☁️ Now Also as a Cloud Service!
We recently rolled out our very own GPU autoscaler in Collaboration with Genesis Cloud and it has been quite a success. Also recently, YOLOv8 by Ultralytics was unveiled, the new king of object detection, segmentation and classification. In this blogpost we’ll see that you can train a computer vision model using the ClearML/Genesis Cloud autoscaler at a fraction of the cost of competing cloud services like AWS or GCP. And it even runs 100% off of green energy! 😎
🎮 Cloud Consumer GPUs for Deep Learning
Consumer GPUs, like the well-known NVIDIA RTX 3090, have a huge amount of VRAM and even in terms of raw speed, they’re no slouches either. So the main question of this blogpost is: how do these consumer GPUs stack up against real datacenter cards like the T4 and A10G for deep learning workloads? (Spoiler alert: they are seriously strong contenders!)
ClearML has partnered with Genesis Cloud to provide you easy access to these consumer cards, right from within ClearML. Of course, as you can see, you can just as easily spin machines on AWS and GCP as well, so this is an excellent ground to start comparing machines on!
Genesis Cloud is a European cloud infrastructure provider committed to providing 100% green computational power with a high performance-to-cost ratio. Through the ClearML app, you get access to 3 types of consumer GPUs: NVIDIA® GeForce™ RTX 3060Ti, 3080, and 3090 in different configurations (multi-GPU, Optimized Memory & CPU, etc.)

💰 Cost Efficiency of Datacenter vs Consumer GPUs
As you probably expected, the cost difference between datacenter GPUs and off-the-shelf consumer GPUs can be quite big. Naturally, very high-end datacenter cards like the A100 can handle orders of magnitude large models and datasets than the best off-the-shelf GPUs, but the reality is that most people aren’t training gigantic LLMs from scratch.
So in order to properly compare both types of GPUs, we selected a “normal” workload in YOLOv8 (read more below) and chose the most popular and economical AWS GPU machines to compare against. Below are the prices of both types of machines at the time of writing this blogpost (March 23, 2023).
| Machine Type | ClearML Price (backed by Genesis Cloud) |
| RTX 3060Ti | 0.20 |
| RTX 3080 | 0.30 |
| RTX 3090 | 0.42 |
| RTX 3080 (Mem & CPU Optimized)* | 0.36 |
| RTX 3090 (Mem & CPU Optimized) | 0.504 |
| AWS Machine Type | GPU | AWS Hourly Price (US East N. Virginia**) |
| p3.2xlarge | V100 | 3.06 |
| g4dn.xlarge | T4 | 0.526 |
| g4dn.2xlarge | T4 | 0.752 |
| g4dn.4xlarge | T4 | 1.204 |
| g4dn.8xlarge | T4 | 2.176 |
| g5.xlarge | A10G | 1.006 |
| g5.2xlarge | A10G | 1.212 |
* Most cost-efficient configuration out of all machines. Read more below!
**We took care to choose the cheapest AWS region to give AWS machines the best fighting chance.
Results TL;DR:
| Machine Type | Dollars / Epoch (Cost Efficiency) |
| ClearML RTX 3060Ti | 0.0102 |
| ClearML RTX 3080 | 0.0106 |
| ClearML RTX 3090 | 0.0128 |
| ClearML RTX 3080 (Mem & CPU Optimized) | 0.0096 |
| ClearML RTX 3090 (Mem & CPU Optimized) | 0.0098 |
| AWS p3.2xlarge | 0.0881 |
| AWS g4dn.xlarge | 0.0174 |
| AWS g4dn.2xlarge | 0.0213 |
| AWS g4dn.4xlarge | 0.0330 |
| AWS g4dn.8xlarge | 0.0588 |
| AWS g5.xlarge | 0.0235 |
| AWS g5.2xlarge | 0.0208 |
Every Price is On-Demand
Because benchmarking always involves an unlimited amount of possibilities, we cannot cover all of them. For this blogpost, we’re looking at simply the on-demand prices of compute for both contenders. This means we are not taking any committed use discounts into account!
No Multi-GPU
We’re not looking at multi-GPU machines either. Again, this is to keep things simple. Besides, Genesis Cloud already has an excellent blogpost talking about exactly this! Go check it out and tell them we said hi. 😄
This is also the reason we won’t include the A100 in this benchmark as it’s impossible to get a machine with a single A100 GPU on AWS at the moment.
A Note About Spot Instances
Spot instances are a different beast altogether, one with very clear trade-offs.
- When you opt for a spot instance you know the machine can be terminated at any moment. This means you have to be careful with the kinds of tasks you run on them, and make sure their progress is adequately saved at regular intervals. It might end up costing you more to train a model to completion if checkpoints are not set up correctly!
- Spots are also hard to find, especially in North America. If you want to use spots, search in the European regions! They are a little more expensive, but they are usually actually available. Bear in mind running your training on spots could mean no progress for days on end.
On the other hand, these machines are insanely cheap. When comparing normal, on-demand compute pricing of any cloud, including Genesis Cloud/ClearML, it is not even a competition, the spots are significantly cheaper.

So running on a spot is your call based on these considerations. If you do want to, we’ve got you covered too. 😄 Using the ClearML AWS Autoscaler, you can check this button to enable running on spot instances right from ClearML, it’s just as easy as running on normal AWS machines. This works for GCP spots as well, using the GCP autoscaler.
