Written by Kim Ann King, Head of Content Strategy at ClearML.

We recently had a chance to catch up with Heather Grebe, Senior Data Scientist at Daupler, which offers Daupler RMS, a 311 response management system, used by more than 200 cities and service organizations across North America and internationally. This platform helps utilities, public works, and other service organizations coordinate and document response efforts while reducing workload and collecting insights into response operations. With Daupler’s technology, organizations improve their response capabilities and strengthen their customers’ confidence. The company’s goal is to make it easier for clients to focus on their core mission of providing critical services to their customers and communities.
Heather explains the platform handles “both standard and operation-critical 311 service requests that require city or utility response, such as water main breaks, sewer back-ups, traffic signal outages, or general infrastructure damage.”
The foundation underlying Daupler RMS is Daupler AI, which can gather and analyze various modes of data relevance, in sequence, based on the last piece of data obtained for a request, apply defined rules configured at the customer level, and initiate and monitor the correct response protocols and resulting data. To do that, Daupler AI receives inputs from multiple sources, such as customer calls, texts, geotags, photos, emails, web forms, and social posts as well as first responder reports and infrastructure alarms. The system analyzes the data using Daupler’s proprietary algorithm, which has been trained on data from a pool of millions of request records across many utilities and other service organizations. It then categorizes the data into individual incidents or larger events and routes the information to the appropriate department.
All of that data collection is handled by a machine learning system as part of Heather’s realm, where she works with Data Engineer, Carly Matson, to organize millions of data samples, effectively label the most advantageous subset of requests, manage 15 ML models (and growing), and integrate feedback from human-in-the-loop system components. With such a broad remit and lean staff, how does she manage the huge volume of work? The simple answer is automation with ClearML. Heather explains: “It is simply not efficient or effective to spend our limited time manually hacking away at repetitive tasks or writing boilerplate code. That’s why I am very interested in automating anything and everything that can be automated, with the proper monitoring.”
To help do that, Heather is using ClearML Data to create, manage, and version the datasets, ClearML Pipelines to streamline and connect multiple processes, ClearML Orchestrate to handle all our workers, queues, and job scheduling, and ClearML AutoScaler to spin up machines when demand is high (and then spin them back down to reduce costs when no tasks need to be executed).
“ClearML allows us to quickly search for optimal data to improve our models’ robustness, label it, get it through the training pipeline, perform detailed analysis with comparisons to our production state, and then stage deployment – all within a day or two.”
– Heather Grebe
Automating ML Processes at Daupler
Part of the system Heather works with is a hierarchical text classification system with many different components that work together conditionally. Here’s what she had to say about how the automated ML process works:
“Let’s say we identify a new concept that needs to be captured in order to serve our customers’ diverse needs and we want to build a new model to attempt to extract it from free text that a citizen provides. I’ll start by doing some initial sampling and labeling to get a rough MVP concept training dataset in place. Then, once the data has hit the database, it’s as simple as a single CLI command to trigger a ClearML pipeline that handles automatic ingestion, analysis, and processing of that new data, ending in an update of our versioned ClearML data set that is then available to any other consuming process.
Once that’s updated, it can either automatically trigger training with the current or default hyperparameters or we can actually pull it out and work on it manually through a configuration file to change different parameters – it’s all tied in through GitLab CI/CD and the ClearML UI. So we make a change to the configuration file and push the configuration file up through a merge request, then the whole training pipeline will kick off all the way through the evaluation and we’ll get a message in our GitLab commit history that says ‘Hey, here’s a link to your newest model and go in and review it.’ If we decide we want to go with it, we can publish it, update a UUID reference in a deployment config, and then push it up through a reviewed merge request to run deployment through GitLab.
