The ClearML Experiment Management Tools That Help ArgoScout… Grow!
Authored by Yaniv Menashe, Artificial Intelligence Engineer at AgroScout Ltd.
At AgroScout, we’re taking on a massive challenge with an exciting upside for us and our customers: creating an automated, AI-driven scouting platform for early detection of pests and disease in vast agricultural areas. With precise, data-driven insight (impossible to attain through periodic, manual sampling), a farmer can proactively prevent substantial loss of crops and corresponding revenues as he drives increased productivity across his acreage — all the while reducing pesticides use by more precise targeting of problematic areas.
What makes this so difficult?
Now here’s the catch – to gather our crop data, we use drone and camera footage to identify the subtle indicators of these threats. If this were all simply the same Big Data challenge common to companies focused on AI-based imagery analysis (medicine, construction, traffic, etc.), we’d be able to handle it by simply throwing plenty of computing resources at it. But working with imagery analysis for agriculture poses a few unique challenges:
- Annotation isn’t trivial; even experts can’t find all plant defects
- Analysis requires engaging a team of specialized, global experts to annotate; managing their work and standardizing their terminology needs to be precise
- High data modality. Each field – and even each field’s dataset – has unique and multi-input features to be learned and merged (e.g., changing lighting or flight angles).
- Scale – Just a single image can yield thousands of annotations, and annotation QA is difficult; there are often tens of thousands of these images.
Building a pipeline is all about the tools
So how did we face these challenges head-on? We realized we needed to integrate into our workflow a collection of data science tools to take some of the heavy lifting in all these tasks off of our hands.
The top candidate in our research was ClearML, since it claimed to be easy to integrate with and offered most of what we needed, all wrapped up in a single platform: from tracking our research to managing our cloud machines to data management.
![]()
Tackling Six Challenge with a Single Platform
Challenge 1
Processing those hi-res images.
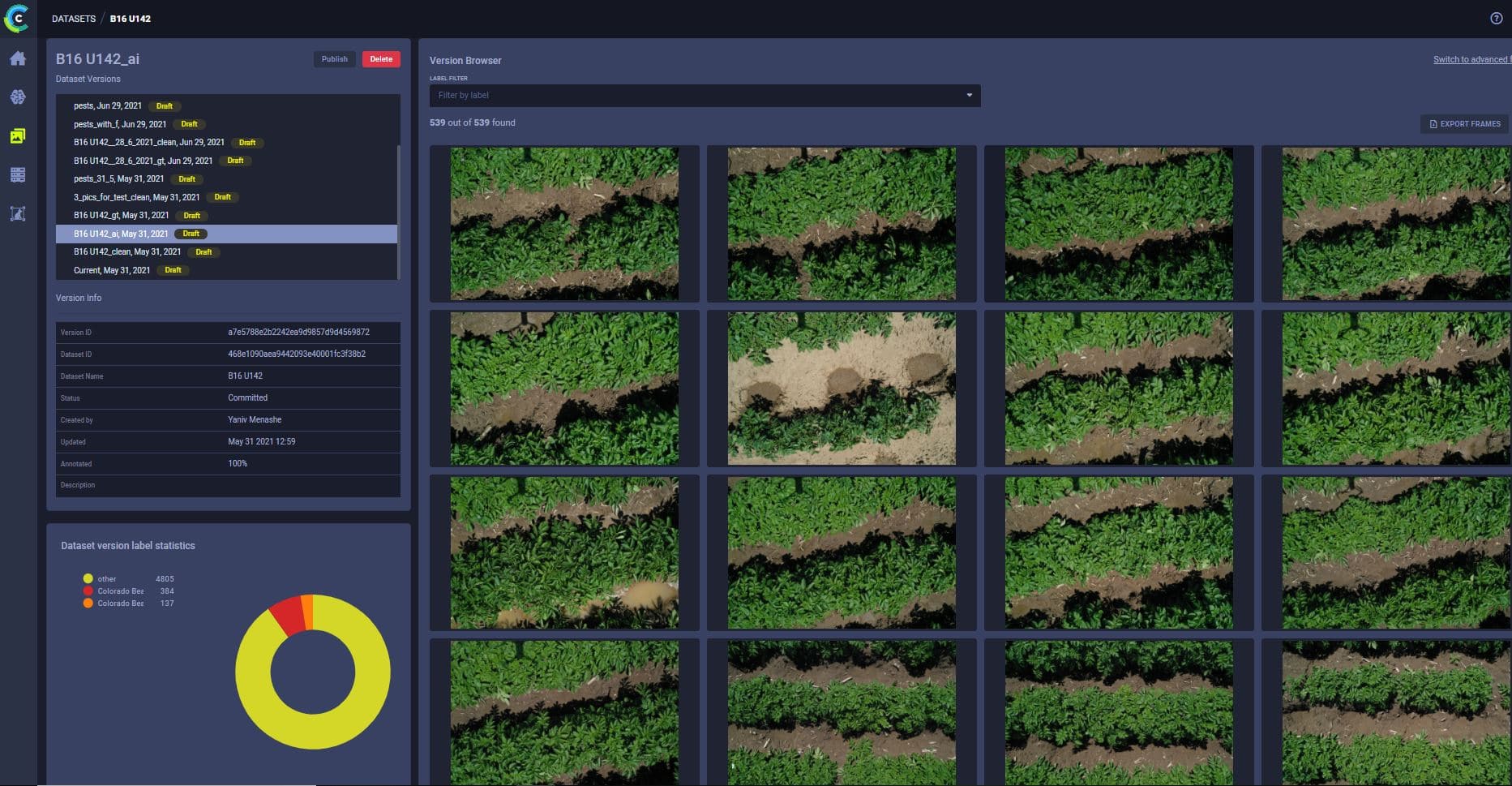
These large images are taxing on the GPUs processing them, so we make them more manageable by cutting up the images into sub-images before they’re used for training. Creating a “version” of the images in smaller sub-images reduces the time needed for every train-stage by creating a “pre-processed version” in the dataset, and multiplying the number of smaller files we manage. With ClearML’s dataset management feature, we create multiple versions for every dataset, including a version that has already completed the pre-process stage and is ready for the train stage.