🚀 YOLOv8 as Benchmark Load
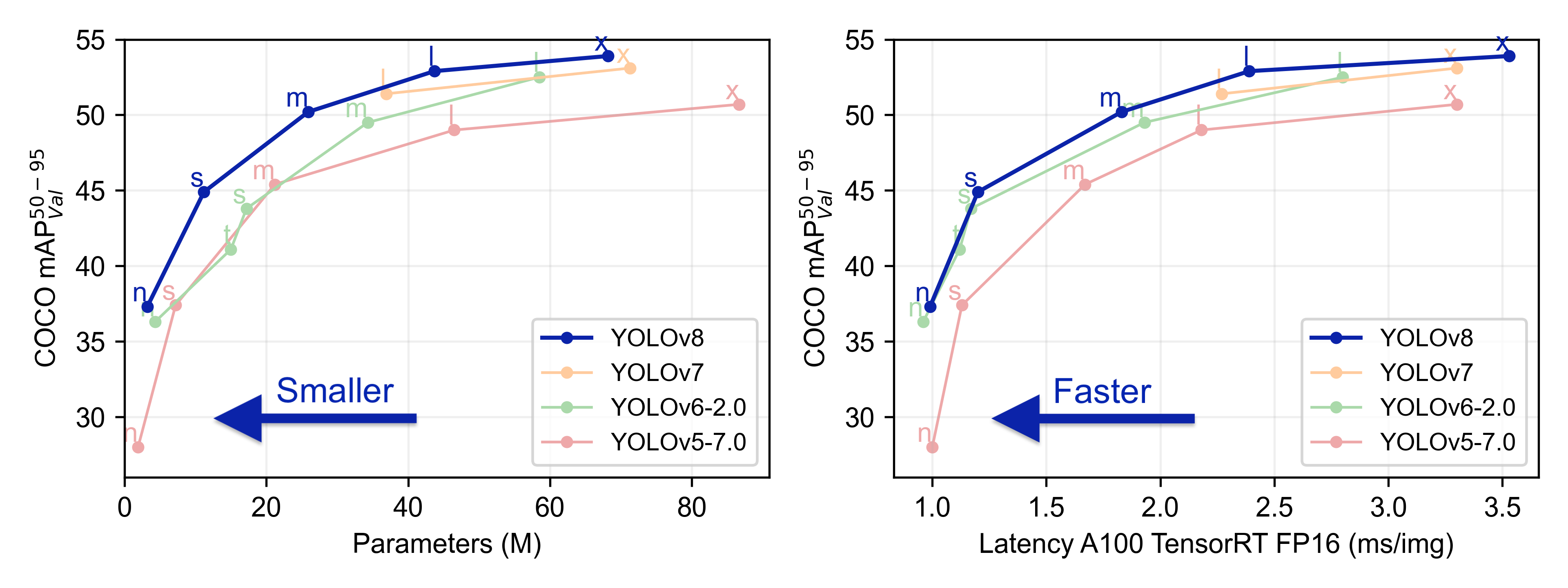
YOLOv8 comes from the same, excellent team behind YOLOv5: Ultralytics. YOLOv8 outperforms all of its competitors, but above all, it is meant to be easy to use and friendly. With a new overhaul of their API, you can now train object detection models, segmentation models and classification models with just a few lines of code or even a CLI command!
Running YOLOv8 with ClearML
YOLOv8 makes things very easy for us with its nice and clean SDK. ClearML is integrated natively in YOLOv8, but if we later want to be able to rerun our experiment on a different machine, using different parameters, we have to explicitly initialize ClearML before initializing YOLOv8.
from clearml import Task
from ultralytics import YOLO
# Explicitly call ClearML init before YOLOv8
task = Task.init(project_name="YOLOv8",
task_name="detection_training",
tags=['YOLOv8'],
auto_connect_frameworks={'pytorch': False, 'matplotlib': False})
# Set some basic settings to prepare for remote execution later
task.set_base_docker("nvidia/cuda:11.4.3-runtime-ubuntu20.04", "--ipc=host")
