experiments, and feed new data mid-training
- Have easy APIs for dataset rebalancing and conforming. This helps with building balanced datasets and ensuring balance is maintained during training
Up to this point in our story, the key takeaway is to know your data, build a good test-set, and the rest will fall in place. But getting to know your data is a difficult task. First, getting as much field data as possible is invaluable. It really helps a researcher understand the different objects, positions, backgrounds, and so on that a model will have to deal with. Once you have field knowledge, you can also create synthetic data on your own (At Neural Guard we have our own data-generation facility with a variety of x-ray machines and access to a large collection of threat items. There are different types of synthetic data we create, but that is beyond the scope of this blog post). This helps with the logistics of data gathering and gives us control over data produced, so we know we are covering all of the edge cases.
Tooling is also of great importance. It is possible to write a lot of code and stitch-scripts to try to build all of the abovementioned functionality. However, once your work scales – and we’d argue that even before scale happens – it becomes impossible to handle.
For us, it did not make sense to build such tools on our own. We wanted to stay laser-focused on building the best auto-detection solutions for the security screening market. All the functionalities listed above are what a best-of-breed MLOps solution should deliver in our opinion. However, most often, the functionalities are only to be found in several individual solutions that need to be integrated together.
This is why we chose ClearML Enterprise as the toolchain of choice for us. It provides all of the functionality in a single, highly-integrated toolchain. It is also very easy to build specialized pipelines on top of, and to connect it to the rest of your research or production environment. Moreover, what was invaluable for our work was the ability to modify and add data on-the-fly within ClearML. In ClearML, data management is highly integrated to experiment management, so once a data collection engineer uploads a new dataset version, we are able to immediately track results and see its effect in real-time. As one simple example, it enables us to discover mislabeling issues and verify the fix very quickly.
You can read more about why and how we use ClearML (f.k.a. Allegro Trains) in this blog post.
The bottom line
In this blog post, we explored a data creation method that is the opposite of traditional methods – building your test-set first, then deriving the train-set from it. We explain why for companies doing deep learning, it is a great method to deal with the data acquisition costs. This methodology of focusing on the test-set first also helps data science organizations get a more intimate understanding of the nature of their data “in the wild.” This leads to the creation of higher-quality datasets (both train-set and test-set) that ultimately lead to higher performing models at lower costs, which is the end target of any such undertaking.
It is also important to note that, while doable, managing the entire data lifecycle on your own brings a new layer of significant complexity and one should seriously consider purpose-built tool(s) for the task.