Authored by Dan Malowany at Allegro AI

Audio signals are all around us. As such, there is an increasing interest in audio classification for various scenarios, from fire alarm detection for hearing impaired people, through engine sound analysis for maintenance purposes, to baby monitoring. Though audio signals are temporal in nature, in many cases it is possible to leverage recent advancements in the field of image classification and use popular high performing convolutional neural networks for audio classification. In this blog post we will demonstrate such an example by using the popular method of converting the audio signal into the frequency domain.
This blog post is a third of a series on how to leverage PyTorch’s ecosystem tools to easily jumpstart your ML/DL project. The previous blog posts focused on image classification and hyperparameters optimization. In this blog post we will show how using Torchaudio and ClearML enables simple and efficient audio classification.
Audio Classification with Convolutional Neural Networks
In recent years, Convolutional Neural Networks (CNNs) have proven very effective in image classification tasks, which gave rise to the design of various architectures, such as Inception, ResNet, ResNext, Mobilenet and more. These CNNs achieve state of the art results on image classification tasks and offer a variety of ready to use pre trained backbones. As such, if we will be able to transfer audio classification tasks into the image domain, we will be able to leverage this rich variety of backbones for our needs.
As mentioned before, instead of directly using the sound file as an amplitude vs time signal we wish to convert the audio signal into an image. The following preprocessing was done using this script on the YesNo dataset that is included in torchaudio built-in datasets .
As a first stage of preprocessing we will:
- Read the audio file – using torchaudio
- Resample the audio signal to a fixed sample rate – This will make sure that all signals we will use will have the same sample rate. Theoretically the maximum frequency that can be represented by a sampled signal is a little bit less than half the sample rate (known as the Nyquist frequency). As 20 kHz is the highest frequency generally audible by humans, sampling rate of 44100 Hz is considered the most popular choice. However, in many cases removing the higher frequencies is considered plausible for the sake of reducing the amount of data per audio file. As such, the sampling rate of 20050 Hz has been reasonably popular for low bitrate MP3 files. In our example we will use this sample rate.
- Create a mono audio signal – For simplicity, we will make sure all signals we use will have the same number of channels.
The code for such preprocessing, looks like this:
yesno_data = torchaudio.datasets.YESNO('./data', download=True)
number_of_samples = 3
fixed_sample_rate = 22050
for n in range(number_of_smaples):
audio, sample_rate, labels = yesno_data[n]
resample_transform = torchaudio.transforms.Resample(
orig_freq=sample_rate, new_freq=fixed_sample_rate)
audio_mono = torch.mean(resample_transform(audio),
dim=0, keepdim=True)
plt.figure()
plt.plot(audio_mono[0,:])
The resulted matplotlib plots looks like this:
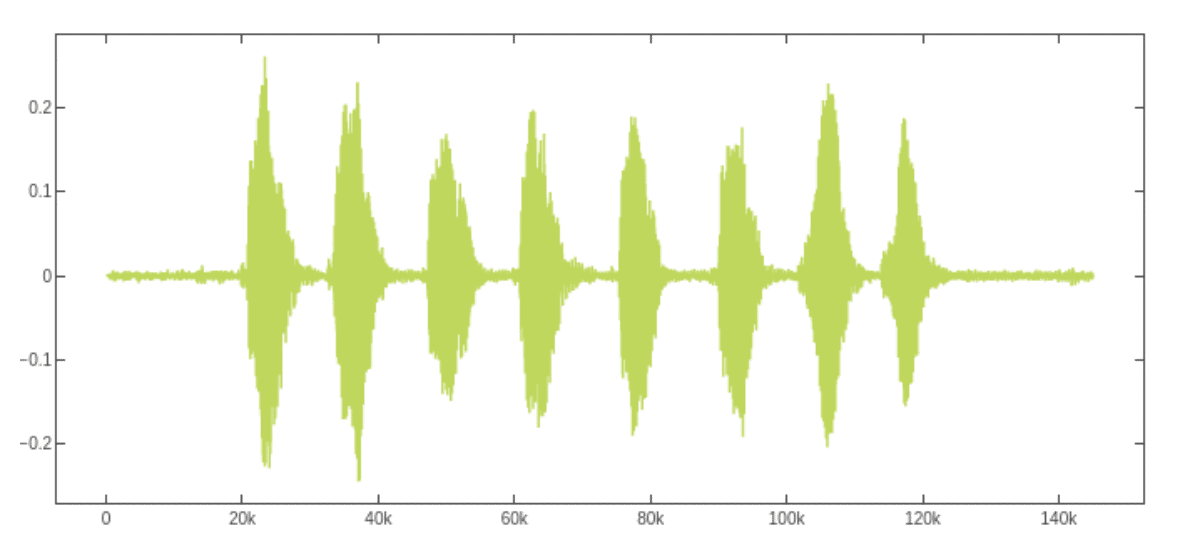
Now it is time to transform this time-series signal into the image domain. We will do that by converting it into a spectogram, which is a visual representation of the spectrum of frequencies of a signal as it varies with time. For that purpose we will use a log-scaled mel-spectrogram. A mel spectrogram is a spectrogram where the frequencies are converted to the mel scale, which takes into account the fact that humans are better at detecting differences in lower frequencies than higher frequencies. The mel scale converts the frequencies so that equal distances in pitch sounded equally distant to a human listener.