# Put all our YOLOv8 arguments in a dictionary and pass it to ClearML
# When later we change any parameter in the UI, it will be overridden here!
args = dict(data="VisDrone.yaml", epochs=10, imgsz=640, task='detect')
task.connect(args)
# Turn the chosen model into a parameter too, so we can change this later!
model_variant = "yolov8n"
task.set_parameter("model_variant", model_variant)
# Load the YOLOv8 model
model = YOLO(f"{model_variant}.pt") # load a pretrained model
# Train the model using our arguments from before
# If running remotely they may have been changed by ClearML
results = model.train(**args)
Running this script works like any other YOLOv8 training run, only now everything is tracked in the ClearML experiment manager. You can take a look at everything that is captured at app.clear.ml or on your own self-hosted server. The results should look something like this:
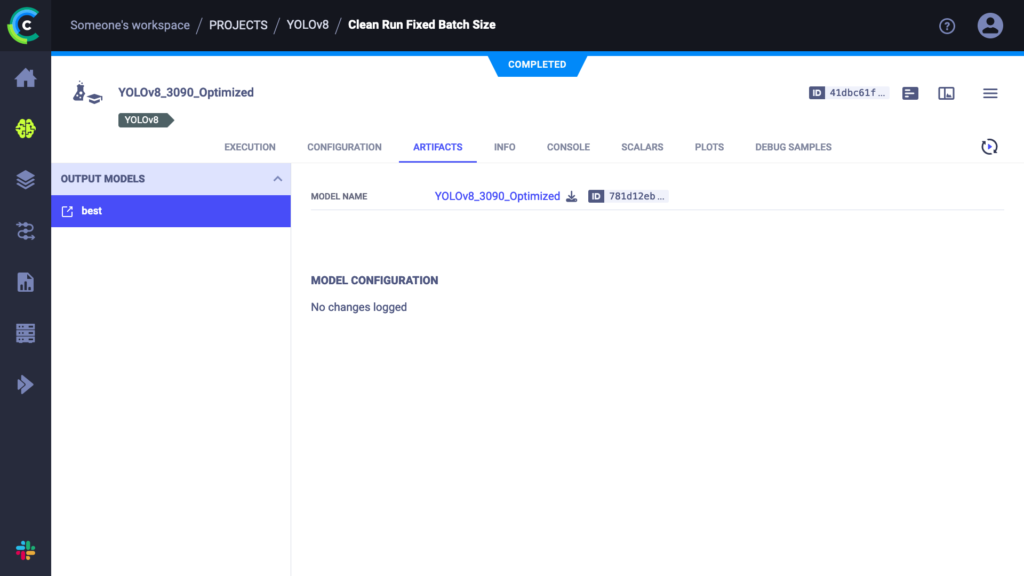
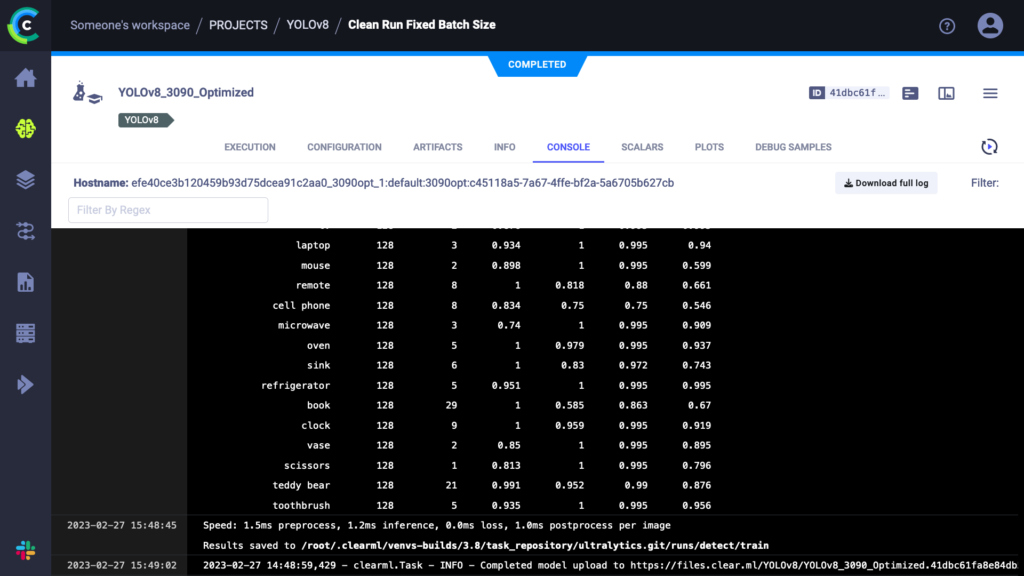
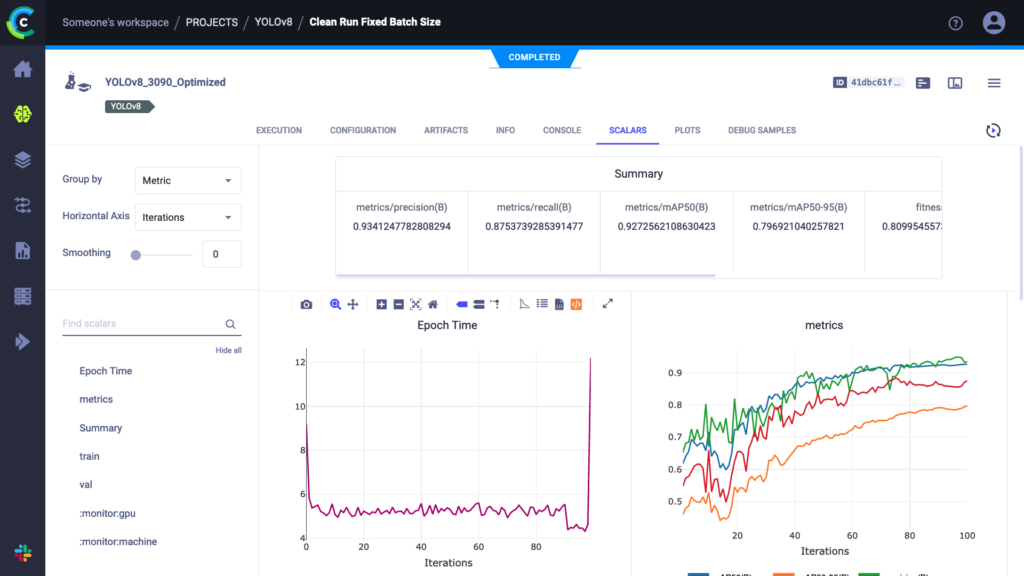
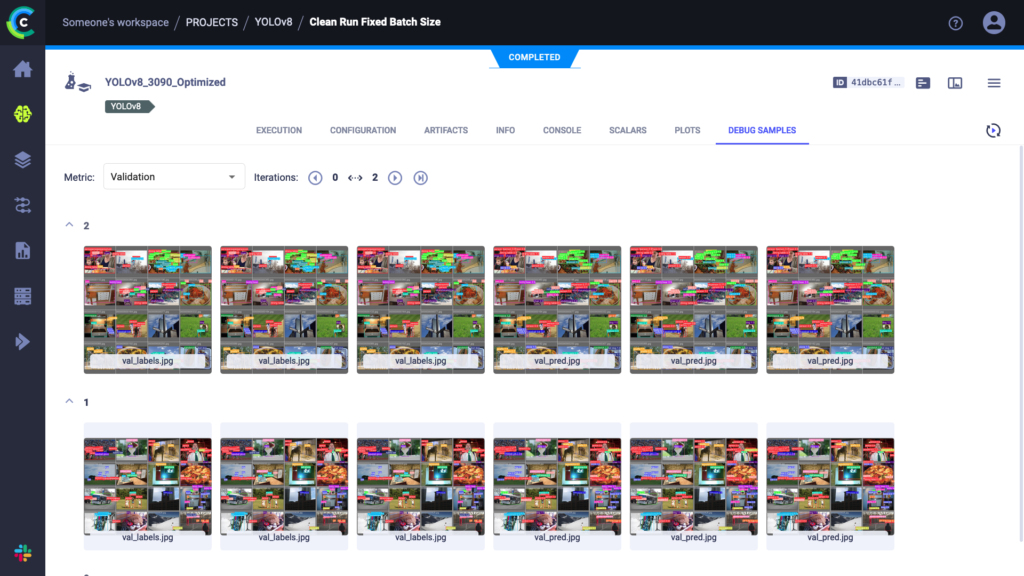
As you can see, everything we need is in there. In fact, YOLOv8 automatically comes with measured timings, both for training epoch duration and inference time of the trained model. These are the timings we’ll use in our benchmark for this blogpost.
