
Originally Published in The Startup Medium by Ivan Ralašić – Republished by author approval
TL;DR
-
- What makes construction one of the most dangerous industries
- Learn the preliminary steps for developing a safety monitoring solution for construction sites:
- How TF2 OD API is used to train a basic object detection model for safety helmets
- Tips & tricks to manage your data and experiments efficiently
- Receive a supplementary Google Collab notebook to reproduce results and training quickly
- How ClearML integrates with the entire workflow
Introduction
Although the title might sound like a collaboration of two music bands with really bad names, this blog is all about understanding how computer vision and machine learning can be used to improve safety and security in a harsh and dangerous environment of a construction site.
The construction industry is one of the most dangerous industries according to the common stats from OSHA:
Out of 4,779 worker fatalities in private industry in calendar year 2018, 1,008 or 21.1% were in construction — that is, one in five worker deaths last year were in construction. The leading causes of private sector worker deaths (excluding highway collisions) in the construction industry were falls, followed by struck by object, electrocution, and caught-in/between. These “Fatal Four” were responsible for more than half (58.6%) the construction worker deaths in 2018, BLS reports. Eliminating the Fatal Four would save 591 workers’ lives in America every year.
1. Falls — 338 out of 1,008 total deaths in construction in CY 2018 (33.5%)
2. Struck by Object — 112 (11.1%)
3. Electrocutions — 86 (8.5%)
4. Caught-in/between— 55 (5.5%)
Wearing proper Construction Personal Protective Equipment (PPE) is incredibly important for construction worker safety and can help reduce the number of serious construction-related injuries. Construction PPE includes eye and face protection, foot protection, hand protection, head protection, and hearing protection. The most important part of the construction worker’s PPE is probably the helmet. Helmets are mandatory wherever there is a potential for objects falling from above, bumps to the head from fixed objects, or accidental head contact with electrical hazards.
Monitoring for proper usage of PPE is a time consuming and hard task for safety managers on construction sites since the environment is very dynamic and a lot of workers from different trades are present on the site simultaneously.
At Forsight, a construction tech startup focused on construction safety and security, we strongly believe that a combination of technology and in-depth domain knowledge can go a long way in making construction sites a safer and better environment where the risk of a serious injury is reduced to a minimum.
In this article, we’ll show you the first steps towards building a safety monitoring solution for construction sites. We’ll show how TF2 OD API can be used to train a basic object detection model for safety helmets, as well as to give you a few tips&tricks on how to efficiently manage your data and experiments, so let’s dive in.
P.S. the supplementary Google Colab notebook should help you to reproduce the results and the training process in no time!
Dataset

Getting the data
The first thing we need to ensure in order to train our OD detection model is that we have high-quality data. We cannot emphasize enough how important it is to obtain a high-quality dataset that contains images with a wide variety of light conditions, camera viewpoints, sensor resolutions, compression artifacts, etc.
An excellent helmet dataset by Liangbin Xie from Northeastern University in China was published on Harvard Dataverse. This dataset represents a good starting point for the development of a monitoring solution for proper PPE usage, although to create a solution for real-world use-case you’ll need to ensure that all the previously mentioned variables are covered. The dataset originally consists of 7035 images (5269 in the training set and 1766 in the validation set). The dataset includes three classes: helmet, head, and person.
We’ve gone a step further and labeled all persons and safety vests in addition to the previously existing labels. As a courtesy of Forsight, we’re sharing the improved version of the dataset in form of binary TFRecord files that can be used out-of-the-box to train your model using the provided Google Colab notebook. If you want to use additional data that you have collected and labeled by yourself, you’ll have to convert it into TFRecord format using the instructions provided here.
Advanced Dataset Management
Deep learning experimentation at scale can be very challenging. At Forsight, we experienced the challenges firsthand. We started with a small fixed dataset and fed it to our training script using a TFRecord file. This was the easiest and fastest way to bootstrap our research efforts without the need to change the reference code.
As our team and efforts grew, so did our data. Managing data, especially associating which model trained on what data, became a time-consuming ordeal that forced us to spend time on manual documentation which proved to be an error-prone process, which in turn wastes more time trying to reproduce results.
Having already used ClearML as our research management solution, it was an easy choice for us to upgrade to the enterprise solution that offers dataset management, along with other features. The dataset management from Allegro.ai allows researchers to accurately reproduce experiments by tying the specific data version that the network was trained on.