So let’s use torchaudio transforms and add the following lines to our snippet:
melspectogram_transform =
torchaudio.transforms.MelSpectrogram(
sample_rate=fixed_sample_rate, n_mels=128)
melspectogram_db_transform = torchaudio.transforms.AmplitudeToDB()
melspectogram = melspectogram_transform(audio_mono)
plt.figure()
plt.imshow(melspectogram.squeeze().numpy(), cmap='hot')
melspectogram_db=melspectogram_db_transform(melspectogram)
plt.figure()
plt.imshow(melspectogram_db.squeeze().numpy(), cmap='hot')
Now the audio file is represented as a two dimensional spectrogram image:
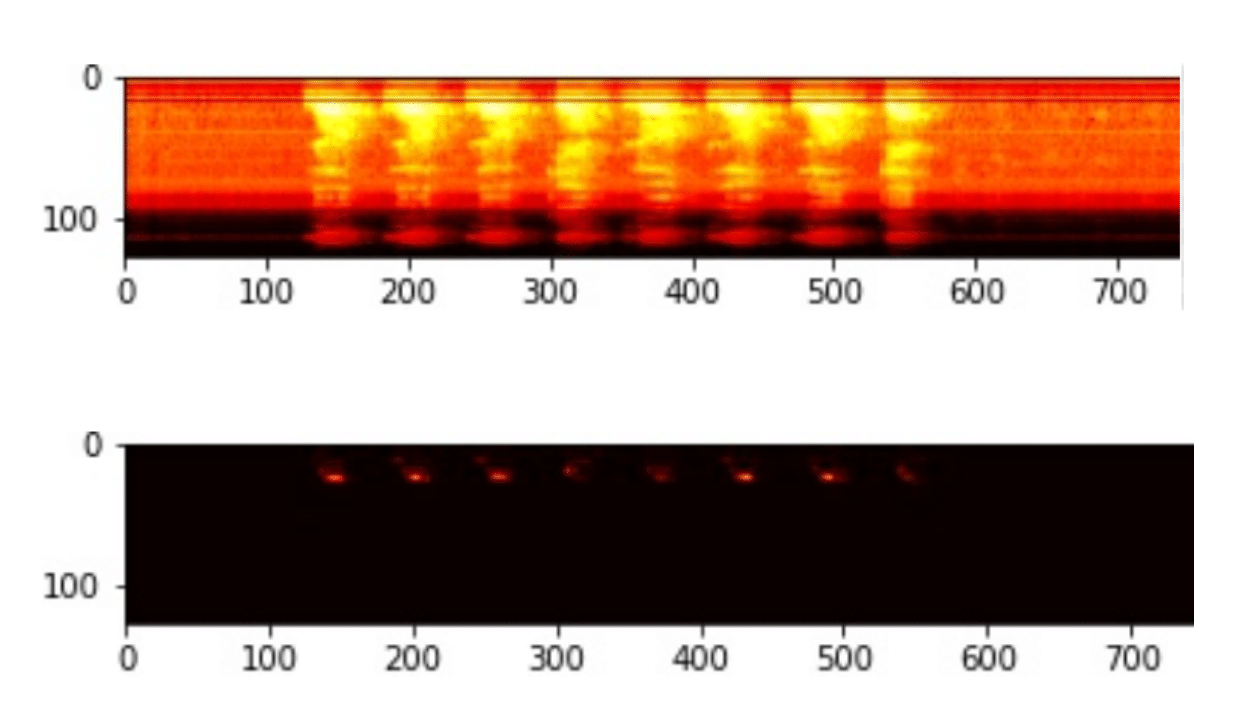
That’s exactly what we wanted to achieve. The Audio-classification problem is now transformed into an image classification problem.