Remotely executing YOLOv8: Autoscalers
ClearML can also orchestrate remote machines and schedule your tasks on them for you. After running an experiment locally using the experiment manager, ClearML now also has a copy of this experiment on the server. You can then set up any number of task queues from the server and easily enqueue your experiment in them. A worker (called ClearML Agent) will be listening to the queue and be able to run the task for you.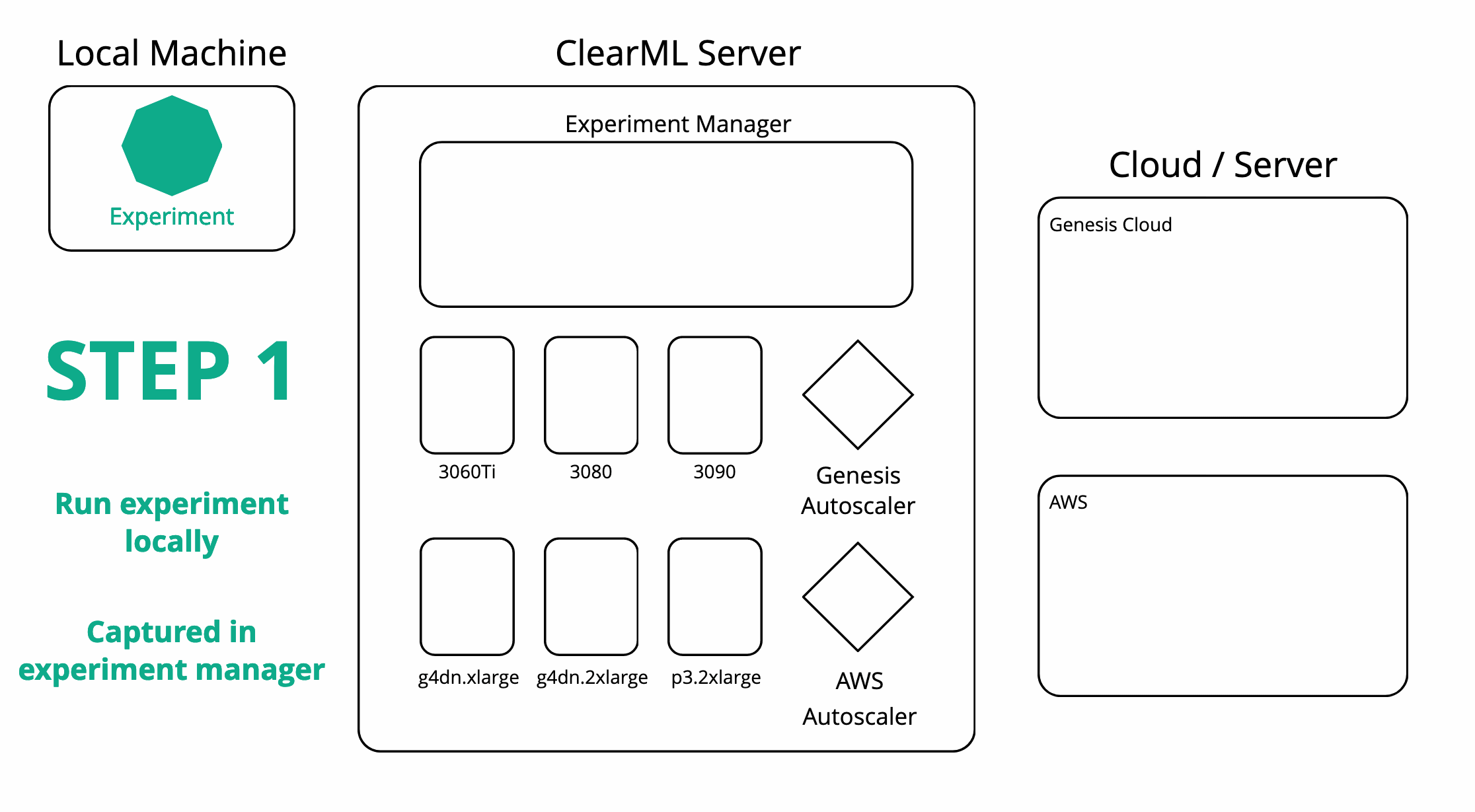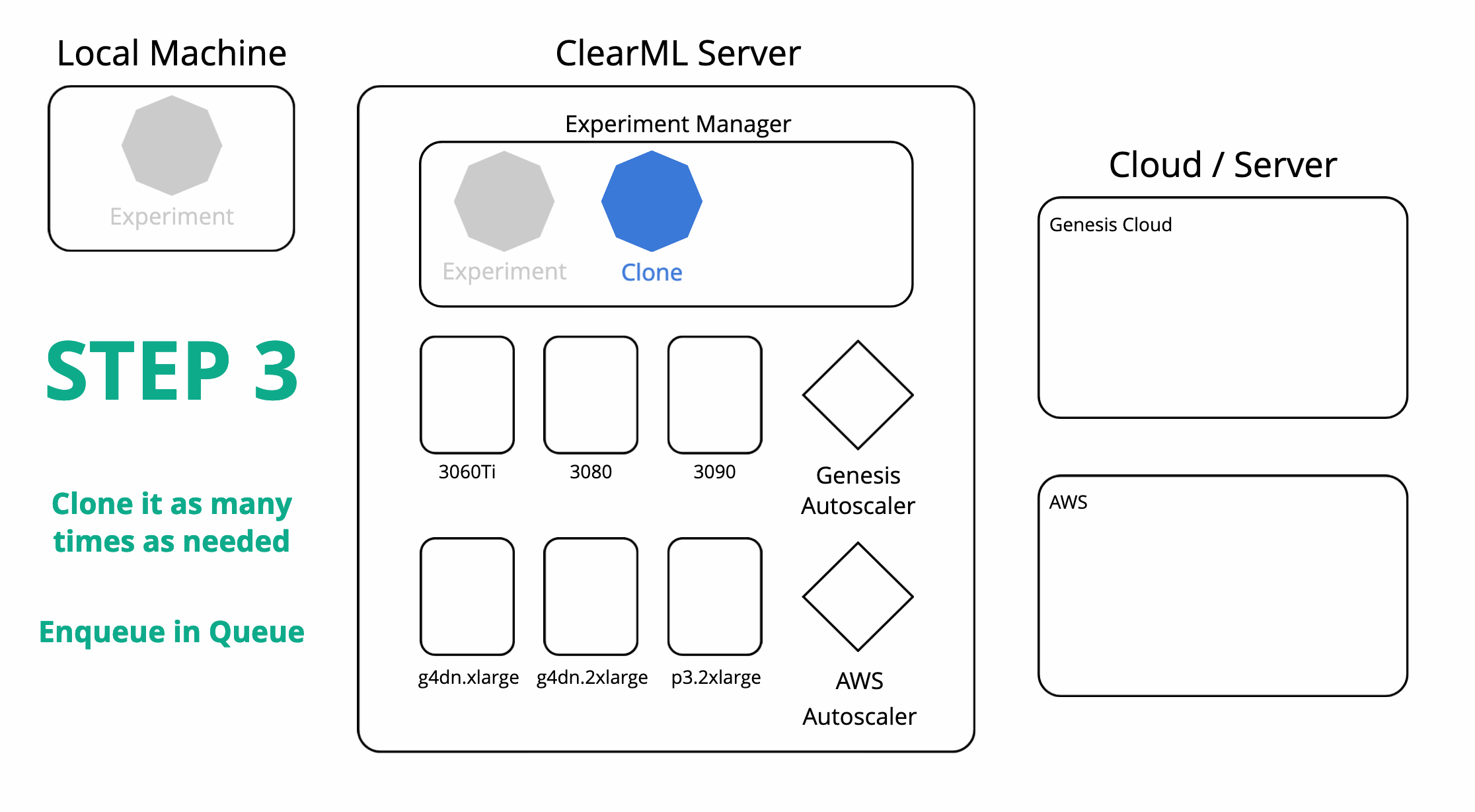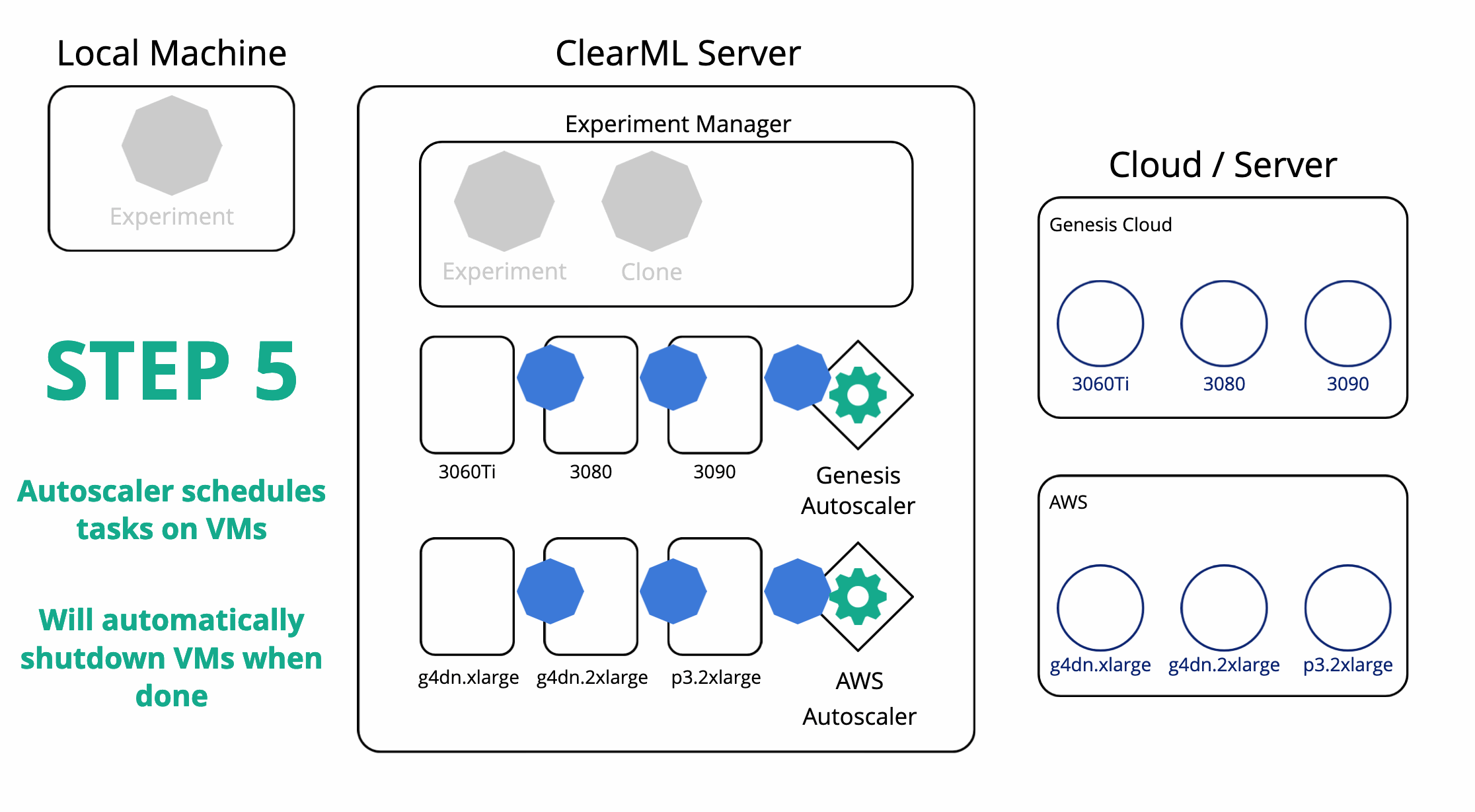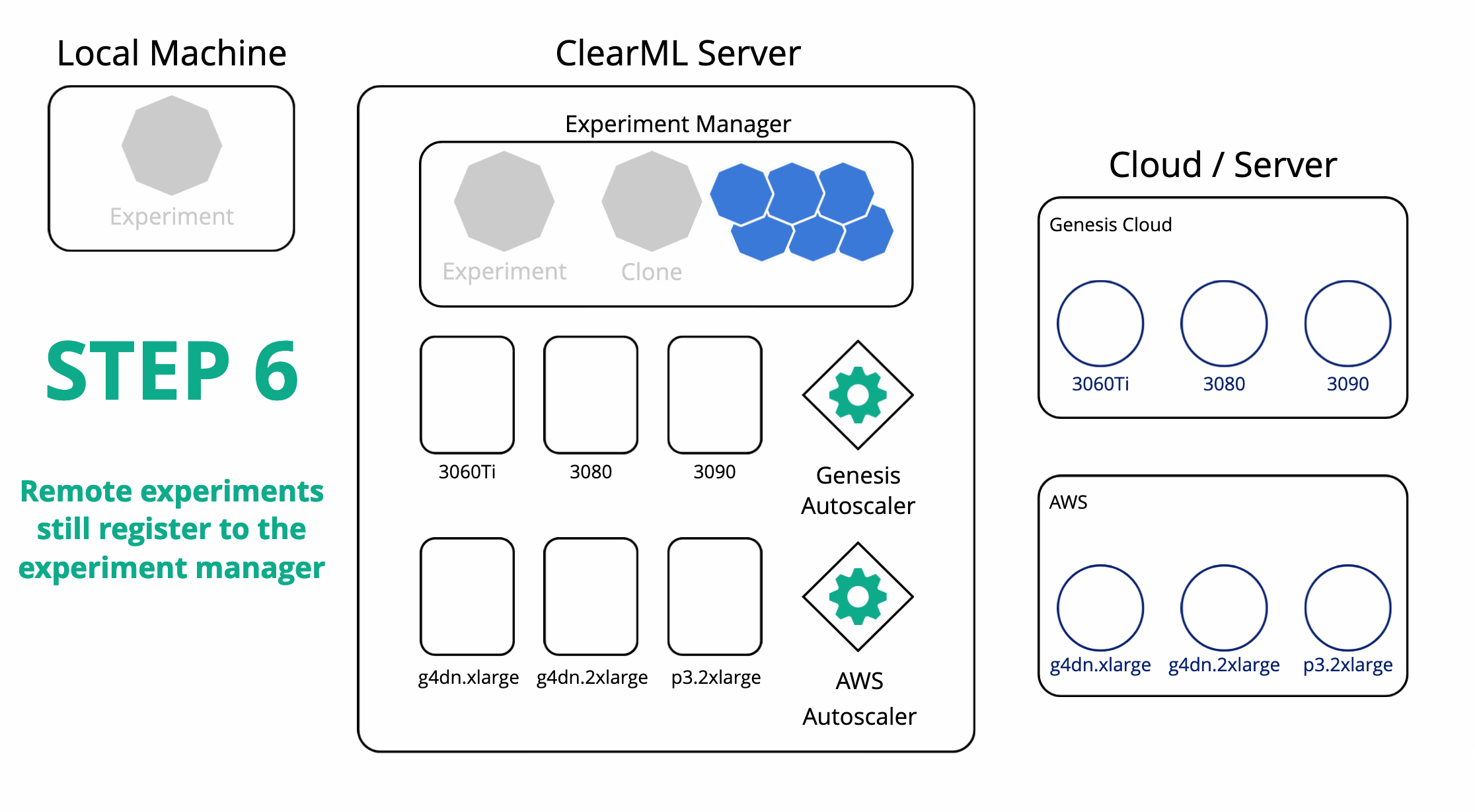
In order to get a worker to run your tasks, you can either set one up yourself or use an autoscaler. In ClearML, an autoscaler is essentially a service that keeps on running and monitors a specific ClearML task queue for any incoming tasks. If one is found, it will automatically spin