The dataset manager provides full visibility into which data is available and allows our researchers to write queries and get specific subsets of the dataset without data duplication and with an easy to use interface.
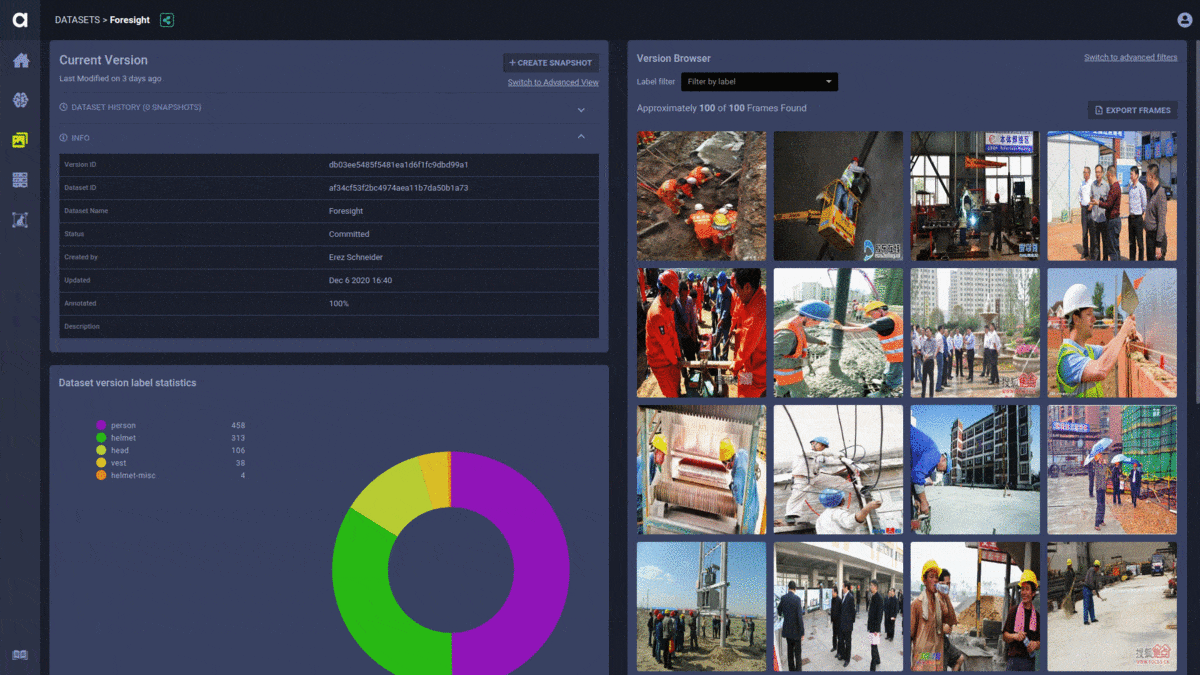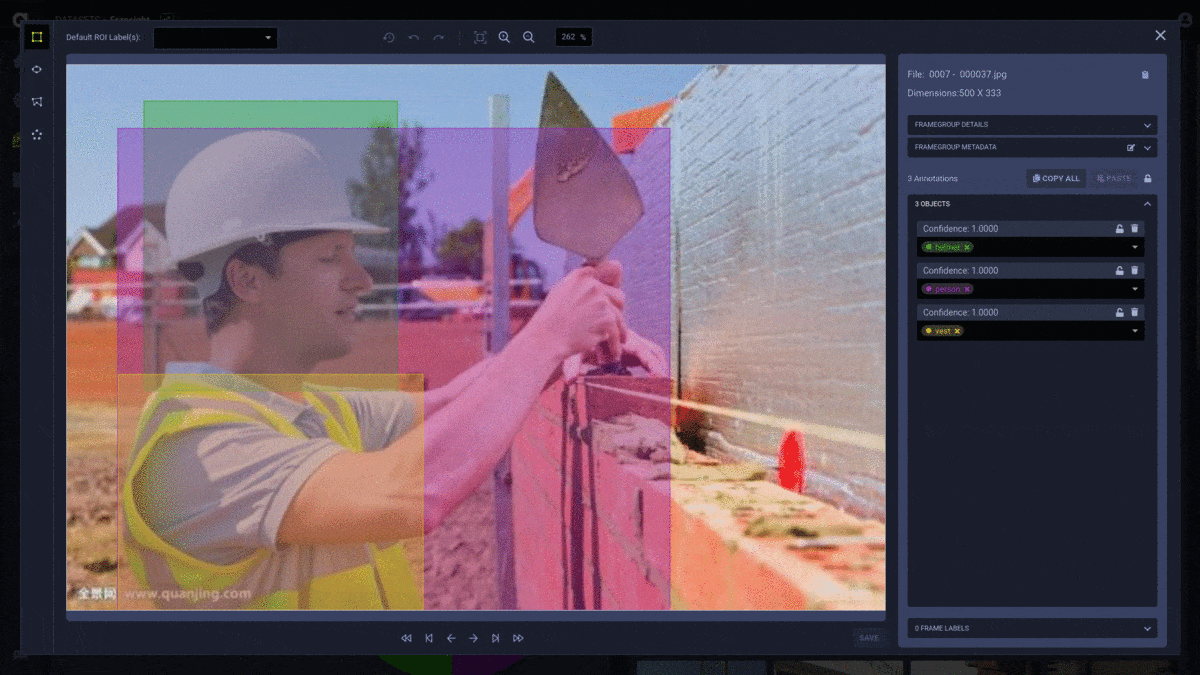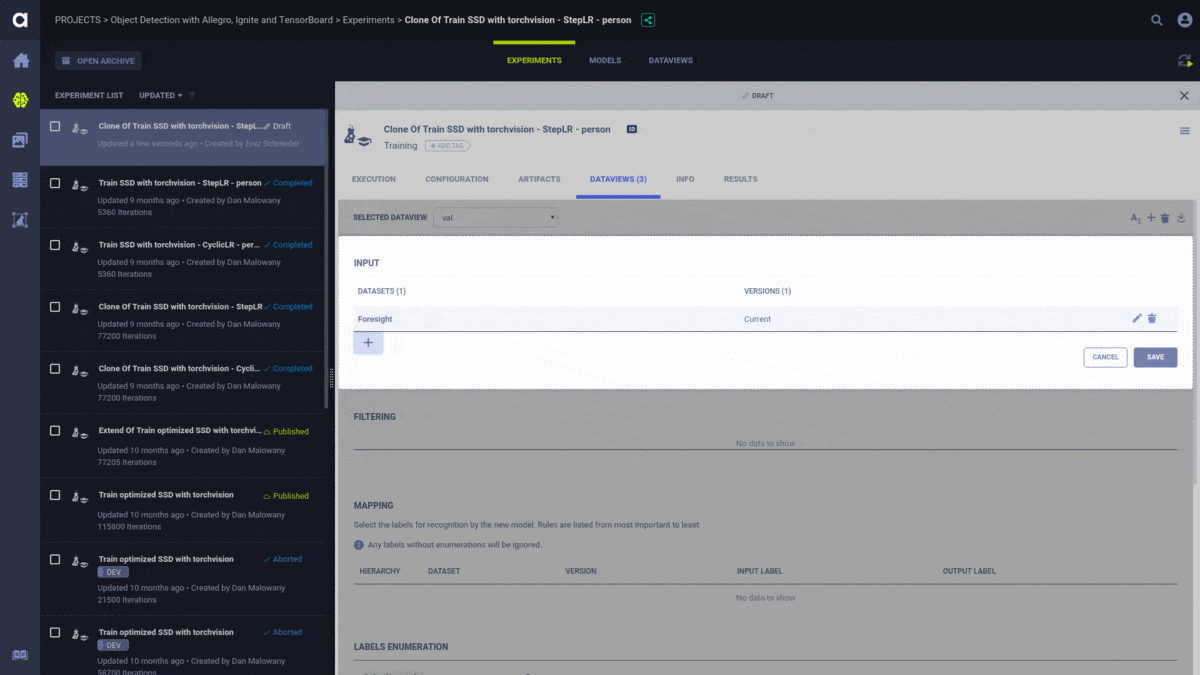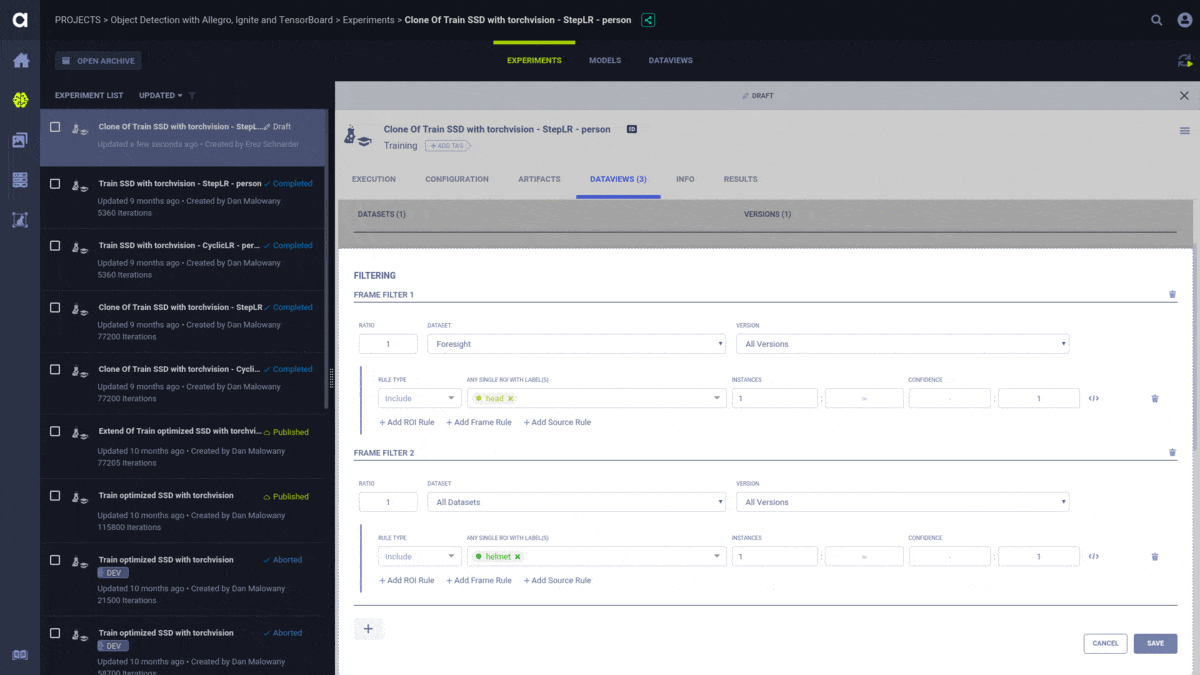
This is also the time when we abandoned the TFRecord files and integrated directly with ClearML’s system. This allows us to get frames on-the-fly, as needed, from our centralized data storage instead of having to copy the whole dataset to each new training machine. ClearML caching made sure that data persists on the machine and there’s no need to copy it with each new experiment.
