When approaching machine learning operations, the options can be overwhelming. There may be multiple solutions available for each step in the process, and the most popular (usually open source tools) may not necessarily be good or easy to use, but they are free 😁. However if not open source, you are at the vendor’s mercy for integrations. In this blog post, we will give a high-level comparison of ClearML against other point solutions within the data versioning, experiment management, and scheduling and orchestration space to help you understand why ClearML is the best solution for enterprise MLOps.
In case you don’t know, ClearML is a unified, open source, end-to-end platform that supports the entire ML lifecycle from research to production. The platform’s open architecture lets you choose whether to use our best-of-breed modules or swap in your existing tools, making it an easy way to plug into as well as augment your existing processes and systems.
![]()
ClearML vs. Data Versioning Solutions
Managing your data on ClearML is painless and easy. Our automated data logging tracks every change for every run, making tasks repeatable without eating up a lot of storage or managing tons of credentials. The intuitive features built into the UI, such as tags, sampling, and visualization, make understanding and sharing your data catalog much easier. And ClearML gives complete visibility of your data’s lineage and where it is being used in tasks and pipelines. Once the data is configured, it can be accessed by anyone (with the right permission settings) from anywhere.
Connected with the larger ClearML continuous machine learning platform, your data is connected to experiments and jobs as well as outputs. Achieve full reproducibility and iterate faster by running cloned experiments with minor argument adjustments.
ClearML has been designed to accommodate a wide variety of model training use cases; however, the platform especially excels at managing unstructured data. ClearML handles file management at the file-level, which is great for image, audio, video, or text files, but we understand that can present some challenges when working with tabular files, such as multi-GB parquet or CSVs.