up a worker to handle that task. One machine type per queue and you can set up a “budget” on how many machines of that type may be running at one time.
Rerunning our experiment on any of our target cloud machines is now as simple as cloning it and enqueuing it in the right queue. The respective autoscaler will pick up the task and start spinning up a VM of the required type. All of the results will of course be live-streamed back to the experiment manager, where we can follow along with the progress.
🔥 Benchmark Results
As you could see in the code snippet above, we chose the VisDrone dataset as our example benchmarking dataset. We tuned the batch sizes for each of the contestants to be as high as possible and then ran the YOLOv8 training on each of them.
Raw Performance Numbers
Below are the average training runtimes for the same, exact task (different batch size) for every machine type.
As expected, the 3060Ti performs well below the other machines, but remember its price is also significantly lower as we’ll analyse later.
The 3080 and 3090 machines do perform well and can generally hold their own when compared to the g4dn’s NVIDIA T4 card. However, at the lower end, we do see that both machine types are CPU bottlenecked. VisDrone has quite large images though, so this is probably use-case dependent.
The Mem & CPU Optimized versions of the 3080 and 3090 clearly surpass this CPU bottleneck and in doing so, leave the whole g4dn lineup behind to get into g5 territory. In fact, Genesis Cloud has come to the same conclusion in their own blogpost, serving as additional evidence for this claim. Especially the optimized 3090 configuration can handle its own vs the g5.2xlarge, a machine significantly more expensive. That said, the pure performance winner is still the g5.2xlarge.