We also used the dataset manager to balance and debias our data. Naturally, some events and objects occur less frequently compared to others. If you want to address those events properly during the training of an object detection model, you have to make sure that this gap is bridged using either certain augmentations or synthetic data.
Having a single control panel for all of our machine learning stack proved to be invaluable. Being able to change the training dataset with a few mouse clicks reduced the amount of custom data-mangling code we had to write, and helped us avoid the even worse option — integration with another tool to manage our data and then writing custom integration code between the data management tool and the experiment management one.
Training, evaluation, testing
For the training of the helmet detector, we’ll be fine-tuning a pre-trained object detection model from the TF2 Object Detection Model Zoo. Specifically, we’ll be using EfficientDet D0 512×512 which offers a good trade-off between speed and accuracy. You can read more about the EfficientDet model architecture on the following link, or you can check the in-depth performance analysis in our previous blog in this series.
We’ve prepared a Google Colab notebook so you can start training your helmet detection model within seconds. We are using a fork of TF OD API repo since we’ve applied a patch to the pycocotools, which enables getting per-category mAP metrics. This way we get more granular insight into the performance of the trained model. For example, you might be interested in how the model performs in relation to the size of the observed objects. From the aggregated statistics, it’s impossible to get such insights, while the proposed patch enables you to do it! Furthermore, we’ll be using ClearML, which offers powerful visualization capabilities and makes performance analysis of the trained model much easier.