Enterprise customers leveraging our Hyper-datasets feature can access elegantly abstracted metadata that enables oversampling and debiasing without the difficulties of working with cumbersome large files. Metadata and annotations are automatically versioned into a database, letting you slice the data in real time and change the streaming data sources going into tasks, experiments, jobs, etc. ClearML Hyper-datasets are a powerful tool for making data easy to access, regardless of where that data physically resides (which is never within ClearML– we only keep metadata in our backend server).
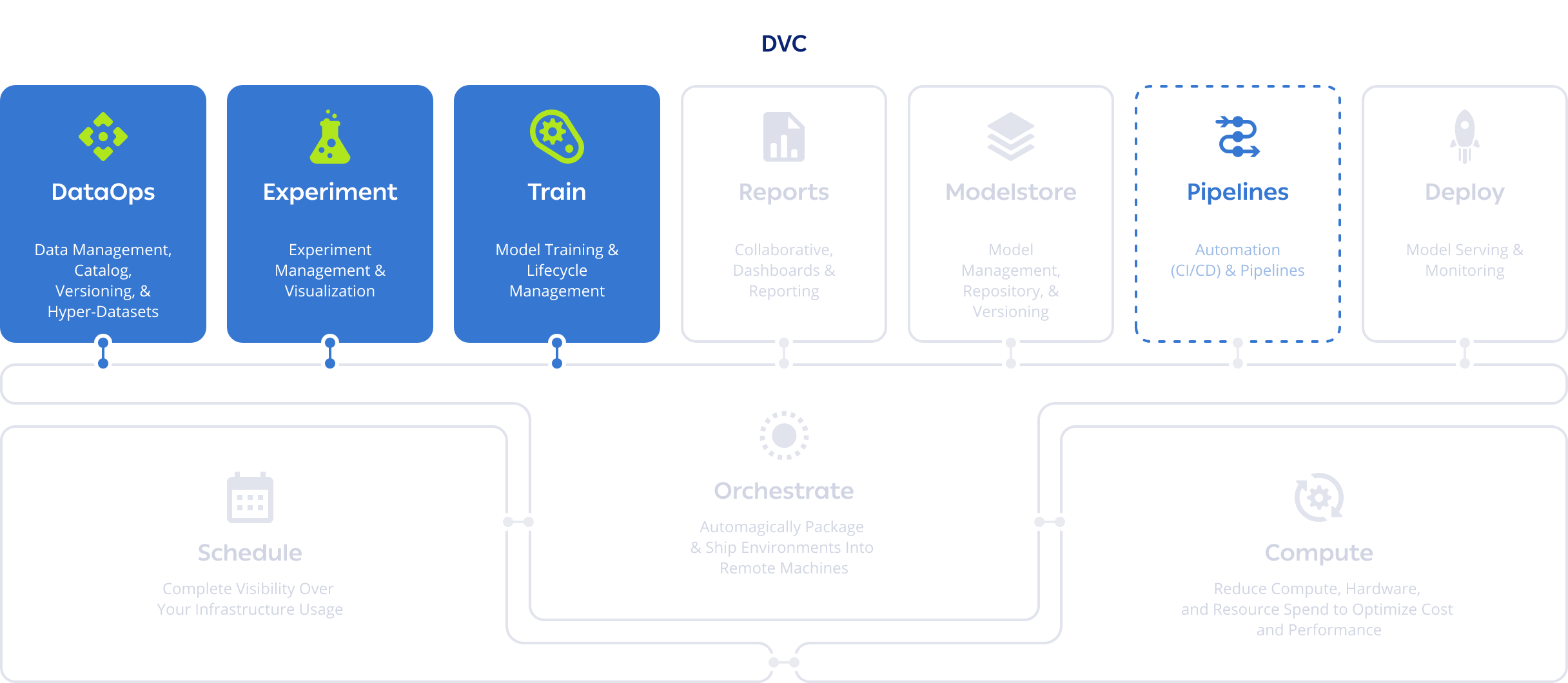
ClearML vs Experiment Management Solutions
Experiment Management solutions are the most common MLOps tools on the market today. While there are superficial differences between interfaces, performance evaluation dashboards, and different defaults for logging to the cloud or a local drive, the big differences show themselves when you are trying to compare multiple runs, execute tasks faster, or manipulate very large datasets.