Using ClearML, torchaudio and torchvision for audio classification
Pytorch’s ecosystem includes a variety of open source tools that can jump start our audio classification project and help us manage and support it. In this blog we will use three of these tools:
- ClearML is an open-source machine learning and deep learning experiment manager and MLOps solution. It boosts the effectiveness and productivity of AI teams as well as on-prem and cloud GPU utilization. ClearML helps researchers and developers to manage complex machine learning projects with zero integration effort.
- Torchaudio is a package consisting of I/O function, popular datasets and common audio transformations.
- Torchvision is a package consisting of popular datasets, model architectures, and common image transformations for computer vision.
For simplification, we will not explain in this blog how to install a ClearML-server. Therefore, the experiment will be logged on the ClearML demo server. For further information on how to deploy a self-hosted ClearML server, see the ClearML documentation.
For the purpose of this blog we will use the UrbanSound8K dataset that contains 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes, including dog barks, siren and street music. We will use a pretrained ResNet model to classify these audio files.
We will start by initializing ClearML to track everything we do:
from ClearML import Task
task = Task.init(project_name='Audio Classification',
task_name='UrbanSound8K classification example')
Next we will make sure there are no “magic numbers” hidden in the code and that all the script parameters are reflected in the experiment manager web app. When writing a python script, you can use the popular argparse package and ClearML will automatically pick it up. As we are writing a Jupyter notebook example we will define a configuration dictionary and connect it to the ClearML task object:
configuration_dict = {'number_of_epochs': 6, 'batch_size': 8,
'dropout': 0.25, 'base_lr': 0.005,
'number_of_mel_filters': 64, 'resample_freq': 22050}
configuration_dict = task.connect(configuration_dict)
Now it is time to define our PyTorch Dataset object. This object should include data loading as well as data preprocessing. The loading of the dataset’s metadata is done in the constructor of the class and is configured based on the UrbanSound8K dataset structure. Therefore, it will look as follows:
class UrbanSoundDataset(Dataset):
def __init__(self, csv_path, file_path, folderList, resample_freq=0):
self.file_path = file_path
self.file_names = []
self.labels = []
self.folders = []
self.n_mels = configuration_dict.get(number_of_mel_filters, 64)
self.resample = resample_freq
#loop through the csv files and only add those from the folder list
csvData = pd.read_csv(csv_path)
for i in range(0,len(csvData)):
if csvData.iloc[i, 5] in folderList:
self.file_names.append(csvData.iloc[i, 0])
self.labels.append(csvData.iloc[i, 6])
self.folders.append(csvData.iloc[i, 5])
The next thing we will do is define the __getitem__ method of the Dataset class. As explained before we want this part to perform several preprocessing steps:
- Load the audio file
- Resample it to a preconfigured sample rate – Note that this is done here for simplicity. Resampling an audio file is a time consuming function that will significantly slow down the training and will result in decreased GPU utilization. It is advisable to perform this preprocessing function for all files prior to the training cycles.
- Transform it to a one channel audio signal
- Convert it to a Mel spectrogram signal
In addition to the above, we want all transformed signals to have the same shape. Therefore, we will clip all Mel spectrograms to a preconfigured length and zero pad spectrograms shorter than this length. The result should look like this:
def __getitem__(self, index):
#format the file path and load the file
path = self.file_path / ("fold" + str(self.folders[index])) /
self.file_names[index]
soundData, sample_rate = torchaudio.load(path, out = None,
normalization = True)
if self.resample > 0:
resample_transform = torchaudio.transforms.Resample(
orig_freq=sample_rate, new_freq=self.resample)
soundData = resample_transform(soundData)
# This will convert audio files with two channels into one
soundData = torch.mean(soundData, dim=0, keepdim=True)
# Convert audio to log-scale Mel spectrogram
melspectrogram_transform = torchaudio.transforms.MelSpectrogram(
sample_rate=self.resample, n_mels=self.n_mels)
melspectrogram = melspectrogram_transform(soundData)
melspectogram_db =
torchaudio.transforms.AmplitudeToDB()(melspectrogram)
#Make sure all spectrograms are the same size
fixed_length = 3 * (self.resample//200)
if melspectogram_db.shape[2] < fixed_length:
melspectogram_db = torch.nn.functional.pad(melspectogram_db,
(0, fixed_length - melspectogram_db.shape[2]))
else:
melspectogram_db = melspectogram_db[:, :, :fixed_length]
return soundData, self.resample, melspectogram_db, self.labels[index]
Now comes the best part. As we have converted the problem from the audio domain to the image domain, we don’t need to worry about defining a model. We can use one of the built-in models that come with Torchvision. We decided to choose the effective and robust ResNet model. As the dataset is small and we want to mitigate the risk for overfitting, we will use the small but effective ResNet18 model. In addition to this great shortcut we just took, Torchvision enables us to load a model pretrained on Imagenet, so the training will be shorter and more effective.