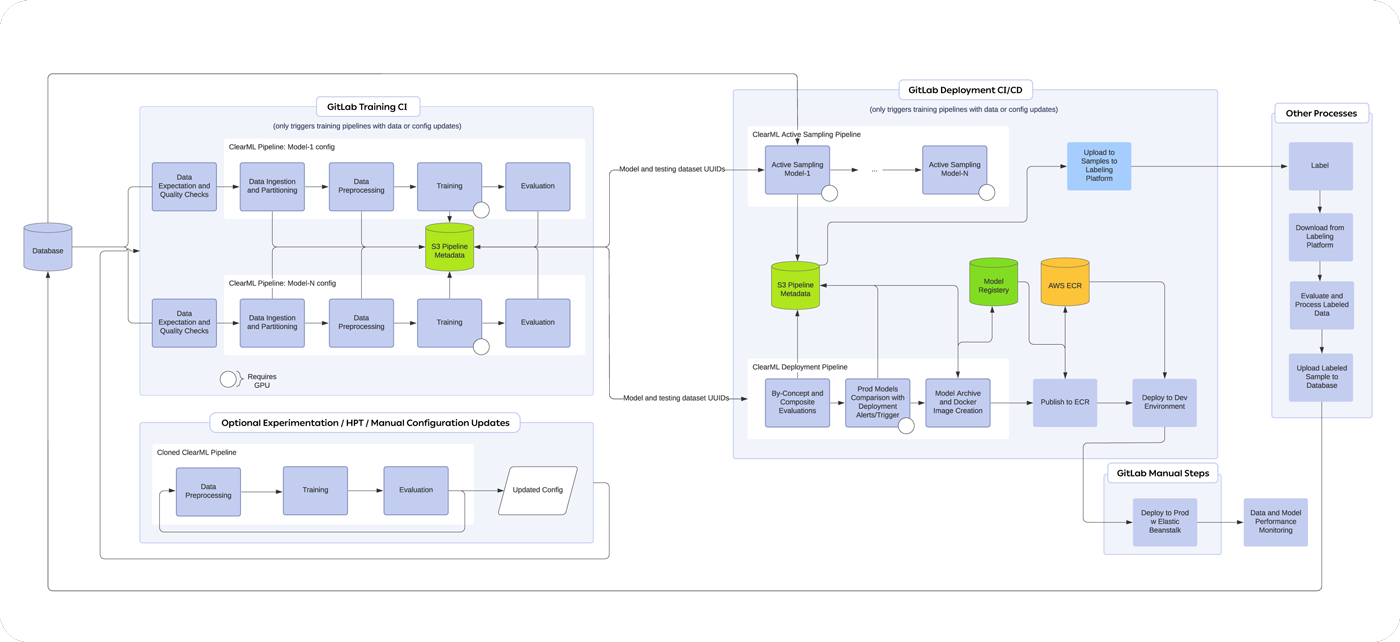
We have a robust testing suite that runs in that deployment pipeline to make sure everything is going to have the impact we’re expecting, both from a code perspective and from an inference perspective.
Another ClearML feature we use quite heavily is the Hyperparameter Optimization application, which has an incredibly simple UI. To do that, we just take the training step from our pipeline with a simple UUID reference, and specify the method, parameter bounds, run time/iteration bounds, and run-queue and kick it off. We can just pull it out of the pipeline directly and entirely, which I love and run that training step with the queues dedicated to HPT. It doesn’t get in the way with any of our other work because I can always manually click and drag jobs in the queue if something has come up that needs to be prioritized before the HPT is complete. In other words, ClearML’s queue system enables me to reprioritize tasks and put some manual work before the automatic work to get results out faster. It’s very convenient for balancing operation critical work with experimentation and HPT.
Training orchestration is done via the ClearML Autoscaler, so training instances are only up when needed and scaled down when there’s nothing to do. The second part of the process, deployment to production environments, is mostly automated and does not usually need any manual wrangling unless alerts are triggered. As long as tests show the model is stable and improving, and our monitoring is silent, everything is fully automatic up until the final push to prod.
In terms of monitoring, we’re using ClearML system monitoring for the training phases and Grafana for the bulk of our inference system insights. As for the trigger for deployments, it’s written to have a lot of conditional comparisons with different metrics. You can almost think about it like a multi-point decision system that evaluates the model currently in production and the new model on the same testing dataset to determine whether we are seeing the improvements we are looking for without losses to performance in other areas.”
Timelines
“If we’re building a new concept model, I would say it takes about two weeks to get an MVP to iterate off the ground – between initial data gathering and ontology development, labeling, and then pushing it through the data/training/evaluation pipelines. As far as refreshing the models that are currently in production, it takes about a day; it’s just a matter of loading or labeling that active sample, pushing it up, and that’s about it,” she said.
The Bottom Line
“Using ClearML gives me 99% of what I need, is easy to manage, and once it’s set up, we’re all set,” Heather concluded.
If you’d like to get started with ClearML’s unified, end-to-end, frictionless MLOps platform, get the Open Source version on GitHub. If you need to scale your ML pipelines and data abstraction or need unmatched performance and control, please request a demo.