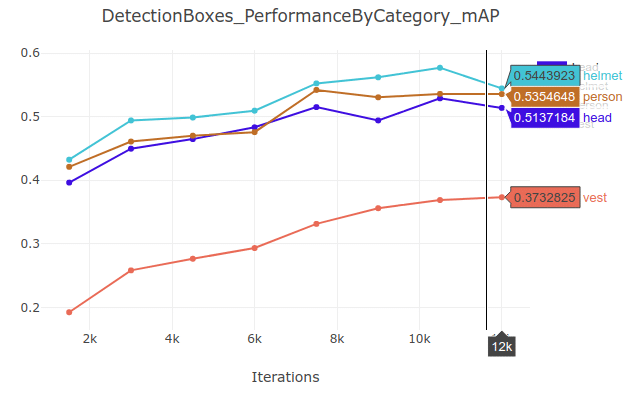
Per category mAP metrics for EfficientDet D0 model on helmet dataset (image by author)
Finally, we’ve shared a script that allows you to perform the model evaluation without having to stop the training. This has been one of the biggest frustrations when switching from TF1 to TF2 OD API as reported, since the simultaneous train/eval workflow doesn’t work out-of-the-box! This script just handles both the train and eval part by using subprocesses, and it uses the exact same parameters as the model_main_tf2.py script.
Script to run train and eval for TF2. Usage instructions: python object_detection/model_main_tf2_train_eval.py \ --model_dir PATH/TO/MODEL_DIR \ --pipeline_config_path PATH/TO/DIR/pipeline.config \ --num_train_steps \ --sample_1_of_n_eval_examples 1 \ --eval_time \ --task_name
Configuring the training and evaluation pipeline

Close-up of Machine Part in Factory by pixabay from Pexels.com
The TensorFlow Object Detection API uses protobuf files to configure the training and evaluation process. The first part of the pipeline.config file is related to the general model settings (i.e. meta-architecture, feature extractor). The only thing that you need to change in this part of the config file is the number of classes num_classes present in your dataset!
# SSD with EfficientNet-b0 + BiFPN feature extractor,
# shared box predictor and focal loss (a.k.a EfficientDet-d0).
# See EfficientDet, Tan et al, https://arxiv.org/abs/1911.09070
# See Lin et al, https://arxiv.org/abs/1708.02002
# Trained on COCO, initialized from an EfficientNet-b0 checkpoint.
#
# Train on TPU-8
model {
ssd {
inplace_batchnorm_update: true
freeze_batchnorm: false
num_classes: 90 # in our dataset we have 4 different classes
add_background_class: false
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
encode_background_as_zeros: true
anchor_generator {
multiscale_anchor_generator {
min_level: 3
max_level: 7
anchor_scale: 4.0
aspect_ratios: [1.0, 2.0, 0.5]
scales_per_octave: 3
}
}
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 512
max_dimension: 512
pad_to_max_dimension: true
}
}
box_predictor {
weight_shared_convolutional_box_predictor {
depth: 64
class_prediction_bias_init: -4.6
conv_hyperparams {
force_use_bias: true
activation: SWISH
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
random_normal_initializer {
stddev: 0.01
mean: 0.0
}
}
batch_norm {
scale: true
decay: 0.99
epsilon: 0.001
}
}
num_layers_before_predictor: 3
kernel_size: 3
use_depthwise: true
}
}
feature_extractor {
type: 'ssd_efficientnet-b0_bifpn_keras'
bifpn {
min_level: 3
max_level: 7
num_iterations: 3
num_filters: 64
}
conv_hyperparams {
force_use_bias: true
activation: SWISH
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
scale: true,
decay: 0.99,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid_focal {
alpha: 0.25
gamma: 1.5
}
}
localization_loss {
weighted_smooth_l1 {
}
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
normalize_loc_loss_by_codesize: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.5
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
The next part of the config file defines the parameters that are used during the training step (ie. optimizer parameters, input preprocessing, and feature extractor initialization values). Since we’re going to use a pre-trained checkpoint in our training process, we need to define fine_tune_checkpoint path to our checkpoint file. Reusing pre-trained classification or object detection checkpoints (defined by fine_tune_checkpoint_type) speeds up the training process drastically since we’re not starting from randomly initialized model weights.