All we need to do is adapt the input layer and output layer of the model to our data. This can be done easily as follows:
model = models.resnet18(pretrained=True)
model.conv1=nn.Conv2d(1, model.conv1.out_channels,
kernel_size=model.conv1.kernel_size[0],
stride=model.conv1.stride[0],
padding=model.conv1.padding[0])
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(classes))
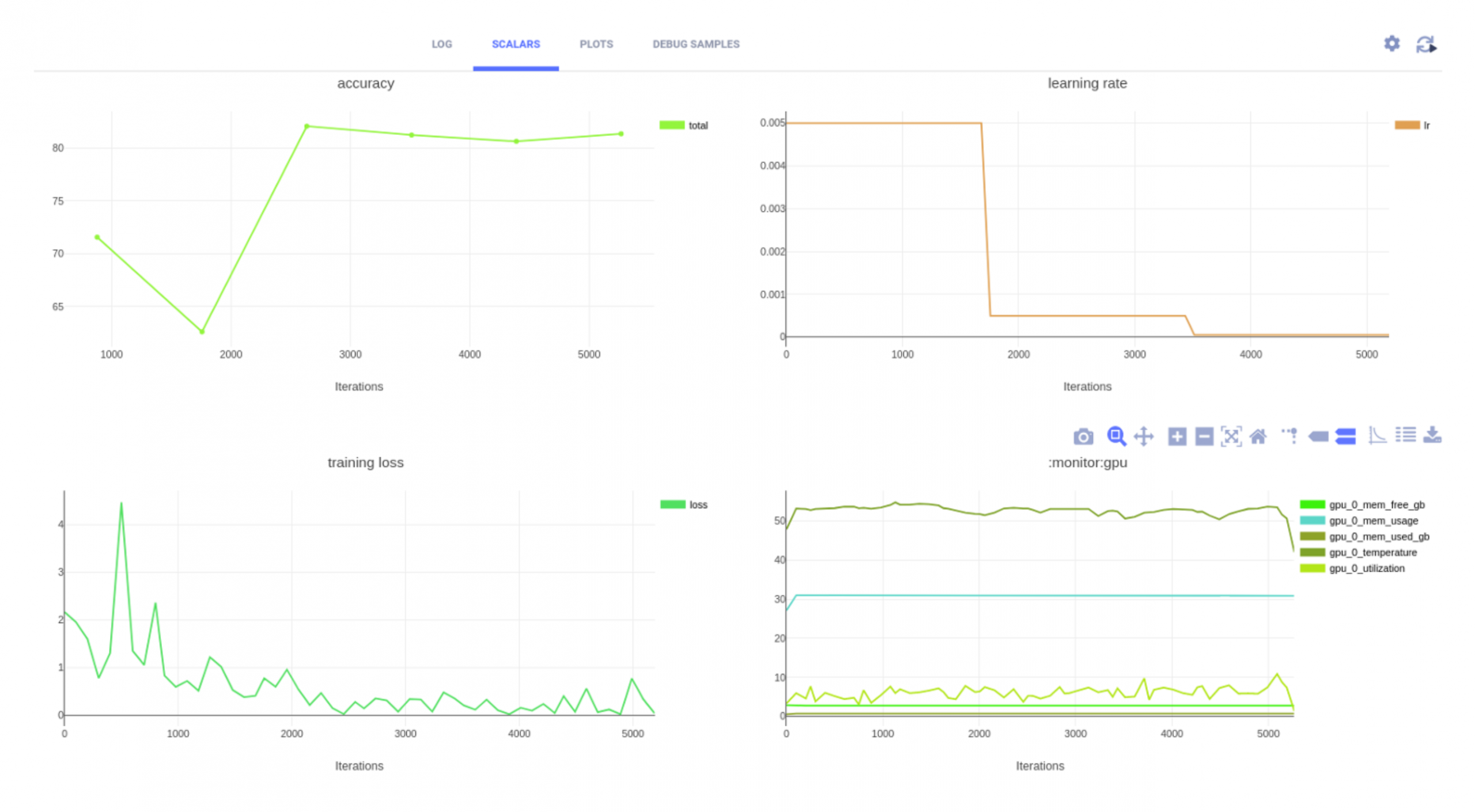
That’s it! We can start training our model. In this blog we will not go over the structure of the training and evaluation loops. They are pretty simple and straightforward – you can look them up in the full notebook. We will just note that during training and evaluation we make sure to report the audio signals, the scalars (loss, accuracy) and the spectrograms to the PyTorch’s built-in TensorBoard class, for debug purposes. ClearMLwill automatically pick up all the reports sent to TensorBoard and will log them under your experiment in the web app.