Fundamentally, ClearML’s unified MLOps platform uses Python (R is not supported) and connects orchestration into every part of experiment management, automatically logging configs, parameters, and settings for every run and facilitating faster progress overall through automatic capture of metadata and advanced caching. Experiments are immediately reproducible and can be rerun again using different parameters with just one click. Real time reporting and sharing is easy as well. Live plots of results are embeddable in third party editors like Notion or Confluence.
ClearML was designed to make life easier for data scientists and ML engineers. Building pipelines is intuitive and dare we say, enjoyable. We support project hierarchies with RBAC, track literally everything (including git diffs), and allow you to compare as many experiments as you want against each other. Well, actually only up to 100 experiments, but if that’s not enough for you, we can talk about it 😉. Although we can’t boast the biggest numbers, we have (in our opinion) the best community of actively engaged members for sharing ideas or asking questions.
Deploying trained models into production is seamless on ClearML, as all parts of the operation already “speak the same language” across the platform. There is no need to reformat or reconfigure anything, and setting up a true CI/CD feedback loop is not only possible, it’s easy. Your DevOps team will really appreciate that.
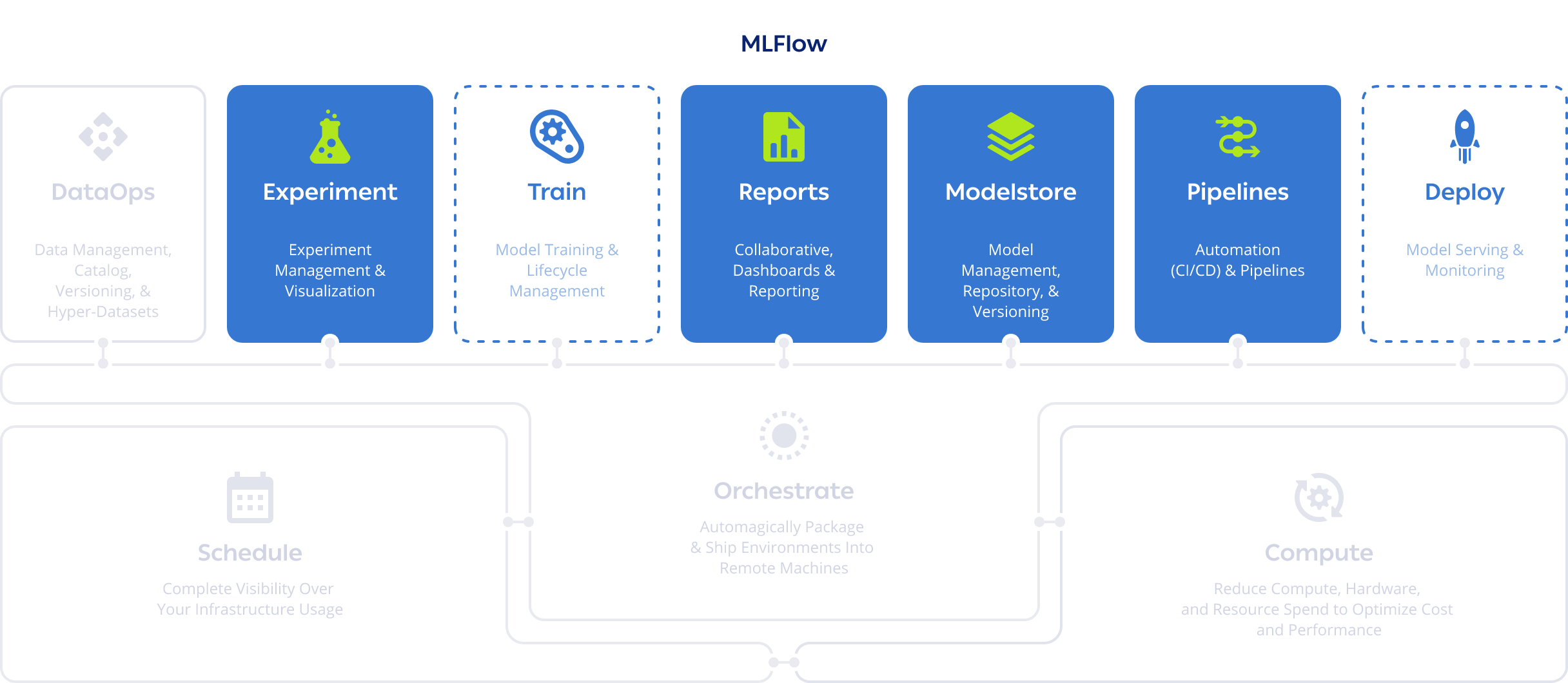
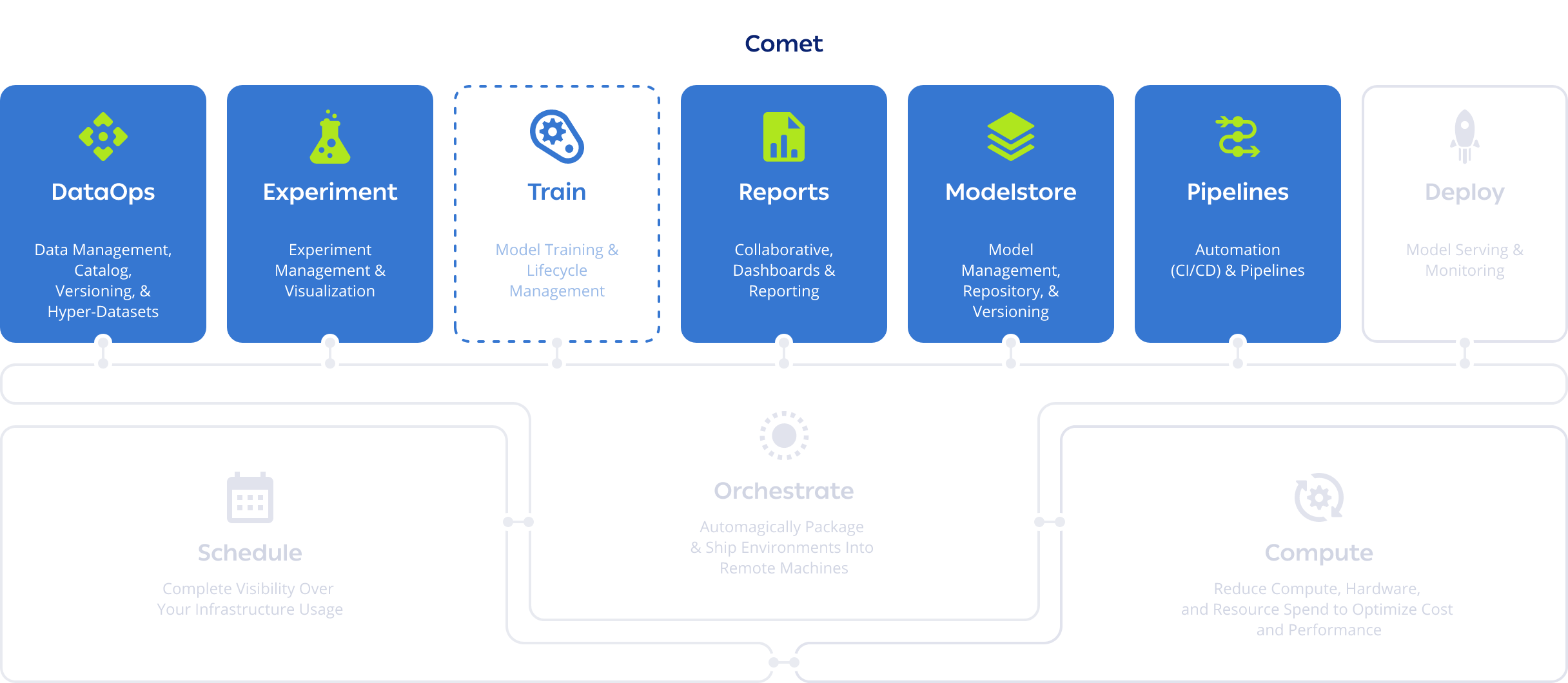
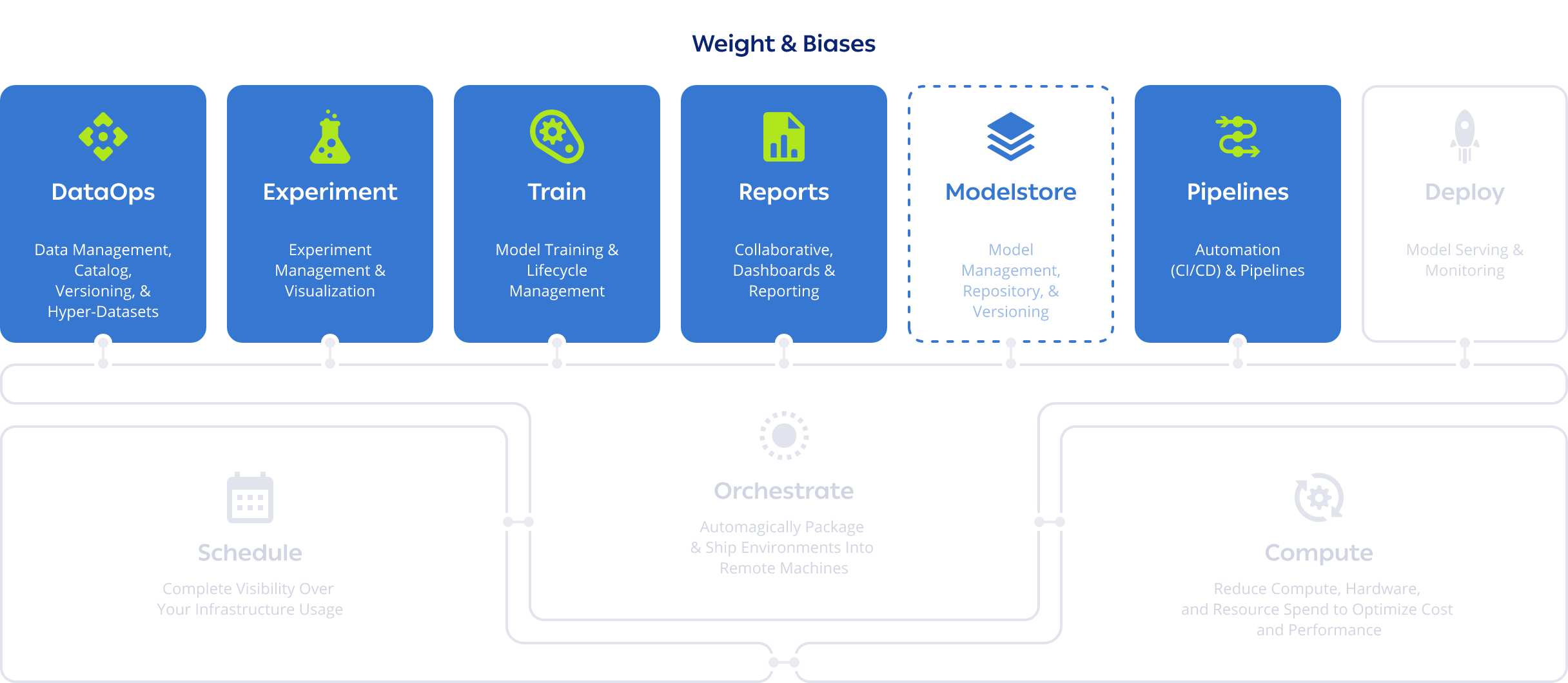
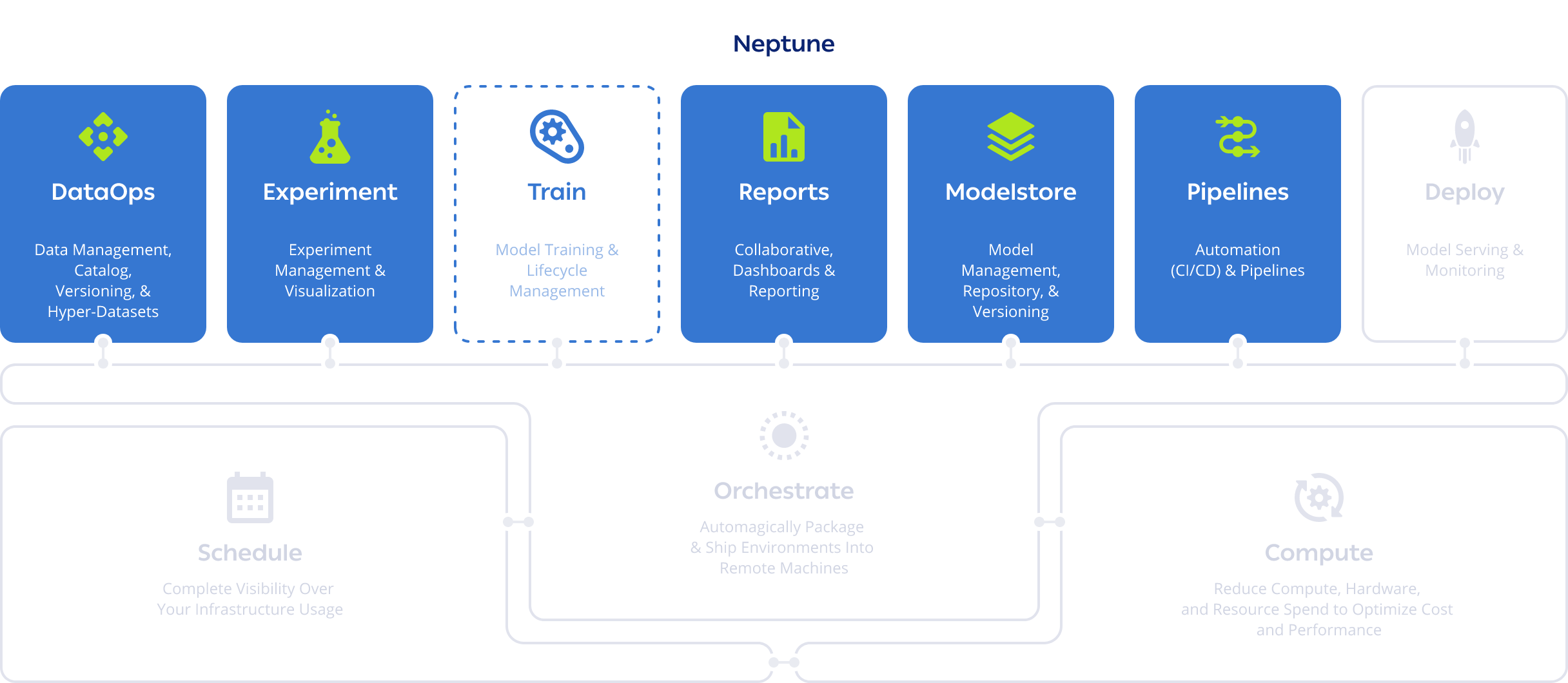
ClearML vs Scheduling and Orchestration Solutions
ClearML’s built-in capabilities let you fully schedule, orchestrate and automate your machine learning workflows and pipelines without paying for any other software. Working on ClearML is easy and flexible – you can deploy straight from your development environment and launch from anywhere (code, CLI, Git, or Web UI) into your infrastructure (cloud, on-prem, Docker, Kubernetes, or Slurm). Your infrastructure could be fully cloud-based or on-prem, it doesn’t matter. ClearML is cloud-agnostic and also supports installation on bare metal (no Kubernetes required).
ClearML eliminates the need to containerize every job, saving time, storage, and storage cost.