Taking Cost into Account
Naturally, we’re not here to simply determine the fastest GPU machines bar none, if you’re not worried about cost, you’re probably already smiling down from on top of your 8xA100 VM. For the rest of us, though, cost efficiency does matter.
The graph below shows us the price per hour for each of the machines and then, crucially, the cost per epoch, otherwise interpretable as the cost efficiency.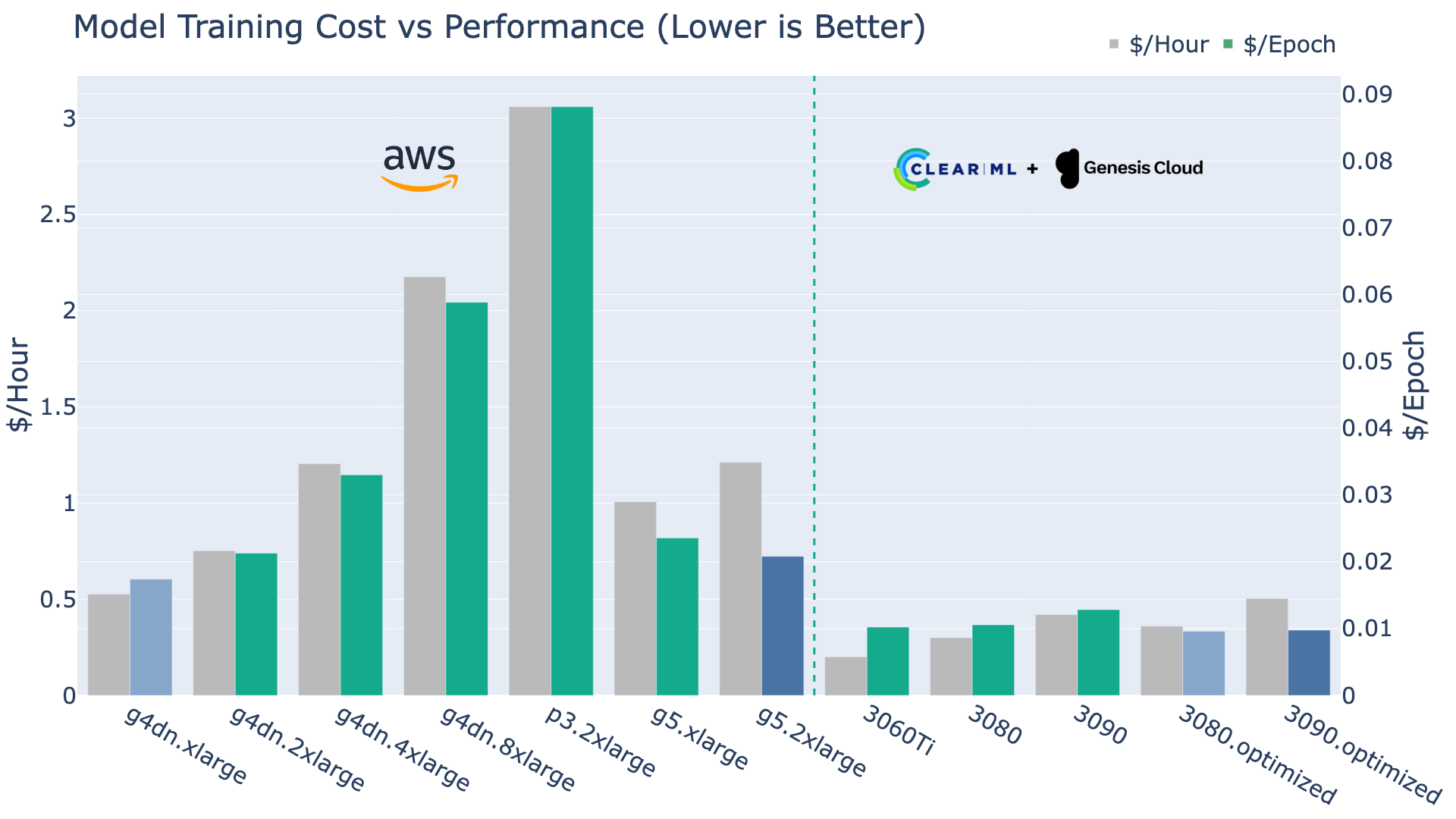
Naturally, this is where the story changes. For starters, the end-of-life V100-based P3 machines are both slower and more expensive than their younger counterparts and this shows in the numbers: the p3 V100 is very inefficient!
The g4dn lineup quickly starts to lose cost effectiveness at g4dn.2xlarge and beyond. From that point onwards, it might make more financial sense to swap over to the more expensive, but more efficient g5 machines.
On the ClearML side of things, the 3060Ti, even though it’s by far the cheapest, is not necessarily your best option here. The CPU bottlenecking of the standard 3080 and 3090 machines does show up here as well in the form of worse efficiency.
The Mem & CPU Optimized versions of these cards do hold their own though! The optimized 3080 and optimized 3090 are the most cost-effective ways to train a YOLOv8 model.
Consumer GPUs Can Compete with Spot Instances!?
Even when we compare the cost-effectiveness of AWS spot instances, which have very clear trade-offs (see above), the consumer GPUs still offer a compelling value. Bear in mind that in this plot, we are comparing ephemeral spot instance pricing to ClearML’s on-demand pricing. The fact that these are even in the same league is pretty impressive.