All we have got left to do is to execute our Jupyter notebook, either locally or on a remote machine using ClearML Agent and watch the progress of our training on ClearML’ web app.
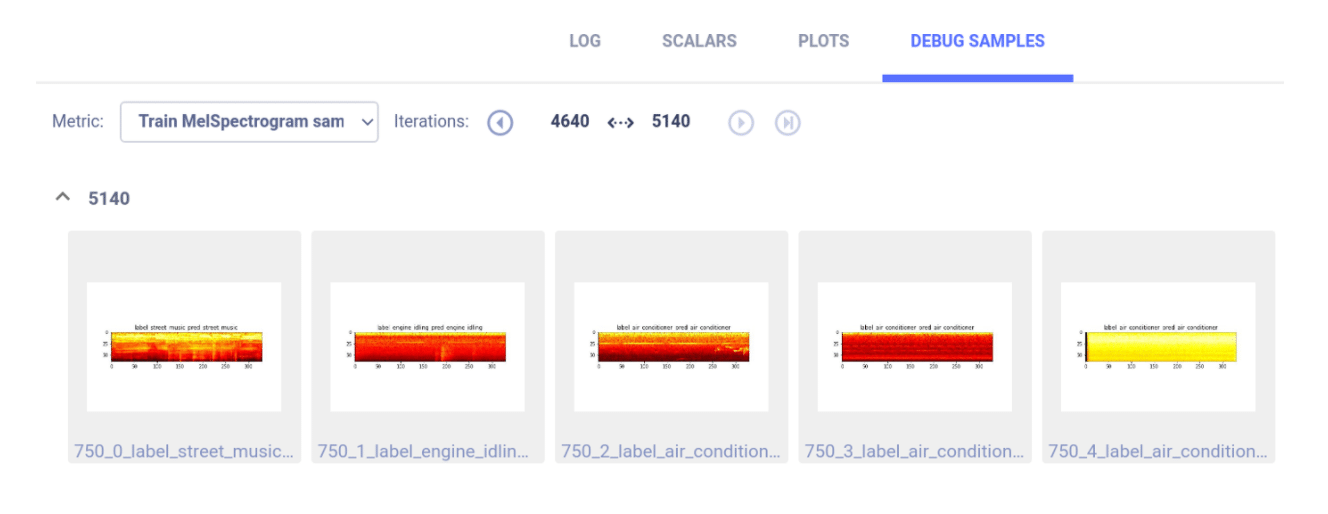
As we made sure we report debug data every few iterations, we can check out the debug samples section in the ClearML webapp and make sure that the data being fed into the model makes sense. We can either listen to the original audio signals or examine the spectrograms:
Summary
Automatic audio classification is a growing area of research that includes fields such as speech, music and environmental sounds. This rising field can benefit greatly from the rich experience and various tools developed for computer vision tasks. As such, leveraging the PyTorch ecosystem open source tools, can boost your audio classification machine learning project. Not only can you enjoy a set of free open source productivity tools, you can also use the robust and proven set of pretrained computer vision models, by transforming your signals from the time domain to the frequency domain.
In this tutorial we demonstrated the use of Tochaudio, Torchvision and ClearML for a simple and effective audio classification task. With zero integration efforts and no cost, you get a versatile training and evaluation script. To learn more, reference the ClearML’ documentation, torchaudio documentation and torchvision documentation.
In the next blog post of this series we will demonstrate how to easily create a machine learning pipeline, using the PyTorch ecosystem. This is highly effective for cases where we have a repeating sequence of tasks. For example, preprocessing and training, as we mentioned in the beginning of this blog post.