Since storage space is much cheaper than computing resources, this course of action was our natural choice, and ClearML makes it easy to do. That alone is a game-changer, but it’s only the beginning.
Challenge 2
Working on problems in the bio world that are hard to generalize.
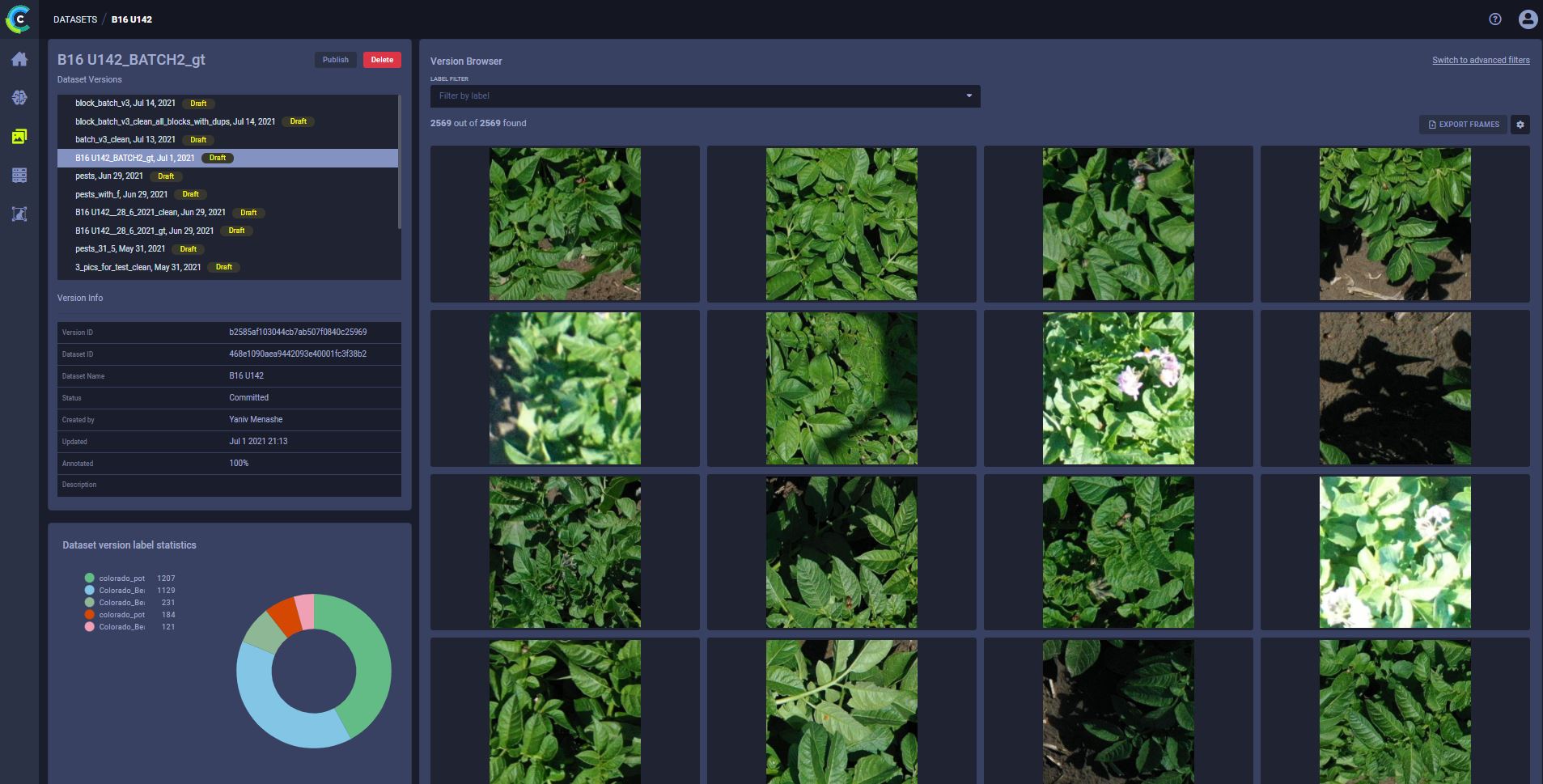
To illustrate this point, let’s start with a photo:

As you can guess, even for a human, it is hard to detect all the diseases and pests, and to decide how exactly to classify what’s been detected. But they are there. Hundreds of them.