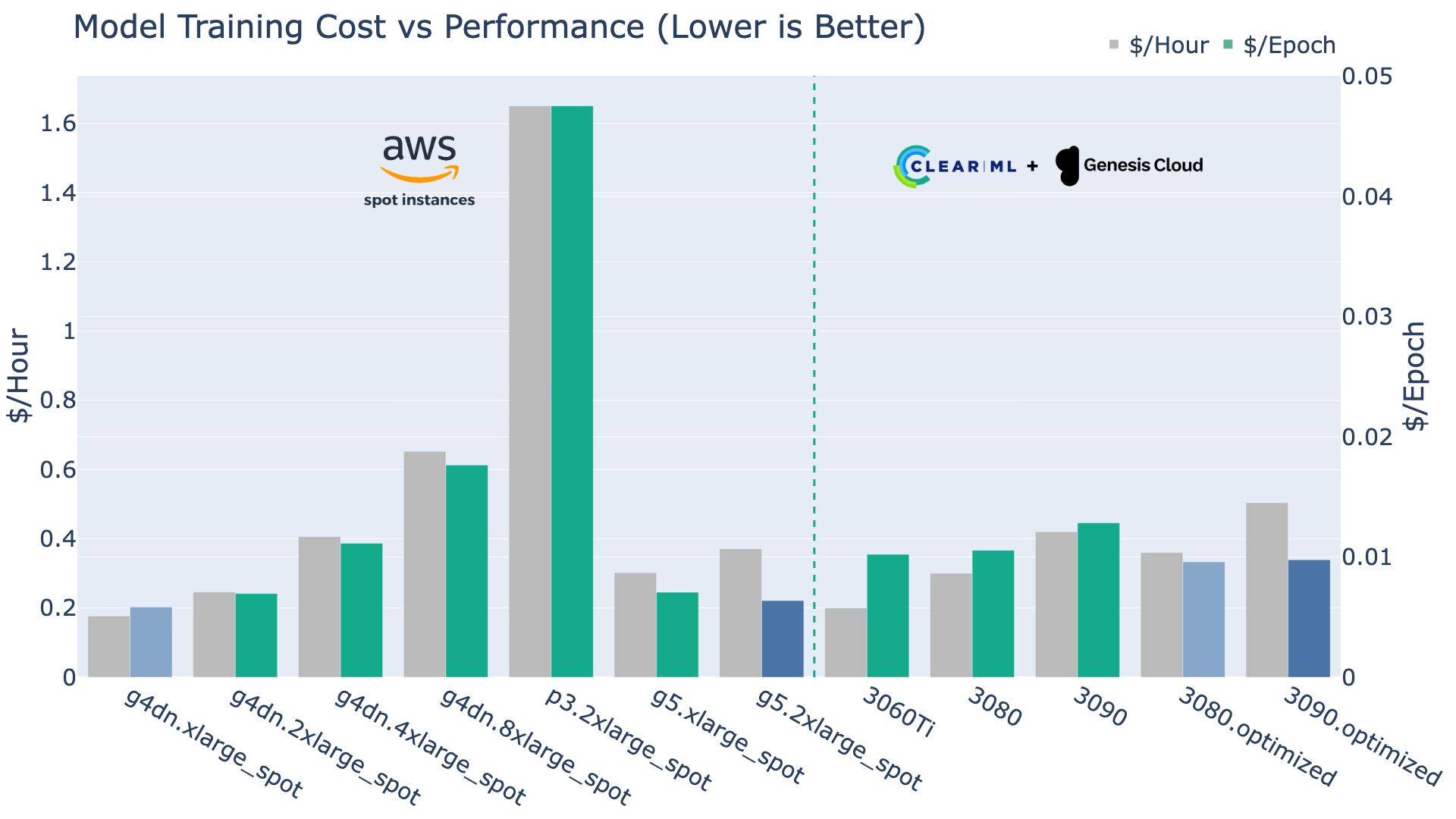
Smaller training jobs
Bear in mind that this benchmark was made to target a large training job with big images that can fully utilize the higher VRAM of the more expensive GPUs. If your dataset is much smaller, with much smaller images, it might not work out in the same way for you.
Next to that, smaller training jobs usually take less long. Given that setting up the machine, installing the environment, pulling the data and starting training can take several minutes on every machine, you should take this fixed cost into account as well! Training for 5 minutes vs 8 minutes after installing 10mins worth of packages is not a good use case for an expensive GPU! In that case, the lowest-cost cards like the 3060Ti can still be a very good pick.
Conclusion
Consumer GPUs are a very interesting choice for deep learning workloads. If all you need to do is to fine-tune a pre-trained model or train smaller-scale models on small to medium-sized datasets, then they are actually the most cost-effective option.
The ideal solution would be to buy these and run them yourself since they are off-the-shelf, but barring that, Genesis Cloud is your best bet to get these GPUs on-demand with ClearML making the process of scheduling tasks on them easy and offering even lower prices.
If you need to train large models from scratch such as LLMs or other large transformers on gigantic datasets, AWS still offers much more powerful cards like the A100 that the best consumer cards cannot even come close to. Next to that, if you’re not on a schedule and don’t mind being interrupted, the pricing of AWS spot instances is still the cheapest option.
Whatever you decide though, ClearML supports on-premise or cloud, spots or on-demand compute out of the box!
| Machine Type | Dollars / Epoch (Cost Efficiency) |
| ClearML RTX 3060Ti | 0.0102 |
| ClearML RTX 3080 | 0.0106 |
| ClearML RTX 3090 | 0.0128 |
| ClearML RTX 3080 (Mem & CPU Optimized) | 0.0096 |
| ClearML RTX 3090 (Mem & CPU Optimized) | 0.0098 |
| AWS p3.2xlarge | 0.0881 |
| AWS g4dn.xlarge | 0.0174 |
| AWS g4dn.2xlarge | 0.0213 |
| AWS g4dn.4xlarge | 0.0330 |
| AWS g4dn.8xlarge | 0.0588 |
| AWS g5.xlarge | 0.0235 |
| AWS g5.2xlarge | 0.0208 |
Next Steps
Let us know what machines you want us to take a look at! The first one on our list is the A100, to see how it stacks up in terms of cost efficiency.
We’d also love to test more models than just YOLOv8, such as LLM transformers to see how the efficiency might change with different model architectures.
Finally, we’re looking forward to seeing how the new generation of consumer GPUs will perform, the upcoming RTX 4090 looks like an absolute unit.
Check out ClearML here and here, it’s an entirely open-source MLOps platform made with ❤️.