Build transparent, prioritized job queues that let team members see the full breadth of current work, re-order their jobs, and collaborate more often and easily. Max out your compute utilization! ClearML is certified to run the NVIDIA AI Enterprise Software Suite and allows customers to take full advantage of the GPU power of NVIDIA DGX™ systems and NVIDIA-Certified Systems™. Take advantage of NVIDIA’s new capability for GPU slicing and creating up to 7 partitions per GPU and match the correct computing power per workload. Fractional and virtual GPUs can be accessed by containers, allowing different workflows to run in tandem on a single GPU. All out of the box.
Need more muscle? ClearML Autoscalers enable you to spin up or spillover compute on AWS, GCP, or Azure on an as-needed basis, and usage can be controlled with team-level budget caps. ClearML enables more people to access compute power with less overhead.
Through ClearML, administrators can set up users with their permission levels once, without the stress of provisioning more machines, managing credentials, or tracking compute usage. Our modular architecture and open source nature make integrations with other tools easy. Managing your entire MLOps infrastructure overall becomes a much lighter burden on your engineering team.
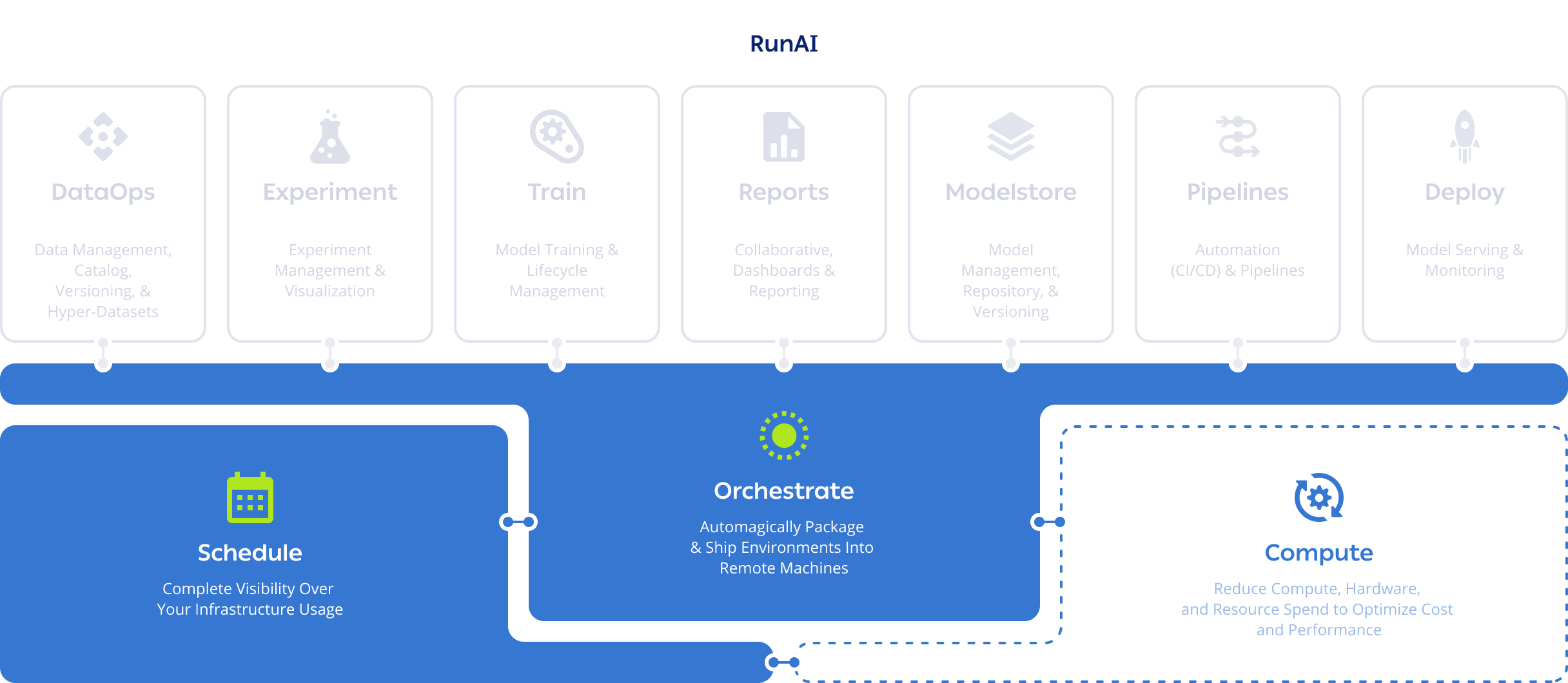
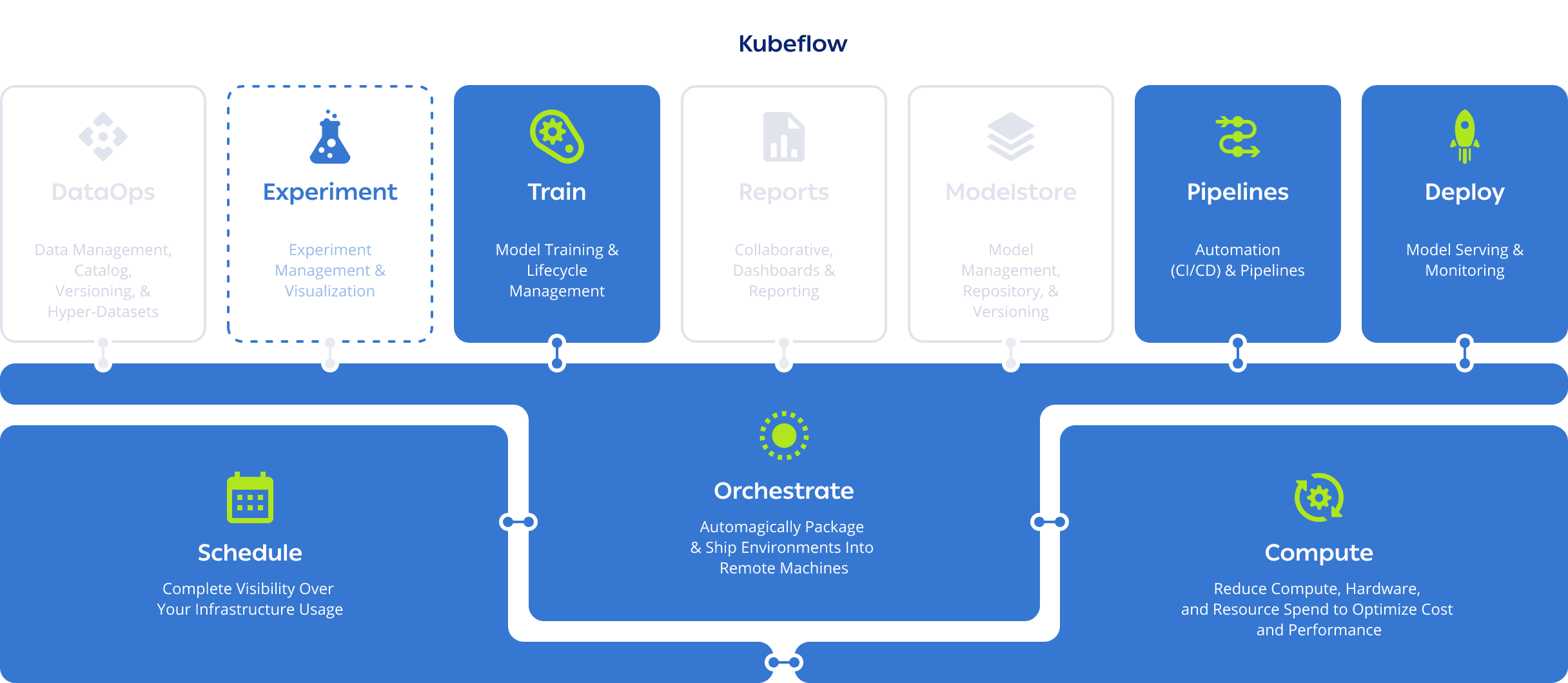
Next Steps
As you’ve seen, ClearML enables Data Scientists, ML Engineer, and DevOps to efficiently do machine learning and deep learning work on a single, intuitively architected, open source platform that does all your heavy lifting. However, whether you prefer one MLOps platform that handles all of the work or prefer many specialized tools is ultimately a decision your organization has to make. The choice is yours! If you’d like to get started with ClearML, use our free tier servers or host your own. Read our documentation here.
You’ll find more in-depth tutorials and amazing demos about ClearML on our YouTube channel and we also have a very active Slack channel for anyone that needs help.
If you need to scale your ML pipelines and data abstraction or need unmatched performance and control, please request a demo.