As mentioned, for these tasks, we needed skilled agronomist annotators to help fuel our models. But to get enough people with a wide variety of specializations requires working with more than one company, as well as working with agronomists who are acting as annotators for the first time. For the outset, we recognized that we’d need to deal with inconsistency in annotations from different companies using different JSON formats.
After parsing the companies’ output with their unique JSON schemes, we discovered that although we gave all the companies the same label names, they returned different outputs for those labels. And it gets even trickier … the difference wasn’t limited only to different companies; we got these discrepancies even from the same company working on different projects!
The solution? We discovered that we could spot the discrepancies right away in the dataset’s statistics in ClearML’s UI. After identifying the mismatches and the unification strategy needed, we deployed ClearML’s handy mapping tool and created an alias rule for all the labels representing the same class.
Challenge 3
Annotating growing datasets, with considerable variance, and with as few mistakes as possible.
As AgroScout is working with agricultural acreage around the globe, over five continents, every field has its unique characteristics: crop type, weather, age of the crop, the soil, and more. Furthermore, every flight can be affected by different variables (time of day, weather, flight path). The multiplication of datasets with unique metadata is therefore multiplied.
And then managing data is a problem. On the one hand, you want to have all the metadata readily available; on the other hand, maintaining multiple folders for each data type makes crawling through it and getting a “big picture overview” non-trivial.
We chose to use ClearML’s Hyper-Datasets to help us tackle organizing our data.
We decided that each flight should be represented as a different version.
ClearML Hyper-Datasets allow us to explore the data and then submit it (using fine granularity) into the training process. We can control which field, crop type, time of day, or any other data information our models see, making it possible to build highly specialized models. Obviously, everything is logged so we can conduct post-training analysis and reproduce models as needed.
Challenge 4
Working with images that contain thousands of annotations
One of AgroScout’s products is Stand Count. This product allows the user to monitor fields in high resolution, showing a stitched photo mosaic as a layer on top of the map. On top of this layer, the user can see thousands of annotations representing the four different classes that a farmer needs to understand precisely how the plants are progressing:
- Ground lift – The ground lifted upwards, indicating that a plant will sprout there soon
- First emergence – The plant’s first few days after sprouting
- Plant – An adult plant
- Gap – An area inside the field where there is none of the above
Having this multiple modality translates to an abnormally high annotation count per image. Such multitude not only poses a problem to annotators – it pushes annotation software to its limits. We had to choose data management software that can scale as we scale (growing images 10X could mean growing annotations 10kX) and saw that ClearML has no problem dealing with this quantity of metadata. It also allows us to edit annotations on the fly if we find mistakes.
Challenge 5
Managing workloads on GPU instances
Training and testing our many models require GPU resources. Like many companies, we decided to go with AWS for our compute resources. Using AWS Lambda as the interface for getting field data, we built data ingestion pipelines that are triggered by AWS Lambda. Then, using ClearML, we manage workloads on our EC2 instances for training use. This way, we can launch our experiments directly from one place and then monitor, and manage using ClearML’s Orchestration UI. Again, it’s something we could theoretically do manually, but it’s clunkier and more time-consuming to manage than with the elegance of ClearML’s management tools designed specifically for these tasks.
Challenge 6
Determining which models are better suited for our task
This is, obviously, the most common task for data science companies: When training many models (often simultaneously) as well as many environments (both On-prem and in the Cloud), we need effective tools for comparing results between the different experiments. At AgroScout, this model comparison process is exceptionally fluid and dynamic because of our “fuzzy” biological data representing an organic landscape’s continuously changing and unpredictable nature. With those experiments running, it’s crucial to have a powerful comparison tool: We use it to decide which experiments to stop and which models to let run and compare at the end. Without it, we’d probably “roll our own” solution, but we preferred to use a proven tool instead of building our own – a distraction from our core science.
Conclusion
At the end of the day, every machine learning company faces its own challenges, based on the unique, specialized data input and output it wrestles with on a day-to-day basis. ClearML’s suite of tools is front and center, helping us at critical junctures throughout our model development workflows, and will remain a core component of our infrastructure.