Another significant parameter in the train_config is the batch_size. On the one hand, the available GPU memory directly influences the maximum batch size, so you’ll need to reduce it so that the training data fits into the GPU memory. On the other hand, the batch size impacts how quickly a model learns and the overall stability of the learning process, so it is a very important hyperparameter that should be well understood and tuned!
train_config: {
fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/ckpt-0"
fine_tune_checkpoint_version: V2
fine_tune_checkpoint_type: "classification"
batch_size: 128
sync_replicas: true
startup_delay_steps: 0
replicas_to_aggregate: 8
use_bfloat16: true
num_steps: 300000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
random_scale_crop_and_pad_to_square {
output_size: 512
scale_min: 0.1
scale_max: 2.0
}
}
optimizer {
momentum_optimizer: {
learning_rate: {
cosine_decay_learning_rate {
learning_rate_base: 8e-2
total_steps: 300000
warmup_learning_rate: .001
warmup_steps: 2500
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
}
The train_input_reader defines which dataset the model should be trained on. The TensorFlow Object Detection API accepts inputs in the TFRecord file format by default. You have to specify the locations of both the training and evaluation files. Additionally, you should also specify a label map, which defines the mapping between a class ID and class name. The label map should be identical between training and evaluation datasets.
train_input_reader: {
label_map_path: "PATH_TO_BE_CONFIGURED/label_map.txt"
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/train2017-?????-of-
00256.tfrecord"
}
}
The eval_config part of the pipeline.config file determines what set of metrics will be reported for evaluation. We’re using COCO object detection evaluation metrics which are defined here.
eval_config: {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
batch_size: 1;
}
Finally, eval_input_reader part of the pipeline.config file defines the evaluation dataset.
eval_input_reader: {
label_map_path: "PATH_TO_BE_CONFIGURED/label_map.txt"
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/val2017-?????-of-00032.tfrecord"
}
}
After tuning the parameters discussed above, we just need to start the training process and wait for the loss to converge… sit and relax!
Testing the trained model
After a few hours, our model will learn to recognize construction PPE! The last part of the supplementary Colab notebook tests the trained model on a sample image. The testing part of the code shows how to download the sample image, read it into NumPy array, perform inference using the last checkpoint from the training process, and finally visualize the detection results. In the image below, we can see that the model performs very well on the sample image, and detects even the person in the back with a high confidence score. You can easily generalize the sample code to run object detection on videos too!
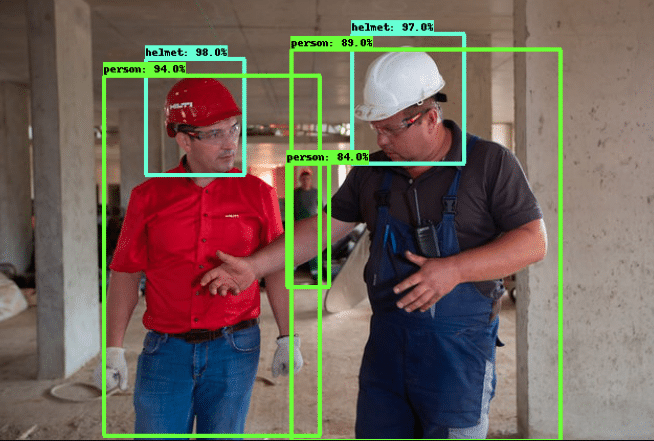
Person In A Construction site by aleksey from Pexels.com (with inference results overlaid)
Conclusion
In this second blog of our series, we’ve hopefully provided some useful insights about safety in the construction industry, and how technology is changing the landscape. We’ve identified the most dangerous situations and the four most common causes of construction-related fatalities. Our mission is to save human lives by preventing serious accidents that currently happen on a daily basis on construction sites around the world.
In order to help ML/AI enthusiasts, and anyone interested in helping to solve this problem in general, we’ve shared a sample dataset for training a safety helmet detector that can be used in real-world scenarios. Furthermore, we’ve created and shared a Google Colab notebook which gives you the ability to train your own helmet detector and use it on your own data in a matter of minutes.
References
- Census of Fatal Occupational Injuries Summary, 2018, https://www.bls.gov/news.release/cfoi.nr0.htm
- Xie, Liangbin, 2019, “Hardhat”, https://doi.org/10.7910/DVN/7CBGOS, Harvard Dataverse, V1
- Tensorflow Object Detection API, https://github.com/tensorflow/models/tree/master/research/object_detection
- COCO — Common Objects in Context, https://cocodataset.org/#home